in memory computing 存内计算是学术圈自娱自乐还是真有价值?
如果单从初衷和预想的价值来看,还是很诱人的。在冯诺依曼体系中,cpu计算和memory存储是分离的,而两者之间的data movement会造成高延迟和高耗能。
关于PIM类似的思想在50年前曾有人提出过,比如1969年WILLIAM H. KAUTZ发表的论文Cellular Logic-in-Memory Arrays和1970年在斯坦福大学工作的HAROLD S. STONE发表的论文A Logic-in-Memory Computer,不过因为当时memory scaling不大,耗能瓶颈还没有出现,人们更多的是对CPU性能的关注,所以这些想法并没有被实现。


而随着近年AI等访存密集和计算密集应用的发展,高延迟和高耗能的问题成为急需解决的问题。
Nvidia的Chief Scientist——Bill Dally在2015年的一个演讲Nvidia's Path to Exascale给了一组数据:DRAM与CPU之间的date movement耗能是单纯double precise浮点数加法耗能的1000倍。

2018年的一篇论文Google Workloads for Consumer Devices: Mitigating Data Movement Bottlenecks 统计了Google常见产品(Chome/Tensorflow Mobile/video playback/video capture)的耗能情况,发现62.7%浪费在cpu和memory之间的data movement上。

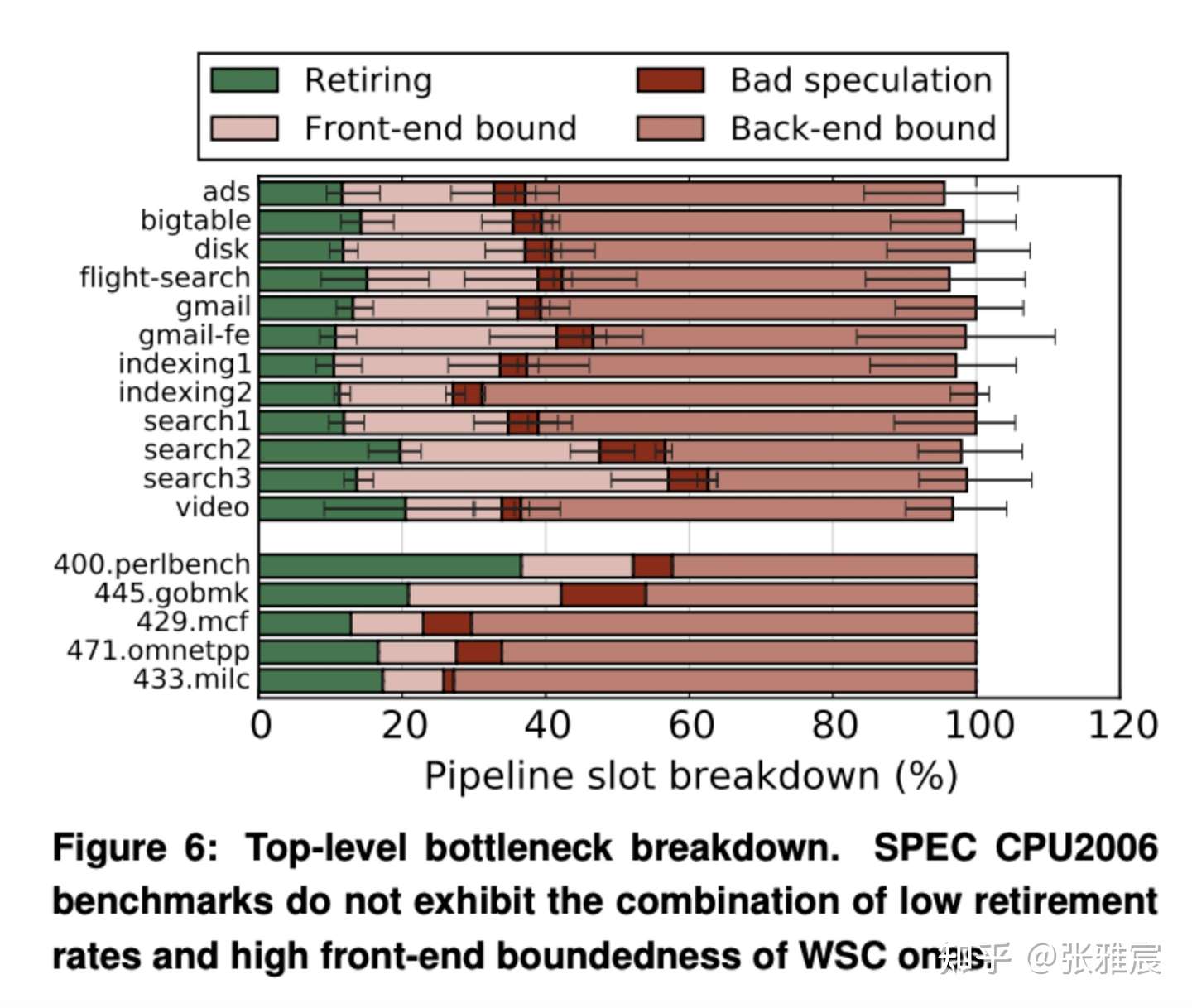
2015年Google和哈佛大学联合发表了论文Profiling a warehouse-scale computer,研究人员在Google不同数据中心的20000多台机器上做了为期三年的实验,发现只有20%左右的cycles在做【userful work】,而50% - 60%的cycles是因为Back-end bound而被浪费,在Back-end bound中,80%是【serving data cache request】

