Hadoop1.0.3安装部署
0x00 大数据平台相关链接
官网:http://hadoop.apache.org/
主要参考教程:http://www.cnblogs.com/xia520pi/archive/2012/05/16/2503949.html
0x01 hadoop平台环境
操作系统:CentOS-6.5-x86_64
Java版本:jdk_1.8.0_111
Hadoop版本:hadoop-1.0.3
0x02 安装操作系统
2.1 准备安装镜像
CentOS-6.5-x86_64-bin-DVD1.iso
2.2 CentOS官方网站与文档
官网主页:http://www.centos.org/
官方WiKi:http://wiki.centos.org/
官方中文文档:http://wiki.centos.org/zh/Documentation
安装说明:http://www.centos.org/docs/
2.3 安装教程
http://www.cnblogs.com/xia520pi/archive/2012/05/16/2503770.html
2.4 建立一般用户
//新增用户
# useradd hadoop
//设置密码
# passwd 123456
2.5 关闭防火墙机SELinux
关闭防火墙
//临时关闭
# service iptables stop
//永久关闭
# chkconfig iptables off
# service ip6tables stop
# chkconfig ip6tables off

关闭SELinux
# vim /etc/sysconfig/selinux
SELINUX=enforcing
|
SELINUX=disable
接着执行如下命令,使更改生效。
# setenforce 0
# getenforce
0x03 hadoop安装
3.1 环境说明
| hostname | username | IP |
|---|---|---|
| master | hadoop | 192.168.1.10 |
| slave1 | hadoop | 192.168.1.11 |
| slave2 | hadoop | 192.168.1.12 |
3.2 网络配置
- 修改当前主机名
//查看当前主机名
# hostname
//修改当前主机名
vim /etc/sysconfig/network
NETWORKING 是否利用网络
GATEWAY 默认网关
IPGATEWAYDEV 默认网关的接口名
HOSTNAME 主机名
DOMAIN 域名
- 修改当前机器IP
# vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE 接口名(设备,网卡)
BOOTPROTO IP的配置方法(static:固定IP, dhcpHCP, none:手动)
HWADDR MAC地址
ONBOOT 系统启动的时候网络接口是否有效(yes/no)
TYPE 网络类型(通常是Ethemet)
NETMASK 网络掩码
IPADDR IP地址
IPV6INIT IPV6是否有效(yes/no)
GATEWAY 默认网关IP地址

