Hadoop 2.7 伪分布式环境搭建
1、安装环境
①、一台Linux CentOS6.7 系统
hostname ipaddress subnet mask geteway
Node1 192.168.139.150 255.255.255.0 192.168.139.2
②、hadoop 2.7 安装包
百度云下载链接:http://pan.baidu.com/s/1gfaKpA7密码:3cl7
2、安装 JDK
教程:http://www.cnblogs.com/ysocean/p/6952166.html
3、配置本机 ssh 免密码登录
教程:http://www.cnblogs.com/ysocean/p/6959776.html
上面教程是配置多台机器 ssh 免秘钥登录的配置。那么本机配置的话。输入如下命令即可:
ssh-keygen -t rsa -P ''
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
完成之后,以 root 用户登录,修改 ssh 配置文件
vi /etc/ssh/sshd_config
把文件中的下面几条信息的注释去掉:
RSAAuthentication yes # 启用 RSA 认证
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile .ssh/authorized_keys # 公钥文件路径(和上面生成的文件同)
然后重启服务
service sshd restart
验证出现如下界面,中间不需要输入密码,即配置完成。

4、安装 hadoop-2.7.3.tar.gz
①、将下载的 hadoop-2.7.3.tar.gz 复制到 /home/hadoop 目录下(可以利用工具 WinSCP)
②、解压,进入/home/hadoop 目录下,输入下面命令
tar -zxvf hadoop-2.7.3.tar.gz
③、给 hadoop-2.7.3文件夹重命名,以便后面引用
mv hadoop-2.7.3 hadoop2.7
④、删掉压缩文件 hadoop-2.7.3.tar.gz,并在/home/hadoop 目录下新建文件夹 tmp
mv hadoop-2.7.3 hadoop2.7
⑤、配置 hadoop 的环境变量(注意要使用 root 用户登录)
vi /etc/profile
输入如下信息:

然后输入如下命令保存生效:
source /etc/profile
⑥、验证
在任意目录下,输入 hadoop,出现如下信息即配置成功

5、修改配置文件
①、/home/hadoop/hadoop-2.7.0/etc/hadoop目录下hadoop-env.sh
输入命令

修改 hadoop-env.sh 的 JAVA_HOME 值

②、/home/hadoop/hadoop2.7/etc/hadoop目录下的core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.139.150:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
</configuration>
③、/home/hadoop/hadoop-2.7.0/etc/hadoop目录下的hdfs-site.xml

<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
到此我们便配置完成一个 hdfs 伪分布式环境
启动 hdfs Single Node
①、初始化 hdfs 文件系统
bin/hdfs namenode -format
②、启动 hdfs
sbin/start-dfs.sh
③、输入 jps 应该会有如下信息显示,则启动成功
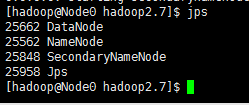
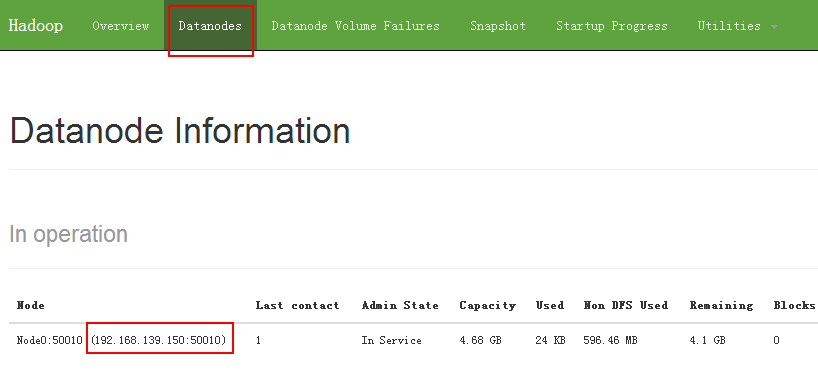
那么我们就可以 通过 http://192.168.139.150:50070 来访问 NameNode

我们点开 Datanodes ,发现就一个 datanode ,而且 IP 是 NameNode 的
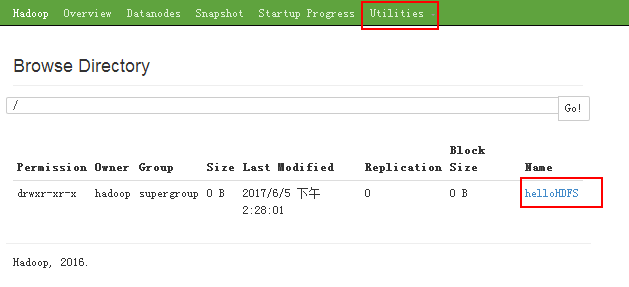
我们使用命令创建一个文件