严格来说,题主说的in memory computing可以分成两类:
- process using memory : 偏向于电路革新,比如让存储器本身具有计算能力,但是这种方法目前计算精度较为有限。
- process near memory : 存储器内部集成额外的计算单元,比如3D-stacked memory、logic in memory controllers.
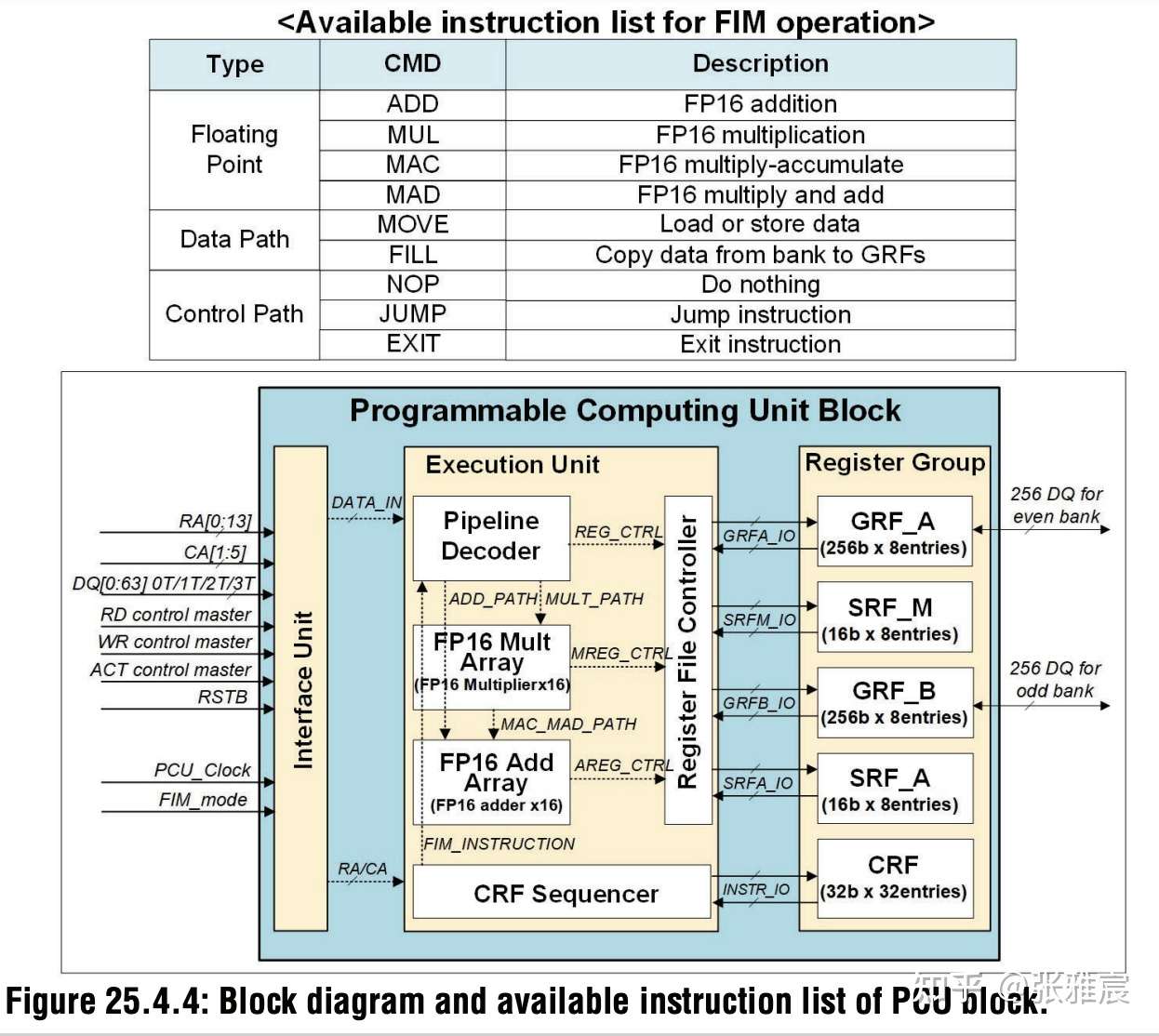
2021年Samsung发布了基于HBM-PIM的Function-in-Memory DRAM,主要针对AI场景,使用20nm DRAM工艺,并且实现了1.2TOPS的浮点数算力。可以将整体计算性能提升两倍、耗能降低70%。

