RabbitMQ,RocketMQ,Kafka 消息模型对比分析
消息模型
消息队列的演进
消息队列模型
早起的消息队列是按照"队列"的数据结构来设计的。
生产者(Producer)产生消息,进行入队操作,消费者(Consumer)接收消息,就是出队操作,存在于服务端的消息容器就称为消息队列。

当然消费者也可能不止一个,存在的多个消费者是竞争的关系,消息被其中的一个消费者消费了,其它的消费者就拿不到消息了。
发布订阅模型
如果一个人消息想要同时被多个消费者消费,那么上面的队列模式就不适用了,于是又引出了一种新的模式,发布订阅模型。

在发布-订阅模型中,消息的发送方称为发布者(Publisher),消息的接收方称为订阅者(Subscriber),服务端存放消息的容器称为主题(Topic)。
发布者发送消息到主题中,然后订阅者需要先订阅主题。订阅主题的订阅者之后就可以收到发送者发送的消息了。
发布订阅也是兼容消息队列模型的,如果只有一个订阅者,就是消息队列模型了。
RabbitMQ的消息模型
RabbitMQ 使用的还是消息队列这种消息模型,不过它引入了一个 exchange 的概念。
exchange 也就是交换器,位于生产者和队列之间,生产者产生的数据是直接发送到 exchange 中,然后 exchange 根据配置的策略将消息发送到对应的队列中。

RabbitMQ 中通过绑定将交换器和队列关联起来,绑定的时候一般会指定一个绑定键(BindingKey)。
生产者发送消息的时候会指定一个 RoutingKey ,当 RoutingKey 和 BindingKey,一样的时候就会被发送的对应的队列中去。
交换器的类型
RabbitMQ 中肠常用的交换器有 fanout、direct、topic、headers 四种,这里来一一分析下
direct
direct 会根据发送消息的 RoutingKey ,然后发送到和 RoutingKey 匹配的 BindingKey 对应的队列中去。

如果发送消息的路由键也就是 RoutingKey,为 log 的时候,两个消息队列都会收到消息,如果路由键为 debug ,exchange 只会把消息发送到消息队列1中。
topic
direct 中的 RoutingKey 和 BindingKey 是完全匹配才能发送消息,topic 中在此基础之上做了扩展,也就是引入了模糊匹配机制。
RoutingKey 和 BindingKey 中使用 . ,来分割字符串,被 . 分割开的每一段字符串就是一个匹配字符;
BindingKey 中主要通过 * 和 # ,用于模糊匹配,* 表示一个单词,# 代表任意0个或多个单词;
BindingKey 中单独使用 # 时,会接收所有的消息,这与类型 fanout一致;
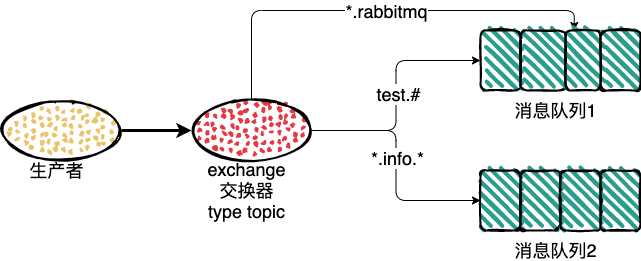
栗子:
1、路由键为 test.rabbitmq 消息队列1和消息队列2都会收到消息;
2、路由键为 rabbitmq 没有队列能收到消息;
3、路由键为 test 消息队列2会收到消息;
4、路由键为 rr.info.ww 消息队列2会收到消息;
5、路由键为 info 没有队列能收到消息;
fanout
该交换器收到的信息会被发送到所有与改交换器绑定的队列中。
headers
headers 类型的交换器不依赖于路由键的匹配规则来路由消息,而是根据发送的消息内容中 headers 属性进行匹配。在绑定队列和交换器时制定一组键值对当发送消息到交换器时,RabbitMQ 会获取到该消息的 headers (也是一个键值对的形式) ,对比其中的键值对是否完全匹配队列和交换器绑定时指定的键值对,如果完全匹配则消息会路由到该队列,否则不会路由到该队列 headers 类型的交换器性能会很差,而且也不实用,基本上不会看到它的存在。
Kafka的消息模型