- 配置`hosts'文件(必须)
# vim /etc/hosts
192.168.1.2 master
192.168.1.3 slave1
192.168.1.4 slave2
3.3 SSH无密钥验证配置
- SSH无密钥原理
Master(NameNode | JobTracker)作为客户端,要实现无密码公钥认证,连接到服务器Salve(DataNode | Tasktracker)上时,需要在Master上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到所有的Slave上。当Master通过SSH连接Salve时,Salve就会生成一个随机数并用Master的公钥对随机数进行加密,并发送给Master。Master收到加密数之后再用私钥解密,并将解密数回传给Slave,Slave确认解密数无误之后就允许Master进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。重要过程是将客户端Master复制到Slave上。
- 配置master和slave互相无密钥登录
所有密钥都是hadoop用户的公钥和私钥,即以hadoop用户的身份来执行生成密钥的命令。
$ ssh-keygen –t rsa
这条命令是生成其无密码密钥对,询问其保存路径时直接回车采用默认路径。生成的密钥对:id_rsa和id_rsa.pub,默认存储在/home/hadoop/.ssh目录下。
在所有slave节点执行该命令生成其密钥对。
将所有slave节点的公钥上传到master节点
$ scp ~/.ssh/id_rsa.pub hadoop@master:~/.ssh/slave1_id_rsa.pub
$ scp ~/.ssh/id_rsa.pub hadoop@master:~/.ssh/slave2_id_rsa.pub
- 接着在Master节点上做如下配置,把id_rsa.pub追加到授权的key里面去
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
将所有slave的公钥追加到authorized_keys。
- 修改authorized_keys的权限
$ chmod 600 ~/.ssh/authorized_keys
- 将authorized_keys复制到所有的slave节点
$ scp ~/.ssh/authorized_keys hadoop@slave1:~/.ssh/
$ scp ~/.ssh/authorized_keys hadoop@slave2:~/.ssh/
- 验证master和slave可以互相免密钥登录。
//master
$ ssh slave1
//slave1
$ ssh master
...
3.4 所需软件
- JDK
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html
JDK版本:jdk-8u111-linux-x64.tar.gz
- hadoop
下载地址:http://hadoop.apache.org/releases.html
hadoop版本:hadoop1.0.3
3.5 Java环境安装和配置
root身份进行安装,如果系统已经安装了其他版本的java请先卸载旧版,再进行安装。
//解压
# tar -zxvf jdk-8u111-linux-x64.tar.gz
//移动文件夹到/usr下并重命名为java
# mv jdk1.8.0_111 /usr/java
最好能利用软链,方便管理多版本应用软件
配置java环境变量【替换成自己的java安装路径和版本】
# vim /etc/profile
//在文件尾部追加
# set java environment
export JAVA_HOME=/usr/java/jdk1.6.0_31
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
使配置立即生效
$ source /etc/profile
验证是否安装成功
$ java -version
安装其它机器,使用linux scp命令将java文件夹和profile文件复制到其它机器即可。
scp -r /usr/java hadoop@slave1:/usr/
3.6 hadoop集群安装
所有的机器上都要安装hadoop,现在就先在Master服务器安装,然后其他服务器按照步骤重复进行即可。安装和配置hadoop需要以root的身份进行。
在/usr目录下新建文件夹cloud
# mkdir /usr/cloud
解压
# tar -zxvf hadoop-1.0.3.tar.gz
//移动到/usr/cloud文件夹下
# mv hadoop-xxx /usr/cloud/hadoop
将读权限分配给hadoop用户
# chown -R hadoop:hadoop /usr/cloud/hadoop
配置hadoop环境变量【注意替换】
# vim /etc/profile
//最后追加
# set hadoop path
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH :$HADOOP_HOME/bin
使配置立即生效
# source /etc/profile
创建tmp文件夹
# mkdir /usr/cloud/hadoop/tmp
3.7 hadoop集群配置
hadoop2.5.2配置文件目录变更为/hadoop/etc/hadoop
- 配置hadoop-env.sh
# vim /usr/cloud/hadoop/conf/hadoop-env.sh
//在文件末尾追加
# set java environment
export JAVA_HOME=/usr/java
- 配置core-site.xml
修改Hadoop核心配置文件core-site.xml,这里配置的是HDFS的地址和端口号。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
(备注:请先在 /usr/hadoop 目录下建立 tmp 文件夹)
<description>A base for other temporary directories.</description>
</property>
<!-- file system properties -->
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.1.2:9000</value>
</property>
</configuration>
备注:如没有配置hadoop.tmp.dir参数,此时系统默认的临时目录为:/tmp/hadoo-hadoop。而这个目录在每次重启后都会被干掉,必须重新执行format才行,否则会出错。
- 配置hdfs-site.xml
修改Hadoop中HDFS的配置,配置的备份方式默认为3。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
(备注:replication 是数据副本数量,默认为3,salve少于3台就会报错)
</property>
<configuration>
- 配置mapred-site.xml
修改Hadoop中MapReduce的配置文件,配置的是JobTracker的地址和端口。
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>http://192.168.1.2:9001</value>
</property>
</configuration>
- 配置master文件
修改localhost为master
# vim /usr/cloud/hadoop/conf/masters
- 配置slaves文件【master主机独有】
去掉"localhost",每行只添加一个主机名,把剩余的Slave主机名都填上。
# vim /usr/cloud/hadoop/conf/slaves
- 配置其他机器
将 Master上配置好的hadoop所在文件夹"/usr/cloud/"复制到所有的Slave的"/usr/"目录下(实际上Slave机器上的slavers文件是不必要的, 复制了也没问题)。用下面命令格式进行。(备注:此时用户可以为hadoop也可以为root)
# scp -r /usr/cloud hadoop@slave1:/usr/
# scp -r /usr/cloud hadoop@slave2:/usr/
在slave上配置java和hadoop的环境变量
3.8 启动及验证
- 格式化HDFS文件系统
在master上使用普通用户hadoop进行操作。(备注:只需一次,下次启动不再需要格式化,只需 start-all.sh)
# hadoop namenode -format
- 启动hadoop
在启动前关闭集群中所有机器的防火墙,不然会出现datanode开后又自动关闭。
# ./start-all.sh

可以通过以下启动日志看出,首先启动namenode 接着启动datanode1,datanode2,…,然后启动secondarynamenode。再启动jobtracker,然后启动tasktracker1,tasktracker2,…。
启动 hadoop成功后,在 Master 中的 tmp 文件夹中生成了 dfs 文件夹,在Slave 中的 tmp 文件夹中均生成了 dfs 文件夹和 mapred 文件夹。
- 验证hadoop
方法1:在Master上用 java自带的小工具jps查看进程。