Samsung在HBM-PIM中集成了额外的Programmable Computint Unit —— PCU,也就是上面说的process near memory。从下图可以看出,PCU包含了浮点数计算阵列FP16 Mult Array、流水线解码单元Pipeline Decoder、寄存器Register Group。PCU直接从邻近的DRAM中直接读取相关数据,在FP16 Mult Array中完成计算,并且根据指令进一步把结果存储到寄存器中,同时主控制器也可以根据需要把结果从寄存器读出。
另外一个比较出名的是UPMEM在2019 Hot Chips上发布的Processing-in-DRAM Engine。与Samsung的不同,这个属于process using memory,在DRAM上开发了内置于DRAM芯片本身的DPU,每个DPU可以访问64 MB的DRAM。UPMEM预计大多数应用需要几百行代码,少数人组成的团队只需2-4周就可以更新软件。


Samsung于2022年1月12号(上上周)在Nature上发布了业内首个基于 MRAM(磁性随机存储器)的存内计算芯片。这个我没细研究过,但是用MRAM来做存内计算,也算是一个巨大的飞跃。

不过还是有很多因素阻碍的PIM,比如:
- memory interleave的问题,现代memory都是按照channel去interleave,用PIM后,比如3D-stacked memory后,如何去分布数据
- 如何更方便的编程,什么操作用PIM,什么操作用CPU
- cache coherence
- 工艺的复杂程度
- ......
Onur Mutlu在ETH Zürich的Fall 2021Computer Architecture课程里也讲过之前关于PIM论文在ISCA 2016、MICRO 2016、HPCA 2017和ISCA 2017被Reject的历史,Reviewer当时给出的comment意思基本是This Will Never Get Implemented、Not practical:


Onur Mutlu对Reviewers的建议 : )

我们一般都是根据过去的经验去评价未来,没价值也没人去做了,这个价值不单单指钱 ,而且真的改变世界了呢 : )
(完)
朋友们可以关注下我的公众号,获得最及时的更新:

in memory computing 存内计算是学术圈自娱自乐还是真有价值?的更多相关文章
- 洛谷P2241-统计方形-矩形内计算长方形和正方形的数量
洛谷P2241-统计方形 题目描述: 有一个 \(n \times m\) 方格的棋盘,求其方格包含多少正方形.长方形(不包含正方形). 思路: 所有方形的个数=正方形的个数+长方形的个数.对于任意一 ...
- [Linux Memory] 用/proc/stat计算cpu的占用率
转载自:http://blog.csdn.net/pppjob/article/details/4060336 在Linux下,CPU利用率分为用户态,系统态和空闲态,分别表示CPU处于用户态执行的时 ...
- [Android Memory] Shallow Heap大小计算释疑
转载自:http://blog.csdn.net/sodino/article/details/24186907 查看Mat文档时里面是这么描述Shallow Heap的:Shallow heap i ...
- box-sizing:border-box 将元素的内边距和边框都设定在宽高内计算
http://www.w3school.com.cn/cssref/pr_box-sizing.asp box-sizing: content-box|border-box|inherit; 值 描述 ...
- 计算思维(美国CMU周以真教授)
博主注:GIScience会议是国际上最为著名的地理信息系统领域的国际会议,自2000年起,每两年举办一次,GIScience 2008会议邀请了美国卡内基-梅隆大学(CMU)计算机系华裔教授周以真博 ...
- 固态硬盘SSD与闪存(Flash Memory)
转自:http://qiaodahai.com/solid-state-drives-ssd-and-flash-memory.html 固态硬盘SSD(Solid State Drive)泛指使用N ...
- yarn资源memory与core计算配置
yarn调度分配主要是针对Memory与CPU进行管理分配,并将其组合抽象成container来管理计算使用 memory配置 计算每台机子最多可以拥有多少个container: container ...
- NANDflash和NORflash的区别(设计师在使用闪存时需要慎重选择)
NANDflash和NORflash的区别(设计师在使用闪存时需要慎重选择) NOR和NAND是现在市场上两种主要的非易失闪存技术.Intel于1988年首先开发出NOR flash技术,彻底 ...
- TensorFlow中的显存管理器——BFC Allocator
背景 作者:DeepLearningStack,阿里巴巴算法工程师,开源TensorFlow Contributor] 使用GPU训练时,一次训练任务无论是模型参数还是中间结果都需要占用大量显存.为了 ...
随机推荐
- 2022.02.05 DAY2
前言 今天陪老姐送对象去安庆了,上午还去了西风禅寺求了个签,第一次拿到中评签,看来今年还需要继续努力哈哈哈.一直到晚上才有时间去做点题目,今天依旧是leetcode. 题目 leetcode 1 两数 ...
- IPsec协议簇简析
简介 IPsec协议簇是应用在网络层上的,来保护IP数据报的一组网络传输协议的集合.它是IETF(Internet Engineering Task Force)制定的一系列协议,它为IP数据报提供了 ...
- 「JSOI2018」机器人
在本题当中为了方便,我们将坐标范围改至 \((0 \sim n - 1, 0 \sim m - 1)\),行走即可视作任意一维在模意义下 \(+1\). 同时,注意到一个位置只能经过一次,则可以令 \ ...
- JVM学习十 -(复习)内存分配与回收策略
内存分配与回收策略 对象的内存分配,就是在堆上分配(也可能经过 JIT 编译后被拆散为标量类型并间接在栈上分配),对象主要分配在新生代的 Eden 区上,少数情况下可能直接分配在老年代,分配规则不固定 ...
- cmd中删除、添加、修改注册表命令
转自:http://www.jb51.net/article/30586.htm regedit的运行参数 REGEDIT [/L:system] [/R:user] filename1 REGEDI ...
- 在linux下的mysql导入存储过程出现语法错误,需要在文件里加DELIMITER //
http://my.oschina.net/zerotime/blog/113126 Mysql命令行创建存储过程时,首先要输入分隔符 DELIMITER // CREATE PROCEDURE pr ...
- Charles抓包工具介绍
1.Charles是什么? Charles是一款基于http协议的代理服务器,通过称为电脑或者浏览器的代理,然后截取请求和请求结果达到分析抓包的目的. 2.Charles有哪些用途? (1)能够分析前 ...
- PHP获取用户IP地址
PHP获取访问者IP地址 这是一段 PHP 代码,演示了如何获得来访者的IP address. <?php//打印出IP地址:echo (GetIP());function GetIP() / ...
- 使用java程序完成大量文件目录拷贝工作
java程序完成目录拷贝工作 背景描述:我目录有140多个,每个目录里面都有一个src目录.我现在想要所有的src目录移动到同一个目录中. package com.util.cp; import ja ...
- 2020年的第一天-我的IDEA出现This license ... has been cancelled
IDEA激活在1月3日的早上,激活码被取消了.提示:This license ... has been cancelled. 经过查询.解决方法教程无非是. ¥%--&*(激活码... 210 ...