自动化运维工具——puppet详解(一)
一、puppet 介绍
1、puppet是什么
puppet是一个IT基础设施自动化管理工具,它能够帮助系统管理员管理基础设施的整个生命周期: 供应(provisioning)、配置(configuration)、联动(orchestration)及报告(reporting)。
基于puppet ,可实现自动化重复任务、快速部署关键性应用以及在本地或云端完成主动管理变更和快速扩展架构规模等。
遵循GPL 协议(2.7.0-), 基于ruby语言开发。
2.7.0 以后使用(Apache 2.0 license)
对于系统管理员是抽象的,只依赖于ruby与facter。
能管理多达40 多种资源,例如:file、user、group、host、package、service、cron、exec、yum repo等。
2、puppet的工作机制
1)工作模型
puppet 通过声明性、基于模型的方法进行IT自动化管理。
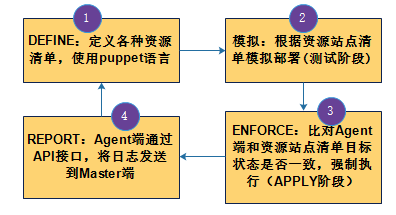
定义:通过puppet 的声明性配置语言定义基础设置配置的目标状态;
模拟:强制应用改变的配置之前先进行模拟性应用;
强制:自动、强制部署达成目标状态,纠正任何偏离的配置;
报告:报告当下状态及目标状态的不同,以及达成目标状态所进行的任何强制性改变;
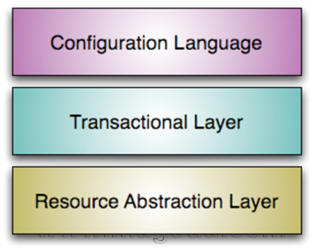
puppet三层模型
puppet三层模型如下:
2)工作流程
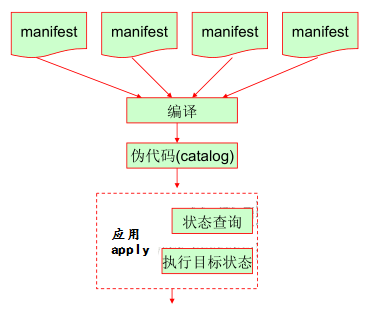
3)使用模型
puppet的使用模型分为单机使用模型和master/agent模型,下面我们来看看这两个模型的原理图。
单机使用模型
实现定义多个manifests --> complier --> catalog --> apply
master/agent模型
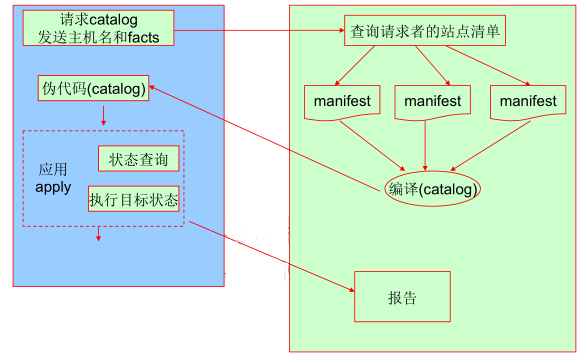
master/agent模型实现的是集中式管理,即 agent 端周期性向 master 端发起请求,请求自己需要的数据。然后在自己的机器上运行,并将结果返回给 master 端。
架构和工作原理如下:
架构
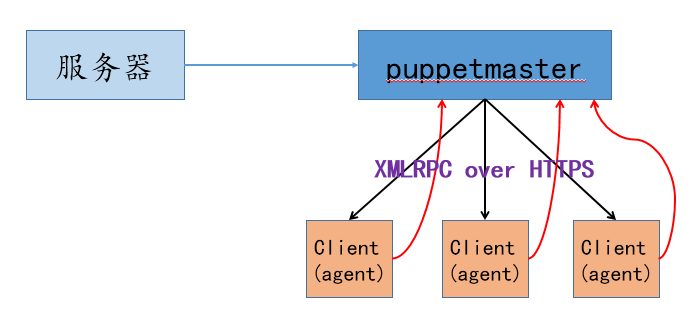
工作原理
3、puppet 名词解释
