LSMT 实战-python
长短期记忆网络(LSTM,Long Short-Term Memory)
使用kears 搭建一个LSTM预测模型,使用2022年美国大学生数学建模大赛中C题中处理后的BTC比特币的数据进行数据训练和预测。
这篇博客包含两个预测,一种是使用前N天的数据预测后一天的数据,一种使用前N天的数据预测后N天的数据
第一种:使用前个三十天数据进行预测后一天的数据。
总数据集:1826个数据
数据下载地址:需要的可以自行下载,很快
- 链接:https://pan.baidu.com/s/1TmQxLfzHiyOL3vEVcuWlgQ
- 提取码:wy0f
模型结构
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 30, 64) 16896
_________________________________________________________________
lstm_1 (LSTM) (None, 30, 128) 98816
_________________________________________________________________
lstm_2 (LSTM) (None, 32) 20608
_________________________________________________________________
dropout (Dropout) (None, 32) 0
_________________________________________________________________
dense (Dense) (None, 1) 33
=================================================================
Total params: 136,353
Trainable params: 136,353
Non-trainable params: 0
_________________________________________________________________
训练100次:

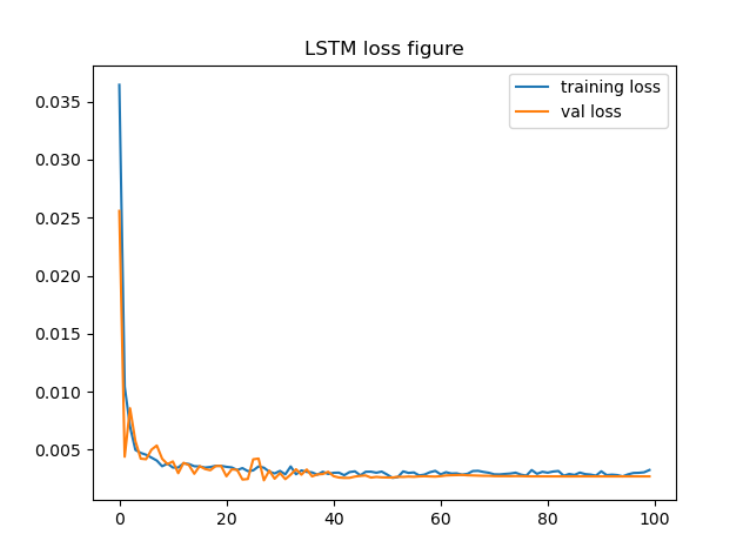
损失函数图像:
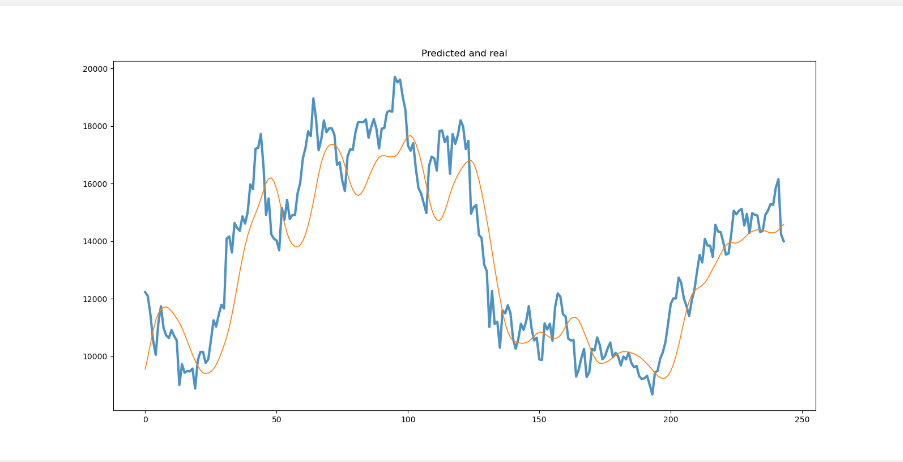
预测和真实值比较,可以看到效果并不是很好,这个需要自己调参进行变化
- 我的GPU加速时1650还挺快,7.5算力,训练时间可以接受

代码:
# 调用库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow import keras
from tensorflow.keras import layers
from sklearn.preprocessing import MinMaxScaler
#### 数据处理部分 ####
# 读入数据
data = pd.read_excel('BTCtest.xlsx')
# 时间戳长度
time_step = 30 # 输入序列长度
print(len(data))
# 划分训练集与验证集
data = data[['Value']]
train = data[0:1277]
valid = data[1278:1550]
test = data[1551:]
# 归一化
scaler = MinMaxScaler(feature_range=(0, 1))
# datas 切片数据 time_step要输入的维度 pred 预测维度
def scalerClass(datas,scaler,time_step,pred):
x, y = [], []
scaled_data = scaler.fit_transform(datas)
for i in range(time_step, len(datas) - pred):
x.append(scaled_data[i - time_step:i])
y.append(scaled_data[i: i + pred])
# 把x_train转变为array数组
x, y = np.array(x), np.array(y).reshape(-1, 1) # reshape(-1,5)的意思时不知道分成多少行,但是是五列
return x,y
# 训练集 验证集 测试集 切片
x_train,y_train = scalerClass(train,scaler,time_step=time_step,pred=1)
x_valid, y_valid = scalerClass(valid,scaler,time_step=time_step,pred=1)
x_test, y_test = scalerClass(test,scaler,time_step=time_step,pred=1)
#### 建立神经网络模型 ####
model = keras.Sequential()
model.add(layers.LSTM(64, return_sequences=True, input_shape=(x_train.shape[1:])))
model.add(layers.LSTM(128, return_sequences=True))
model.add(layers.LSTM(32))