Kafaka 中引入了一个 broker。broker 接收生产者的信息,为消息设置偏移量,并且保存的磁盘中。broker 为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。
同时 broker 也会对生产者和消费者进行消息的确认。
生产者发送消息到 broker,如果没有收到 broker 的确认就可以选择继续发送;
消费者同理,在消费端,消费者在收到消息并完成自己的消费业务逻辑(比如,将数据保存到数据库中)后,也会给服务端发送消费成功的确认,broker 只有收到消费确认后,才认为一条消息被成功消费,否则它会给消费者重新发送这条消息,直到收到对应的消费成功确认。
如果一个主题中,每次只有一个消费实例在处理,同时我们也要保持消息的有序性,当前消息没有被消费掉就不能接着消费下一个消息。那么,消费的性能将是极低的,这时候引入了一个分区的概念。
主题可以被分为若干个分区,一个分区就是一个提交日志。消息以追加的方式写入分区,然后以先入先出的顺序读取。要注意,由于一个主题一般包含几个分区,因此无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序。
同时引入了消费者组,消费者是消费者组中的一部分,这样会有一个或者多个消费者读一个分支,不过群组会保证一个分区只能被一个消费者消费,通过多消费者,这样消费的性能就提高了。
每个消费组都消费主题中一份完整的消息,不同消费组之间消费进度彼此不受影响,也就是说,一条消息被Consumer Group1消费过,也会再给Consumer Group2消费。不过同组内是竞争关系,同组内一个消息只能被同组内的一个消息消费。
消费者通过偏移量来确认读过的数据,他是个不断累加的数据,每次成功消费一个数据这个偏移量就加一。在给定的分区中,每个消息的偏移量都是唯一的。消费者会把每个分区读取的消息偏移量保存在 Zookeeper 或 Kafka 上,如果消费者关闭或重启,它的读取状态不会丢失。
RocketMQ的消息模型