- 资源:是puppet的核心,通过资源申报,定义在资源清单中。相当于
ansible中的模块,只是抽象的更加彻底。 - 类:一组资源清单。
- 模块:包含多个类。相当于
ansible中的角色。 - 站点清单:以主机为核心,应用哪些模块。
二、puppet 资源详解
接下来,我们就以单机模式来具体介绍一下puppet的各个部分。
1、程序安装及环境
首先,我们还是来安装一下puppet,puppet的安装可以使用源码安装,也可以使用rpm(官方提供)、epel源、官方提供的yum仓库来安装(通过下载官方提供的rpm包可以指定官方的yum仓库)。
在这里,我们就是用 yum 安装的方式。
yum install -y puppet
安装完成过后,我们可以通过rpm -ql puppet | less来查看一下包中都有一些什么文件。
其中主配置文件为/etc/puppet/puppet.conf,使用的主程序为/usr/bin/puppet。
2、puppet 资源简介
1)资源抽象
puppet 从以下三个维度来对资源完成抽象:
- 相似的资源被抽象成同一种资源**“类型”** ,如程序包资源、用户资源及服务资源等;
- 将资源属性或状态的描述与其实现方式剥离开来,如仅说明安装一个程序包而不用关心其具体是通过yum、pkgadd、ports或是其它方式实现;
- 仅描述资源的目标状态,也即期望其实现的结果,而不是其具体过程,如“确定nginx 运行起来” 而不是具体描述为“运行nginx命令将其启动起来”;
这三个也被称作puppet 的资源抽象层(RAL)
RAL 由type( 类型) 和provider( 提供者,即不同OS 上的特定实现)组成。
2)资源定义
资源定义通过向资源类型的属性赋值来实现,可称为资源类型实例化;
定义了资源实例的文件即清单,manifest;
定义资源的语法如下:
type {'title':
attribute1 => value1,
atrribute2 => value2,
……
}
注意:type必须使用小写字符;title是一个字符串,在同一类型中必须惟一;每一个属性之间需要用“,”隔开,最后一个“,”可省略。
例如,可以同时有名为nginx 的“service”资源和“package”资源,但在“package” 类型的资源中只能有一个名为“nginx”的资源。
3)资源属性中的三个特殊属性:
Namevar:可简称为name;ensure:资源的目标状态;Provider:指明资源的管理接口;
3、常用资源总结
1)查看资源
我们可以使用puppet describe来打印有关Puppet资源类型,提供者和元参数的帮助。使用语法如下:
puppet describe [-h|--help] [-s|--short] [-p|--providers] [-l|--list] [-m|--meta] [type]
-l:列出所有资源类型;
-s:显示指定类型的简要帮助信息;
-m:显示指定类型的元参数,一般与-s一同使用;
2)group:管理系统上的用户组。
查看使用帮助信息:
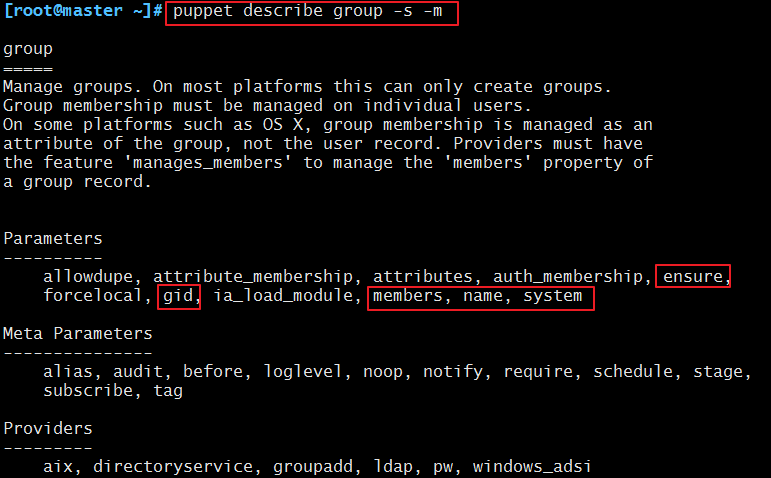
属性:
name:组名,可以省略,如果省略,将继承title的值;
gid:GID;
system:是否为系统组,true OR false;
ensure:目标状态,present/absent;
members:成员用户;
简单举例如下:
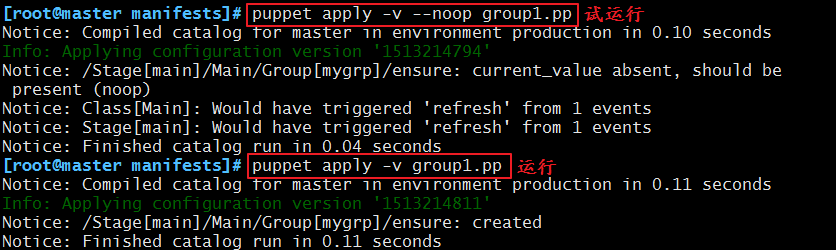
vim group.pp
group{'mygrp':
name => 'mygrp',
ensure => present,
gid => 2000,
}
我们可以来运行一下:
3)user:管理系统上的用户。
查看使用帮助信息:
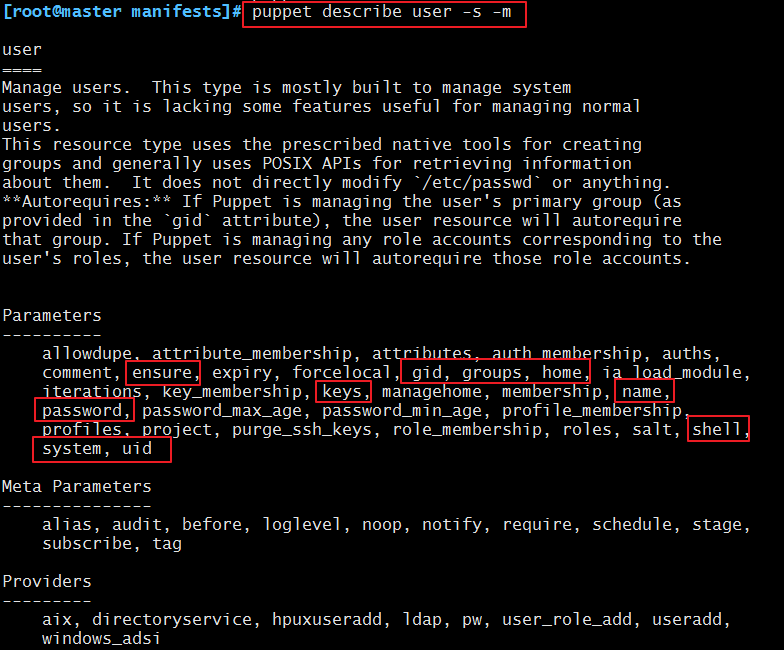
属性:
name:用户名,可以省略,如果省略,将继承title的值;
uid: UID;
gid:基本组ID;
groups:附加组,不能包含基本组;
comment:注释;
expiry:过期时间 ;
home:用户的家目录;
shell:默认shell类型;
system:是否为系统用户 ;
ensure:present/absent;
password:加密后的密码串;
简单举例如下:
vim user1.pp
user{'keerr':
ensure => present,
system => false,
comment => 'Test User',
shell => '/bin/tcsh',
home => '/data/keerr',
managehome => true,
groups => 'mygrp',
uid => 3000,
}
4)package:puppet的管理软件包。