model.add(layers.Dropout(0.3))
model.add(layers.Dense(1))
# model.compile(optimizer = 优化器,loss = 损失函数, metrics = ["准确率”])
# “adam" 或者 tf.keras.optimizers.Adam(lr = 学习率,decay = 学习率衰减率)
# ”mse" 或者 tf.keras.losses.MeanSquaredError()
model.compile(optimizer=keras.optimizers.Adam(), loss='mse',metrics=['accuracy'])
# monitor:要监测的数量。
# factor:学习速率降低的因素。new_lr = lr * factor
# patience:没有提升的epoch数,之后学习率将降低。
# verbose:int。0:安静,1:更新消息。
# mode:{auto,min,max}之一。在min模式下,当监测量停止下降时,lr将减少;在max模式下,当监测数量停止增加时,它将减少;在auto模式下,从监测数量的名称自动推断方向。
# min_delta:对于测量新的最优化的阀值,仅关注重大变化。
# cooldown:在学习速率被降低之后,重新恢复正常操作之前等待的epoch数量。
# min_lr:学习率的下限
learning_rate= keras.callbacks.ReduceLROnPlateau(monitor='val_loss', patience=3, factor=0.7, min_lr=0.00000001)
#显示模型结构
model.summary()
# 训练模型
history = model.fit(x_train, y_train,
batch_size = 128,
epochs=100,
validation_data=(x_valid, y_valid),
callbacks=[learning_rate])
# loss变化趋势可视化
plt.title('LSTM loss figure')
plt.plot(history.history['loss'],label='training loss')
plt.plot(history.history['val_loss'], label='val loss')
plt.legend(loc='upper right')
plt.show()
#### 预测结果分析&可视化 ####
# 输入测试数据,输出预测结果
y_pred = model.predict(x_test)
# 输入数据和标签,输出损失和精确度
model.evaluate(x_test)
scaler.fit_transform(pd.DataFrame(valid['Value'].values))
# 反归一化
y_pred = scaler.inverse_transform(y_pred.reshape(-1,1)[:,0].reshape(1,-1)) #只取第一列
y_test = scaler.inverse_transform(y_test.reshape(-1,1)[:,0].reshape(1,-1))
# 预测效果可视化
plt.figure(figsize=(16, 8))
plt.title('Predicted and real')
dict = {
'Predictions': y_pred[0],
'Value': y_test[0]
}
data_pd = pd.DataFrame(dict)
plt.plot(data_pd[['Value']],linewidth=3,alpha=0.8)
plt.plot(data_pd[['Predictions']],linewidth=1.2)
#plt.savefig('lstm.png', dpi=600)
plt.show()
预测后几天的数据和预测后一天原理是一样的
- 因为预测的是5天的数据所以不能使用图像显示出来,只能取出预测五天的头一天的数据进行绘图。数据结构可以打印出来的,我没有反归一化,需要的时候再弄把
- 前五十天预测五天的代码:
# 调用库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow import keras
from tensorflow.keras import layers
from sklearn.preprocessing import MinMaxScaler
# 读入数据
data = pd.read_excel('BTCtest.xlsx')
time_step = 50 # 输入序列长度
# 划分训练集与验证集
data = data[['Value']]
train = data[0:1277] #70%
valid = data[1278:1550] #15%
test = data[1551:] #15%
# 归一化
scaler = MinMaxScaler(feature_range=(0, 1))
# 定义一个切片函数
# datas 切片数据 time_step要输入的维度 pred 预测维度
def scalerClass(datas,scaler,time_step,pred):
x, y = [], []
scaled_data = scaler.fit_transform(datas)