那么在网页上我们就能看到这个文件
④、关闭 hdfs
sbin/stop-dfs.sh
Hadoop 2.7 伪分布式环境搭建的更多相关文章
- Hadoop学习2—伪分布式环境搭建
一.准备虚拟环境 1. 虚拟环境网络设置 A.安装VMware软件并安装linux环境,本人安装的是CentOS B.安装好虚拟机后,打开网络和共享中心 -> 更改适配器设置 -> 右键V ...
- Hadoop学习笔记1:伪分布式环境搭建
在搭建Hadoop环境之前,请先阅读如下博文,把搭建Hadoop环境之前的准备工作做好,博文如下: 1.CentOS 6.7下安装JDK , 地址: http://blog.csdn.net/yule ...
- 【Hadoop】伪分布式环境搭建、验证
Hadoop伪分布式环境搭建: 自动部署脚本: #!/bin/bash set -eux export APP_PATH=/opt/applications export APP_NAME=Ares ...
- 大数据:Hadoop(JDK安装、HDFS伪分布式环境搭建、HDFS 的shell操作)
所有的内容都来源与 Hadoop 官方文档 一.Hadoop 伪分布式安装步骤 1)JDK安装 解压:tar -zxvf jdk-7u79-linux-x64.tar.gz -C ~/app 添加到系 ...
- 【Hadoop离线基础总结】CDH版本Hadoop 伪分布式环境搭建
CDH版本Hadoop 伪分布式环境搭建 服务规划 步骤 第一步:上传压缩包并解压 cd /export/softwares/ tar -zxvf hadoop-2.6.0-cdh5.14.0.tar ...
- CentOS7下Hadoop伪分布式环境搭建
CentOS7下Hadoop伪分布式环境搭建 前期准备 1.配置hostname(可选,了解) 在CentOS中,有三种定义的主机名:静态的(static),瞬态的(transient),和灵活的(p ...
- Hadoop2.5.0伪分布式环境搭建
本章主要介绍下在Linux系统下的Hadoop2.5.0伪分布式环境搭建步骤.首先要搭建Hadoop伪分布式环境,需要完成一些前置依赖工作,包括创建用户.安装JDK.关闭防火墙等. 一.创建hadoo ...
- hive-2.2.0 伪分布式环境搭建
一,实验环境: 1, ubuntu server 16.04 2, jdk,1.8 3, hadoop 2.7.4 伪分布式环境或者集群模式 4, apache-hive-2.2.0-bin.tar. ...
- HDFS 伪分布式环境搭建
HDFS 伪分布式环境搭建 作者:Grey 原文地址: 博客园:HDFS 伪分布式环境搭建 CSDN:HDFS 伪分布式环境搭建 相关软件版本 Hadoop 2.6.5 CentOS 7 Oracle ...
随机推荐
- [Git]03 如何查看提交历史
在提交了若干更新之后,又或者克隆了某个项目,想回顾下提交历史,可以使用 gitlog 命令查看. 常用命令 1.查看提交历史 $ git log 2.查看某个文件或者某个目录的递交历史 $ gi ...
- (知识点)JavaScript继承
1)原型链 ①原型链示例 function Shape() { this.name = 'shape'; this.toString = function(){ return this.name; } ...
- 【算法系列学习】[kuangbin带你飞]专题十二 基础DP1 F - Piggy-Bank 【完全背包问题】
https://vjudge.net/contest/68966#problem/F http://blog.csdn.net/libin56842/article/details/9048173 # ...
- C++ 元编程 —— 让编译器帮你写程序
目录 1 C++ 中的元编程 1.1 什么是元编程 1.2 元编程在 C++ 中的位置 1.3 C++ 元编程的历史 2 元编程的语言支持 2.1 C++ 中的模板类型 2.2 C++ 中的模板参数 ...
- C#之lambda表达式
从C#3.0开始,可以使用lambda表达式把实现代码赋予委托.lambda表达式与委托(http://www.cnblogs.com/afei-24/p/6762442.html)直接相关.当参数是 ...
- Yii框架后续
关于Yii框架遗留的知识点. 1.url路由方式 (1).问号传参(默认) eg: http://localhost/项目/app/index.php http://localhost/项目/app/ ...
- maven私服nexus搭建(windows)
1.下载nexus 地址:https://www.sonatype.com/download-oss-sonatype 下载相应版本的zip包. 2.安装nexus 下载完成后,解压到本地任意目录. ...
- C语言中,隐藏结构体的细节
我们都知道,在C语言中,结构体中的字段都是可以访问的.或者说,在C++ 中,类和结构体的主要区别就是类中成员变量默认为private,而结构体中默认为public.结构体的这一个特性,导致结构体中封装 ...
- Error:Android Source Generator: [sdk] Android SDK is not specified.
有时候使用intellij idea 带入android 项目,运行提示Error:Android Source Generator: [sdk] Android SDK is not specifi ...
- bash shell中测试命令
bash shell中测试命令 test命令提供了if-than语句中测试不同条件的途径.如果test命令中列出的条件成立,test命令就会退出并返回退出状态吗0 .这样if-than语句就与其他编程 ...