查看使用帮助信息:
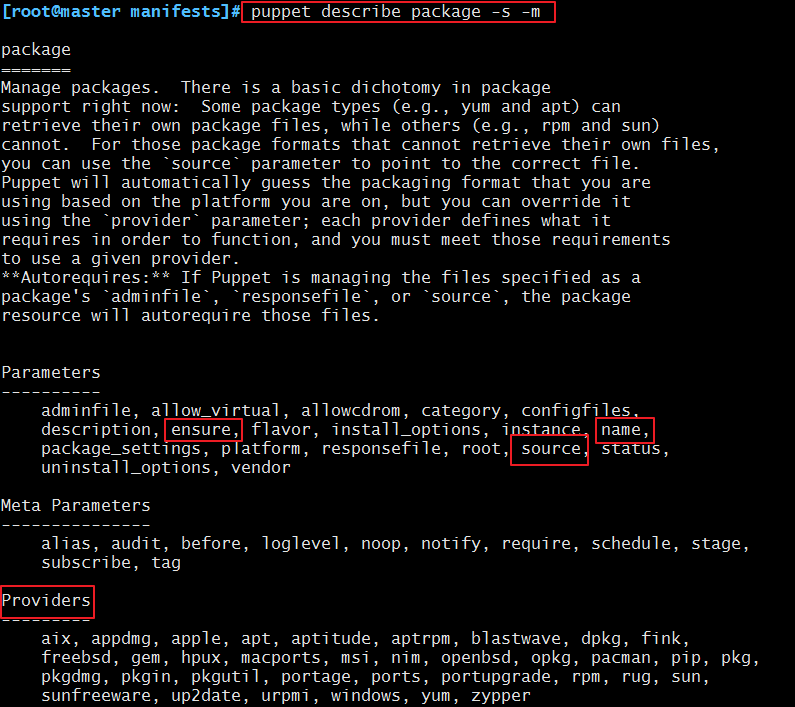
属性:
ensure:installed, present, latest, absent, any version string (implies present)
name:包名,可以省略,如果省略,将继承title的值;
source:程序包来源,仅对不会自动下载相关程序包的provider有用,例如rpm或dpkg;
provider:指明安装方式;
简单举例如下:
vim package1.pp
package{'nginx':
ensure => installed,
procider => yum
}
5)service:定义服务的状态
查看使用帮助信息:
puppet describe service -s -m
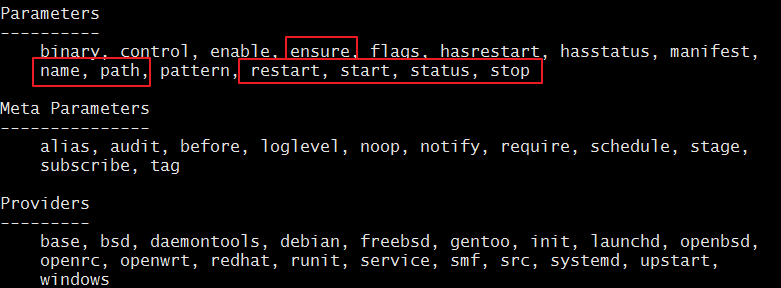
属性:
ensure:服务的目标状态,值有true(running)和false(stopped)
enable:是否开机自动启动,值有true和false
name:服务名称,可以省略,如果省略,将继承title的值
path:服务脚本路径,默认为/etc/init.d/下
start:定制启动命令
stop:定制关闭命令
restart:定制重启命令
status:定制状态
简单举例如下:
vim service1.pp
service{'nginx':
ensure => true,
enable => false
}
6)file:管理文件、目录、软链接
查看使用帮助信息:
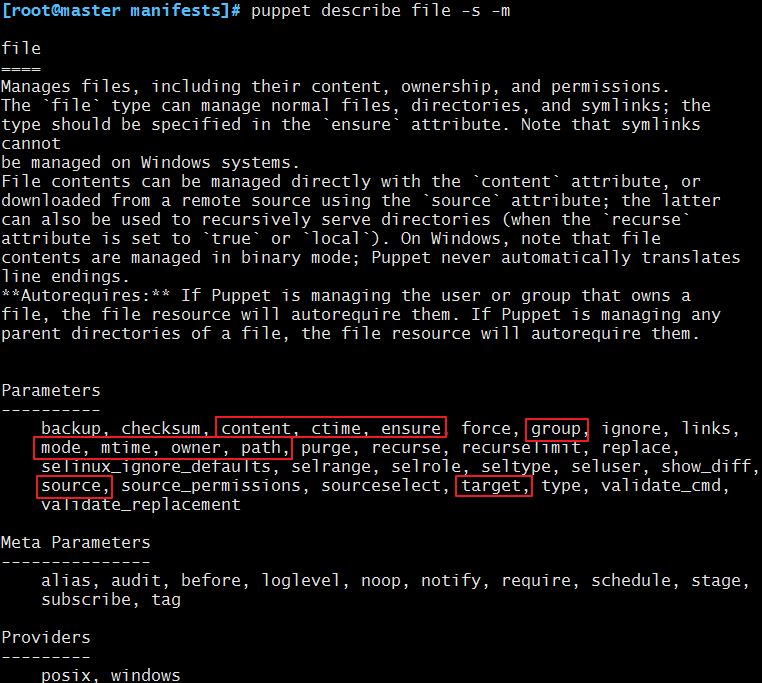
属性:
ensure:目标状态,值有absent,present,file,directory和link
file:类型为普通文件,其内容由content属性生成或复制由source属性指向的文件路径来创建;
link:类型为符号链接文件,必须由target属性指明其链接的目标文件;
directory:类型为目录,可通过source指向的路径复制生成,recurse属性指明是否递归复制;
path:文件路径;
source:源文件;
content:文件内容;
target:符号链接的目标文件;
owner:定义文件的属主;
group:定义文件的属组;
mode:定义文件的权限;