在Slave1上用jps查看进程。

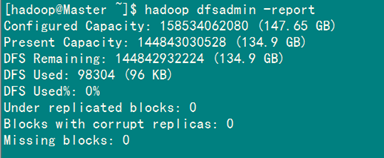
方法2:用hadoop dfsadmin -report
用这个命令可以查看Hadoop集群的状态。
- 网页查看集群
访问"http:192.168.1.2:50030"
访问"http:192.168.1.2:50070"
0x04 常见问题
4.1 关于 Warning: $HADOOP_HOME is deprecated
经查hadoop-1.0.0/bin/hadoop脚本和"hadoop-config.sh"脚本,发现脚本中对HADOOP_HOME的环境变量设置做了判断,笔者的环境根本不需要设置HADOOP_HOME环境变量。
解决方案一:编辑"/etc/profile"文件,去掉HADOOP_HOME的变量设定,重新输入hadoop fs命令,警告消失。
解决方案二:编辑"/etc/profile"文件,添加一个环境变量,之后警告消失:
export HADOOP_HOME_WARN_SUPPRESS=1
# source /etc/profile
博客中在配置hadoop是master的配置不需要改,否则会出错!!!!
2017年1月20日, 星期五
Hadoop1.0.3安装部署的更多相关文章
- Storm-0.9.0.1安装部署 指导
可以带着下面问题来阅读本文章: 1.Storm只支持什么传输 2.通过什么配置,可以更改Zookeeper默认端口 3.Storm UI必须和Storm Nimbus部署在同一台机器上,UI无法正常工 ...
- kafka_2.11-2.0.0_安装部署
参考博文:kafka 配置文件参数详解 参考博文:Kafka[第一篇]Kafka集群搭建 参考博文:如何为Kafka集群选择合适的Partitions数量 参考博文:Kafka Server.prop ...
- 大数据篇:DolphinScheduler-1.2.0.release安装部署
大数据篇:DolphinScheduler-1.2.0.release安装部署 1 配置jdk #查看命令 rpm -qa | grep java #删除命令 rpm -e --nodeps xxx ...
- [DPI][suricata] suricata-4.0.3 安装部署
suricata 很值得借鉴.但是首先还是要安装使用,作为第一步的熟悉. 安装文档:https://redmine.openinfosecfoundation.org/projects/suricat ...
- centOS6.5 Hadoop1.0.4安装
前段时间去培训,按照教程装了一遍Hadoop.回来又重新装一次,捋下思路,加深理解. 基本配置如下,三个节点,一个namenode,两个datanode. Namenode 192.168.59.14 ...
- zabbix4.0.1 安装部署
zabbix安装部署 目录 一.环境准备... 3 1.1.版本:... 3 1.2.部署环境... 3 二.安装部署... 3 2.1.zabbix安装... 3 2.1.1.下载zabbix的rp ...
- presto 0.166安装部署
系统:linux java:jdk 8,64-bit Connector:hive 分布式,node1-3 node1:Coordinator . Discovery service node2-3: ...
- Hbase-2.0.0_01_安装部署
该文章是基于 Hadoop2.7.6_01_部署 进行的 1. 主机规划 主机名称 IP信息 内网IP 操作系统 安装软件 备注:运行程序 mini01 10.0.0.11 172.16.1.11 C ...
- jumperserver3.0的安装部署
适用于jumperserver版本:v0.3.1-2 官网:http://www.jumpserver.org/ 系统:centos7.2 基本安装 备注:如果是centos系统最好使用基本安装,否 ...
随机推荐
- 【原创】 Docker 中 运行 ASP.NET Core 站点
一. 建立 .NetCore 项目 a.新建项目 b.选择项目类型 c.添加控制器 d.添加视图 e.修改默认请求 f.发布 二. 准备 CentOS 环境 a.准备虚拟机 b.安装 docker ...
- 水题 第三站 HDU Largest prime factor
先写一遍思路,跟素数表很类似吧. 1)从小到大遍历数据范围内的所有数.把包含质因子的数的位置都设成跟质因子的位置相同. 2)同一个数的位置可能被多次复写.但是由于是从小到大遍历,这就保证了最后一次写入 ...
- Android服务端的设计
1.创建自己的MyServletContextListener.java: package yybwb; import java.net.ServerSocket; import javax.serv ...
- MySQl开发和生产环境索引对比
--1.创建索引信息表create table `t_index_update` ( `table_name` varchar(20) COLLATE gbk_bin DEFAULT NULL, ...
- 如何删除 SQL Server 表中的重复行
第一种:有主键的重复行,就是说主键不重复,但是记录的内容重复比如人员表tab ,主键列id,身份证编号idcard当身份证重复的时候,保留最小id值的记录,其他删除delete a from tab ...
- 关于github 0.6.2版本的使用方法
貌似做为一名前端开发人员,没听过使用过github,node,vue就像落伍一样,本人也是在前端自摸自爬的路上越走越远了,经常在群里听大神们讨论vue,github,node,好生羡慕,没人教,没人带 ...
- java文件上传Demo
说到文件上传我们要做到: 1.引入两个包:commons-fileupload-1.2.1.jar和commons-io-1.3.2.jar 2.将form改为上传文件模式:enctype=" ...
- 记录Centos一些坑
首先说一下写这篇博客的初衷. 最近去客户现场出差,搭建一套服务端的自动构建环境. 准备支持的环境有CentOS 7.5.java8.Tomcat 8.maven3.3.9.TBA 2.1.9.4 等等 ...
- 导出EXCEL遇到问题
EXCEL设置的格式要与写入信息的格式要匹配,比如写入信息是字符串类型,而EXCEL单元格是DATE类型则会出错.
- Angular02 将数据添加到组件中
准备:已经搭建好angular-cli环境.知道如何创建组件 一.将一个数据添加到组件中 1 创建一个新的组件 user-item 2 将组件添加到静态模板中 3 为组件添加属性,并利用构造器赋值 4 ...