for i in range(time_step, len(datas) - pred):
x.append(scaled_data[i - time_step:i])
y.append(scaled_data[i: i + pred])
# 把x_train转变为array数组
x, y = np.array(x), np.array(y).reshape(-1, 5) # reshape(-1,5)的意思时不知道分成多少行,但是是五列
return x,y
# 训练集 验证集 测试集 切片
x_train,y_train = scalerClass(train,scaler,time_step=time_step,pred=5)
x_valid, y_valid = scalerClass(valid,scaler,time_step=time_step,pred=5)
x_test, y_test = scalerClass(test,scaler,time_step=time_step,pred=5)
# 建立网络模型
model = keras.Sequential()
model.add(layers.LSTM(64, return_sequences=True, input_shape=(x_train.shape[1:])))
model.add(layers.LSTM(64, return_sequences=True))
model.add(layers.LSTM(32))
model.add(layers.Dropout(0.1))
model.add(layers.Dense(5))
model.compile(optimizer=keras.optimizers.Adam(), loss='mse',metrics=['accuracy'])
learning_rate_reduction = keras.callbacks.ReduceLROnPlateau(monitor='val_loss', patience=3, factor=0.7, min_lr=0.000000005)
model.summary()
history = model.fit(x_train, y_train,
batch_size = 128,
epochs=30,
validation_data=(x_valid, y_valid),
callbacks=[learning_rate_reduction])
# loss变化趋势可视化
plt.title('LSTM loss figure')
plt.plot(history.history['loss'],label='training loss')
plt.plot(history.history['val_loss'], label='val loss')
plt.legend(loc='upper right')
plt.show()
#### 预测结果分析&可视化 ####
y_pred = model.predict(x_test)
model.evaluate(x_test)
scaler.fit_transform(pd.DataFrame(valid['Value'].values))
print(y_pred)
print(y_test)
# 预测效果可视化
# 反归一化
y_pred = scaler.inverse_transform(y_pred.reshape(-1,5)[:,0].reshape(1,-1)) #只取第一列
y_test = scaler.inverse_transform(y_test.reshape(-1,5)[:,0].reshape(1,-1))
plt.figure(figsize=(16, 8))
plt.title('Predicted and real')
dict_data = {
'Predictions': y_pred.reshape(1,-1)[0],
'Value': y_test[0]
}
data_pd = pd.DataFrame(dict_data)
plt.plot(data_pd[['Value']],linewidth=3,alpha=0.8)
plt.plot(data_pd[['Predictions']],linewidth=1.2)
plt.savefig('lstm.png', dpi=600)
plt.show()
LSMT 实战-python的更多相关文章
- 《实战Python网络爬虫》- 感想
端午节假期过了,之前一直在做出行准备,后面旅游完又休息了一下,最近才恢复状态. 端午假期最后一天收到一个快递,回去打开,发现是微信抽奖中的一本书,黄永祥的<实战Python网络爬虫>. 去 ...
- 移动端自动化测试Appium 从入门到项目实战Python版☝☝☝
移动端自动化测试Appium 从入门到项目实战Python版 (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 说到APP自动化测试,Appium可是说是非常流 ...
- 移动端自动化测试appium 从入门到项目实战Python版✍✍✍
移动端自动化测试appium 从入门到项目实战Python版 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程 ...