atime/ctime/mtime:时间戳;
简单举例如下:
vim file1.pp
file{'aaa':
path => '/data/aaa',
source => '/etc/aaa',
owner => 'keerr',
mode => '611',
}
7)exec:执行命令,慎用。通常用来执行外部命令
查看使用帮助信息:
puppet describe exec -s -m
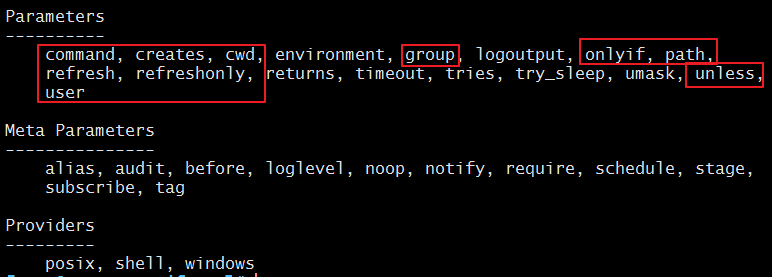
属性:
command(namevar):要运行的命令;
cwd:指定运行该命令的目录;
creates:文件路径,仅此路径表示的文件不存在时,command方才执行;
user/group:运行命令的用户身份;
path:指定命令执行的搜索路径;
onlyif:此属性指定一个命令,此命令正常(退出码为0)运行时,当前command才会运行;
unless:此属性指定一个命令,此命令非正常(退出码为非0)运行时,当前command才会运行;
refresh:重新执行当前command的替代命令;
refreshonly:仅接收到订阅的资源的通知时方才运行;
简单举例如下:
vim exec1.pp
exec{'cmd':
command => 'mkdir /data/testdir',
path => ['/bin','/sbin','/usr/bin','/usr/sbin'],
# path => '/bin:/sbin:/usr/bin:/usr/sbin',
}
8)cron:定义周期性任务
查看使用帮助信息:

属性:
command:要执行的任务(命令或脚本);
ensure:目标状态,present/absent;
hour:时;
minute:分;
monthday:日;
month:月;
weekday:周;
user:以哪个用户的身份运行命令(默认为root);
target:添加为哪个用户的任务;
name:cron job的名称;
简单举例如下:
vim cron1.pp
cron{'timesync':
command => '/usr/sbin/ntpdata 172.16.0.1',
ensure => present,
minute => '*/3',
user => 'root',
}
我们可以运行一下,查看我们的crontab,来看看该任务是否已经被添加:
[root@master manifests]# puppet apply -v --noop cron1.pp #试运行
[root@master manifests]# puppet apply -v cron1.pp #运行
[root@master manifests]# crontab -l #查看计划任务
# HEADER: This file was autogenerated at 2017-12-14 15:05:05 +0800 by puppet.
# HEADER: While it can still be managed manually, it is definitely not recommended.
# HEADER: Note particularly that the comments starting with 'Puppet Name' should
# HEADER: not be deleted, as doing so could cause duplicate cron jobs.
# Puppet Name: timesync
*/3 * * * * /usr/sbin/ntpdata 172.16.0.1
9)notify:调试输出
查看使用帮助信息:

属性:
message:记录的信息
name:信息名称
该选项一般用于master/agent模式中,来记录一些操作的时间,比如重新安装了一个程序呀,或者重启了应用等等。会直接输出到代理机的运行日志中。
以上,就是我们常见的8个资源。其余的资源我们可以使用puppet describe -l来列出,上文中也已经说过了~
4、资源的特殊属性
puppet中也提供了before、require、notify和subscribe四个参数来定义资源之间的依赖关系和通知关系。
before:表示需要依赖于某个资源
require:表示应该先执行本资源,在执行别的资源
notify:A notify B:B依赖于A,且A发生改变后会通知B;
subscribe:B subscribe A:B依赖于A,且B监控A资源的变化产生的事件;
同时,依赖关系还可以使用->和~>来表示:
-> 表示后资源需要依赖前资源
~> 表示前资源变动通知后资源调用
举例如下:
vim file.pp
file{'test.txt': #定义一个文件
path => '/data/test.txt',
ensure => file,
source => '/etc/fstab',
}
file{'test.symlink': #依赖文件建立超链接
path => '/data/test.symlink',
ensure => link,
target => '/data/test.txt',
require => File['test.txt'],
}
file{'test.dir': #定义一个目录
path => '/data/test.dir',
ensure => directory,
source => '/etc/yum.repo.d/',
recurse => true,
}
我们还可以使用在最下面统一写依赖关系的方式来定义:
vim redis.pp
package{'reids':
ensure => installed,
}
file{'/etc/redis.conf':
source => '/root/manifets/files/redis.conf',
ensure => file,
owner => redis,
group => root,
mode => '0640',
}
service{'redis':
ensure => running,
enable => true,
hasrestart => true,
}
Package['redis'] -> File['/etc/redis.conf'] -> Service['redis'] #定义依赖关系
tag 标签
如同 anssible 一样,puppet 也可以定义“标签”——tag,打了标签以后,我们在运行资源的时候就可以只运行某个打过标签的部分,而非全部。这样就更方便于我们的操作。
一个资源中,可以有一个tag也可以有多个。具体使用语法如下:
type{'title':
...
tag => 'TAG1',
}
type{'title':
...
tag => ['TAG1','TAG2',...],
}
调用时的语法如下:
puppet apply --tags TAG1,TAG2,... FILE.PP
实例
首先,我们去修改一下redis.pp文件,添加一个标签进去
vim redis.pp
package{'redis':
ensure => installed,
}
file{'/etc/redis.conf':
source => '/root/manifets/file/redis.conf',
ensure => file,
owner => redis,
group => root,
mode => '0640',
tag => 'instconf' #定义标签
}
service{'redis':
ensure => running,
enable => true,
hasrestart => true,
}
Package['redis'] -> File['/etc/redis.conf'] -> Service['redis']
然后,我们手动先开启redis服务:
systemctl start redis
现在,我们去修改一下file目录下的配置文件:
vim file/redis.conf
requirepass keerya
接着,我们就去运行redis.pp,我们的配置文件已经修改过了,现在想要实现的就是重启该服务,实现,需要使用密码keer登录:
puppet apply -v --tags instconf redis.pp

现在,我们就去登录一下redis看看是否生效:
redis-cli -a keerya

验证成功,实验完成。
5、puppet 变量
puppet 变量以“$”开头,赋值操作符为“=”,语法为$variable_name=value。
数据类型:
字符型:引号可有可无;但单引号为强引用,双引号为弱引用;支持转义符;
数值型:默认均识别为字符串,仅在数值上下文才以数值对待;
数组:[]中以逗号分隔元素列表;
布尔型值:true, false;不能加引号;
hash:{}中以逗号分隔k/v数据列表; 键为字符型,值为任意puppet支持的类型;{ ‘mon’ => ‘Monday’, ‘tue’ => ‘Tuesday’, };
undef:从未被声明的变量的值类型;
正则表达式:
(?<ENABLED OPTION>:<PATTERN>)
(?-<DISABLED OPTION>:<PATTERN>)
OPTIONS:
i:忽略字符大小写;
m:把.当换行符;
x:忽略<PATTERN>中的空白字符;