RocketMQ 中的消息模型和 Kafaka 类似,把 Kafaka 中的分区换成队列,就是 RocketMQ 的消息模型了。
不过虽然消息模型类似,但是实现方式还是有很大的差别的。
参考
【消息队列高手课】https://time.geekbang.org/column/intro/100032301
【消息队列设计精要】https://tech.meituan.com/2016/07/01/mq-design.html
【RabbitMQ实战指南】https://book.douban.com/subject/27591386/
【Kafka权威指南】https://book.douban.com/subject/27665114/
【RabbitMQ,RocketMQ,Kafka 消息模型对比分析】https://boilingfrog.github.io/2021/12/18/几种消息队列的消息模型/
RabbitMQ,RocketMQ,Kafka 消息模型对比分析的更多相关文章
- MQ选型对比ActiveMQ,RabbitMQ,RocketMQ,Kafka 消息队列框架选哪个?
最近研究消息队列,发现好几个框架,搜罗一下进行对比,说一下选型说明: 1)中小型软件公司,建议选RabbitMQ.一方面,erlang语言天生具备高并发的特性,而且他的管理界面用起来十分方便.不考虑r ...
- Kafka消息模型
一.消息传递模型 传统的消息队列最少提供两种消息模型,一种P2P,一种PUB/SUB,而Kafka并没有这么做,巧妙的,它提供了一个消费者组的概念,一个消息可以被多个消费者组消费,但是只能被一个消费者 ...
- RabbitMQ之五种消息模型
首先什么是MQ MQ全称是Message Queue,即消息对列!消息队列是典型的:生产者.消费者模型.生产者不断向消息队列中生产消息,消费者不断的从队列中获取消息.因为消息的生产和消费都是异步的,而 ...
- kafka消息分发策略分析
当我们使用kafka向指定Topic发送消息时,如果该Topic具有多个partition,无论消费者有多少,最终都会保证一个partition内的消息只会被一个Consumer group中的一个C ...
- rabbitmq五种消息模型整理
目录 0. 配置项目 1. 基本消息模型 1.1 生产者发送消息 1.2 消费者获取消息(自动ACK) 1.3 消息确认机制(ACK) 1.4 消费者获取消息(手动ACK) 1.5 自动ACK存在的问 ...
- 分布式消息队列RocketMQ&Kafka -- 消息的“顺序消费”
在说到消息中间件的时候,我们通常都会谈到一个特性:消息的顺序消费问题.这个问题看起来很简单:Producer发送消息1, 2, 3... Consumer按1, 2, 3...顺序消费. 但实际情况却 ...
- ActiveMQ、RabbitMQ、RocketMQ、Kafka四种消息中间件分析介绍
ActiveMQ.RabbitMQ.RocketMQ.Kafka四种消息中间件分析介绍 我们从四种消息中间件的介绍到基本使用,以及高可用,消息重复性,消息丢失,消息顺序性能方面进行分析介绍! 一.消息 ...
- 关于ActiveMQ、RocketMQ、RabbitMQ、Kafka一些总结和区别
这是一篇分享文 转自:http://www.cnblogs.com/williamjie/p/9481780.html 尊重原作,谢谢 消息队列 为什么写这篇文章? 博主有两位朋友分别是小A和小B: ...
- 8.关于ActiveMQ、RocketMQ、RabbitMQ、Kafka一些总结和区别
这是一篇分享文 转自:http://www.cnblogs.com/williamjie/p/9481780.html 尊重原作,谢谢 消息队列 为什么写这篇文章? 博主有两位朋友分别是小A和小B: ...
随机推荐
- [atARC128F]Game against Robot
为了方便,下文中的$n$是原来的$\frac{n}{2}$ 当确定排列$\{p_{i}\}$后,将$a_{i}$按照$p_{i}$从大到小排序,那么机器人即会不断选第一个元素 考虑玩家最后选择的$n$ ...
- 【Java面试题】-- Java String
Java String 2019-11-02 17:40:45 by冲冲 1.String的内存位置 String是定义在 java.lang 包下的一个类.它不是基本数据类型.String是不可 ...
- CF1562E Rescue Niwen!
开始的时候只会一个\(O(n^2log)\) 即做出所有的\(n^2\)串,显然可以用\(SAM\)来进行这样一个排序,然后\(log\)做. 但这种题我们显然要找一些友好的性质: 我们发现字符串的比 ...
- P6585 中子衰变
我们偶数的时候只要对称操作. 奇数的话,我们定义\(1\)的相反数为\(-1\),\(0\)相反数为\(0\). 我们维护最长的两边的相反串,中间一段除了一个端点,其他均被染成同色. 那么如果对方染端 ...
- CMake 工程调用 Makefile 编译项目
本文主要介绍如何将一个依赖 Makefile 项目(MIDG)移植到 CMake 上. 首先介绍项目文件结构,文件主要由三个目录组成 3rdParty include src 其中,3rdParty ...
- echo 输出彩色字符
借助echo的-e选项来实现,语法格式为 echo -e "\033[3xmsome things you want to print out.\033[0m" \033[3xm为 ...
- kubernetes部署 etcd 集群
本文档介绍部署一个三节点高可用 etcd 集群的步骤: etcd 集群各节点的名称和 IP 如下: kube-node0:192.168.111.10kube-node1:192.168.111.11 ...
- 大数据学习day33----spark13-----1.两种方式管理偏移量并将偏移量写入redis 2. MySQL事务的测试 3.利用MySQL事务实现数据统计的ExactlyOnce(sql语句中出现相同key时如何进行累加(此处时出现相同的单词))4 将数据写入kafka
1.两种方式管理偏移量并将偏移量写入redis (1)第一种:rdd的形式 一般是使用这种直连的方式,但其缺点是没法调用一些更加高级的api,如窗口操作.如果想更加精确的控制偏移量,就使用这种方式 代 ...
- tomcat在eclipse上发布,Perference下的server找不到解决办法
help--->Install New software得到如下所示 下面work with选项的内容与你的eclipse版本有关 我的eclipse版本为eclipse-java-2019-0 ...
- 剑指 Offer 10- I. 斐波那契数列
写一个函数,输入 n ,求斐波那契(Fibonacci)数列的第 n 项(即 F(N)).斐波那契数列的定义如下: F(0) = 0, F(1) = 1F(N) = F(N - 1) + F(N ...