- 移动端自动化测试Appium 从入门到项目实战Python版
移动端自动化测试Appium 从入门到项目实战Python版 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课 ...
- Django-Multitenant,分布式多租户数据库项目实战(Python/Django+Postgres+Citus)
Python/Django 支持分布式多租户数据库,如 Postgres+Citus. 通过将租户上下文添加到您的查询来实现轻松横向扩展,使数据库(例如 Citus)能够有效地将查询路由到正确的数据库 ...
- 实战Python实现BT种子转化为磁力链接
经常看电影的朋友肯定对BT种子并不陌生,但是BT种子文件相对磁力链来说存储不方便,而且在网站上存放BT文件容易引起版权纠纷,而磁力链相对来说则风险小一些. 将BT种子转换为占用空间更小,分享更方便的磁 ...
- 机器学习实战-python相关软件库的安装
1 安装python 2 安装sublime text2 3 安装NumPy.Matplotlib http://book.51cto.com/art/201401/426522.htm Matplo ...
- NBC朴素贝叶斯分类器 ————机器学习实战 python代码
这里的p(y=1|x)计算基于朴素贝叶斯模型(周志华老师机器学习书上说的p(xi|y=1)=|Dc,xi|/|Dc|) 也可以基于文本分类的事件模型 见http://blog.csdn.net/app ...
- redis实战 -- python知识散记
-- time.time() -- row.to_dict() -- json.dumps(row.to_dict()) #!/usr/bin/env python import time def s ...
随机推荐
- 简述BIO/NIO/AIO前世今生
如下程序是简单实现了一个极其简单的WEB服务器,用来监听某个端口,接受客户端输入输出信息. 但这个程序有一个致命的问题就是连接会长时间阻塞 于是BIO版本出现了,改成了 一个连接 一个线程来处理请求 ...
- golang中的标准库time
时间类型 time.Time类型表示时间.我们可以通过time.Now()函数获取当前的时间对象,然后获取时间对象的年月日时分秒等信息.示例代码如下: func main() { current := ...
- Python 使用 Windows10 桌面通知
前言 Win10 没有提供简单命令行方式来触发桌面通知,所以使用 Python 来写通知脚本. 一番搜索,找到 win10toast .但这开源仓库已无人维护,通过 github fork 的关系图, ...
- 利用Jemalloc进行内存泄漏的调试
内存不符预期的不断上涨,可能的原因是内存泄漏,例如new出来的对象未进行delete就重新进行复制,使得之前分配的内存块被悬空,应用程序没办法访问到那部分内存,并且也没有办法释放:在C++中,STL容 ...
- js文件中三斜杠注释///reference path的用途
编辑某个js文件时,要想这个js文件出现其他js成员的ide提示,可以在js文件开头使用3个斜杠注释和reference指令的path指向此js文件路径,这样在编写这个js文件时,ide就会自动出现p ...
- ABC182 F Valid payments
解法一 首先不妨来思考一下怎样的一个付钱方案是最优的,假设需要支付 \(Y\) 元,第 \(a_i\) 种钱币支付了 \(s_i\) 张,那么必须有:\(s_i < \frac{a_{i + 1 ...
- Android 使用签名的好处【转】
感谢大佬:https://zhidao.baidu.com/question/360127490062917572.html 平时我们的程序可以在模拟器上安装并运行,是因为在应用程序开发期间,由于是以 ...
- Ubuntu16.04的PHP开发环境配置
\3c a { text-decoration: none } 自从换了php开发之后发现还是开源语言才是长久之道,开发环境搭建方便,支持的平台也多,性能也好,考虑到这些,其他一些不如意也就不足为虑了 ...
- Idea快捷键---根据自己使用情况持续更新
查看接口的实现类 -->ctrl+alt+b 查看继承关系 -->ctrl+h 快速查看上次查看代码的位置: -->ctrl+alt+方向键(注意与intel显卡快捷键的冲突,如有冲 ...
- 洛谷P1563 [NOIP2016 提高组] 玩具谜题
题目链接:https://www.luogu.com.cn/problem/P1563 哈哈哈,这个题拿来一读是不是很吃惊hahaha,我刚开始读的时候吓了我一跳,这么长的题干,这么绕的题意,还有下面 ...