(?i-mx:PATTERN)
注意:不能赋值给变量,仅能用在接受=~或!~操作符的位置;
1)puppet的变量种类
puppet 种类有三种,为facts,内建变量和用户自定义变量。
facts:
由facter提供;top scope;
内建变量:
master端变量
$servername, $serverip, $serverversion
agent端变量
$clientcert, $clientversion, $environment
parser变量
$module_name
用户自定义变量
2)变量的作用域
不同的变量也有其不同的作用域。我们称之为Scope。
作用域有三种,top scope,node scope,class scope。
其生效范围排序为:top scope > node scope > class scope

其优先级排序为:top scope < node scope < class scope
6、puppet 流程控制语句
puppet 支持if 语句,case 语句和selector 语句。
1)if 语句
if语句支持单分支,双分支和多分支。具体语法如下:
单分支:
if CONDITION {
statement
……
}
双分支:
if CONDITION {
statement
……
}
else{
statement
……
}
多分支:
if CONDITION {
statement
……
}
elsif CONDITION{
statement
……
}
else{
statement
……
}
其中,CONDITION的给定方式有如下三种:
- 变量
- 比较表达式
- 有返回值的函数
举例
vim if.pp
if $operatingsystemmajrelease == '7' {
$db_pkg='mariadb-server'
}else{
$db_pkg='mysql-server'
}
package{"$db_pkg":
ensure => installed,
}
2)case 语句
类似 if 语句,case 语句会从多个代码块中选择一个分支执行,这跟其它编程语言中的 case 语句功能一致。
case 语句会接受一个控制表达式和一组 case 代码块,并执行第一个匹配到控制表达式的块。
使用语法如下:
case CONTROL_EXPRESSION {
case1: { ... }
case2: { ... }
case3: { ... }
……
default: { ... }
}
其中,CONTROL_EXPRESSION的给定方式有如下三种:
- 变量
- 表达式
- 有返回值的函数
各case的给定方式有如下五种:
- 直接字串;
- 变量
- 有返回值的函数
- 正则表达式模式;
- default
举例
vim case.pp
case $osfamily {
"RedHat": { $webserver='httpd' }
/(?i-mx:debian)/: { $webserver='apache2' }
default: { $webserver='httpd' }
}
package{"$webserver":
ensure => installed, before => [ File['httpd.conf'], Service['httpd'] ],
}
file{'httpd.conf':
path => '/etc/httpd/conf/httpd.conf',
source => '/root/manifests/httpd.conf',
ensure => file,
}
service{'httpd':
ensure => running,
enable => true, restart => 'systemctl restart httpd.service',
subscribe => File['httpd.conf'],
}
3)selector 语句
Selector 只能用于期望出现直接值(plain value) 的地方,这包括变量赋值、资源属性、函数参数、资源标题、其它 selector。
selector 不能用于一个已经嵌套于于selector 的case 中,也不能用于一个已经嵌套于case 的case 语句中。
具体语法如下:
CONTROL_VARIABLE ? {
case1 => value1,
case2 => value2,
...
default => valueN,
}
其中,CONTROL_EXPRESSION的给定方式有如下三种:
- 变量
- 表达式
- 有返回值的函数
各case的给定方式有如下五种:
- 直接子串;
- 变量;
- 有返回值的函数;
- 正则表达式模式;
- default
selectors 使用要点:
- 整个selector 语句会被当作一个单独的值,puppet 会将控制变量按列出的次序与每个case 进行比较,并在遇到一个匹配的 case 后,将其值作为整个语句的值进行返回,并忽略后面的其它 case。
- 控制变量与各 case 比较的方式与 case 语句相同,但如果没有任何一个 case 与控制变量匹配时,puppet 在编译时将会返回一个错误,因此,实践中,其必须提供default case。
- selector 的控制变量只能是变量或有返回值的函数,切记不能使用表达式。
- 其各 case 可以是直接值(需要加引号) 、变量、能调用返回值的函数、正则表达式模式或 default。
- 但与 case 语句所不同的是,selector 的各 case 不能使用列表。
- selector 的各 case 的值可以是一个除了 hash 以外的直接值、变量、能调用返回值的函数或其它的 selector。
举例
vim selector.pp
$pkgname = $operatingsystem ? {
/(?i-mx:(ubuntu|debian))/ => 'apache2',
/(?i-mx:(redhat|fedora|centos))/ => 'httpd',
default => 'httpd',
}
package{"$pkgname":
ensure => installed,
}
写在后面
以上,我们本次的介绍就告一段落,剩余的部分,请看下回分解。
自动化运维工具——puppet详解(一)的更多相关文章
- 企业级自动化运维工具---puppet详解
本文收录在Linux运维企业架构实战系列 1.认识puppet 1.1 引入 puppet是什么,咱们先不用专业的名词解释它,咱们先描述一些工作场景,看明白这些工作场景,自然会知道puppet是什么. ...
- 项目10.2-企业级自动化运维工具---puppet详解
1.认识puppet 1.1 引入 puppet是什么,咱们先不用专业的名词解释它,咱们先描述一些工作场景,看明白这些工作场景,自然会知道puppet是什么. (1)场景一: 管理员想要在100台服务 ...
- 自动化运维工具——puppet详解(二)
一.class 类 1)什么是类? 类是puppet中命名的代码模块,常用于定义一组通用目标的资源,可在puppet全局调用: 类可以被继承,也可以包含子类: 具体定义的语法如下: class NAM ...
- 自动化运维工具——ansile详解
自动化运维工具——ansible详解(一) 目录 ansible 简介 ansible 是什么? ansible 特点 ansible 架构图 ansible 任务执行 ansible 任务执行模式 ...
- 自动化运维工具——ansible详解(一)
ansible 简介 ansible 是什么? ansible是新出现的自动化运维工具,基于Python开发,集合了众多运维工具(puppet.chef.func.fabric)的优点,实现了批量系统 ...
- ansible自动化运维工具使用详解
一. ansible 简介 1. ansible ansible是新出现的 自动化 运维工具 , 基于Python研发 . 糅合了众多老牌运维工具的优点实现了批量操作系统配置.批量程序的部署.批量运行 ...
- 自动化运维工具——ansible详解(二)
Ansible playbook 简介 playbook 是 ansible 用于配置,部署,和管理被控节点的剧本. 通过 playbook 的详细描述,执行其中的一系列 tasks ,可以让远端主机 ...
- 自动化运维工具 ~puppet~
一.模板的应用 到目前为止,资源申报.定义类.声明类等所有功能都只能一个manifest文件中实现,但这却非有效的基于puppet管理IT资源架构的方式.实践 中,一般需要把manifest文件分解成 ...
- 自动化运维工具Ansible的部署步骤详解
本文来源于http://sofar.blog.51cto.com/353572/1579894,主要是看到这样一篇好文章,想留下来供各位同僚一起分享. 一.基础介绍 ================= ...
随机推荐
- 2015-2016 ACM-ICPC, NEERC, Southern Subregional Contest A Email Aliases(模拟STL vector+map)
Email AliasesCrawling in process... Crawling failed Time Limit:2000MS Memory Limit:524288KB ...
- 利用JavaScript实现动态显示表格且对应改变按键的value值
插入的代码并没有符合HTML5样式,只是为了实现利用JS动态显示表格,并且按键的value值会同时发生变化的功能. <!DOCTYPE > <html > <head&g ...
- jQuery选择器(内容过滤选择器)第四节
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/stri ...
- Spring AOP分析(3) -- CglibAopProxy实现AOP
上文探讨了应用JDK动态代理实现Spring AOP功能的方式,下面将继续探讨Spring AOP功能的另外一种实现方式 -- CGLIB. 首先,来看看类名CglibAopProxy,该类实现了两个 ...
- webapp通用选择器:iosselect
1,这个组件解决什么问题 在IOS系统中,safari浏览器的select标签默认展示样式和iOS-UIPickerView展示方式一致,形如下图: 这个选择器操作方便,样式优美.但是在安卓系统中展示 ...
- vue-cli 前端开发,后台接口跨域代理调试问题
使用 webpack的方式开发的时候,前台开发过程中需要调用很多后台的数据接口,但是通常前后台分离的开发方式,后台的接口数据很可能是不方便或者是不能在前端同学的电脑上运行的,也就出现了所谓的跨域问题. ...
- Scrum Meeting Alpha - 4
Scrum Meeting - NewTeam // 地点:新主楼F座二楼 任务反馈 团队成员 完成任务 计划任务 安万贺 确定了API部分的目录结构及包装方式,完成了部分API的包装https:// ...
- app.config 配置多项 配置集合 自定义配置
C#程序的配置文件,使用的最多的是appSettings 下的<add key="Interval" value="30"/>,这种配置单项的很方便 ...
- TensorFlow简易学习[1]:基本概念和操作示例
简介 TensorFlow是一个实现机器学习算法的接口,也是执行机器学习算法的框架.使用数据流式图规划计算流程,可以将计算映射到不同的硬件和操作系统平台. 主要概念 TensorFlow的计算可以表示 ...
- linux服务器上Apache配置多域名
一, 打开httpd.conf 二 找到如下三个位置配置如下 DocumentRoot "/data" #以下这个配置是紧挨着的,有两个 <Directory "/ ...