Centos8.3、proxysql2.0读写分离实战记录
接着主从复制继续往下讲,这个项目中我是使用proxysql做读写分离的中间件,之前是使用mycat.老实说mycat属于比较重量级的中间件,1.0还好到了2.0配置变得很复杂而且文档不是很齐全,我看着比较吃力.所以我就选择了proxysql作为读写分离的中间件,相比mycat 它更加轻量级、配置简单、更改配置的时候不用重启就能生效。
快捷安装命令
还是是喜欢一键脚本安装比较省力气。其他安装方法请看 https://gitee.com/mirrors/proxysql#red-hat--centos
cat <<EOF | tee /etc/yum.repos.d/proxysql.repo[proxysql_repo]name= ProxySQL YUM repositorybaseurl=https://repo.proxysql.com/ProxySQL/proxysql-2.0.x/centos/\$releasevergpgcheck=1gpgkey=https://repo.proxysql.com/ProxySQL/repo_pub_key EOF
然后执行
yum install proxysql #安装默认
yum install proxysql-version #安装指定版本 二选一
systemctl enable proxysql #添加到开机启动
systemctl start proxysql #启动服务
开始配置
proxysql客户端:6033端口 代理mysql服务的端口 也就是应用连接使用的
proxysql管理端:6032端口 管理proxysql配置的端口 只能本地登录
登录管理端
mysql -uadmin -padmin -h127.0.0.1 -P6032 --prompt='Admin> ' --default-auth=mysql_native_password
proxysql的管理端和mysql的客户类似 可以使用 show tables;查询表如下图:
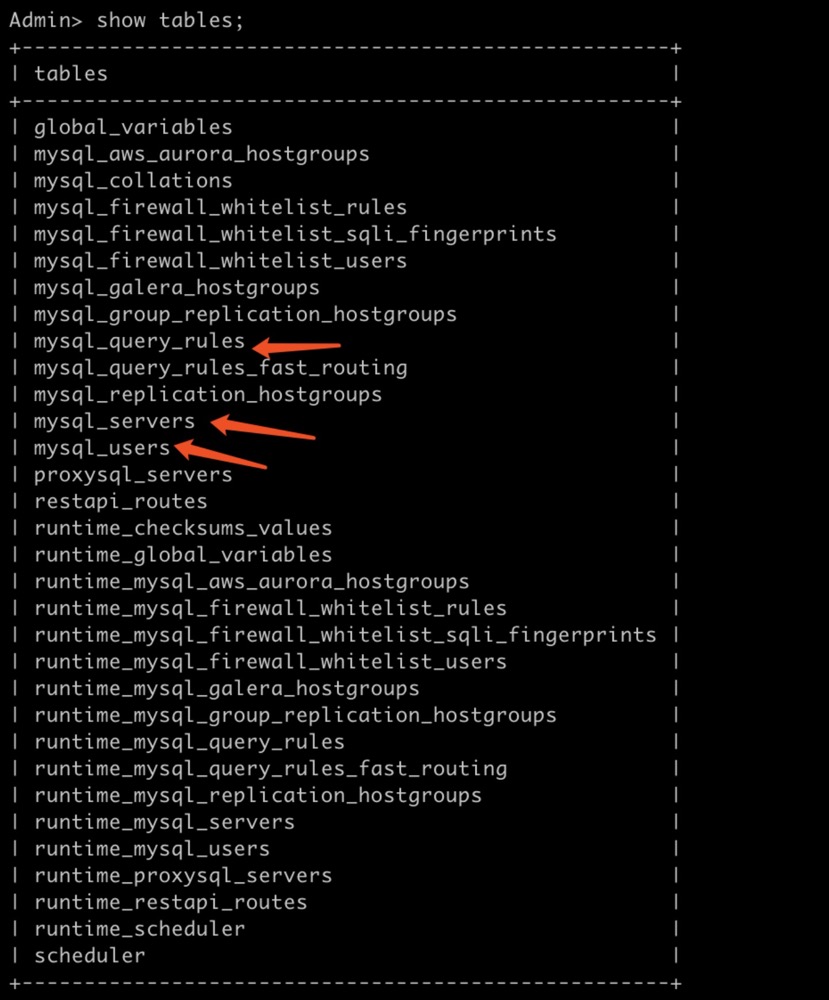
主要用到
mysql_servers 表是用来存储数据库实例信息
mysql_user 表是用来存储数据库实例账号信息
mysql_query_rules 路由规则表
添加数据库实例
insert into mysql_servers(hostgroup_id,hostname,port,weight,comment) values(1,'172.16.102.7',3306,1,'master');#添加数据库实例master insert into mysql_servers(hostgroup_id,hostname,port,weight,comment) values(2,'172.16.102.8',3306,1,'slave1');#添加数据库实例slave1 insert into mysql_servers(hostgroup_id,hostname,port,weight,comment) values(2,'172.16.102.9',3306,1,'slave2');#添加数据库实例slave2
hostgroup_id mysql_servers表的主键 很重要路由规则和账号表都有用到
hostname mysql数据库实例的ip
port mysql数据库实例的端口
weight 负载权重 数字越大承受的请求越多
comment 备注
查询添加结果
select * from mysql_servers; #和sql语句语法一致
如下图:

添加客户端连接账号
insert into mysql_users(username,password,default_hostgroup,transaction_persistent)values('proxysql','jishuzhai',1,1);
username mysql 实例的账号
password mysql 实例的密码 意味着所有mysql实例需要创建相同的账号密码。
default_hostgroup 和mysql_servers表的hostgroup_id进行关联 这里设置为1 意味着所有请求默认到hostgroup_id为1的这组实例然后在根据路由规则进行分发
transaction_persistent 开启事物支持 默认 0 关闭 这里设置为1开启。
查询添加结果
select * from mysql_users;
如下图:

添加路由规则
insert into mysql_query_rules(rule_id,active,match_digest,destination_hostgroup,apply) VALUES (1,1,'^SELECT.*FOR UPDATE$',1,1), (2,1,'^SELECT',2,1)
rule_id 路由编号
active 是否启用路由
match_digest 路由匹配规则 支持正则
destination_hostgroup 路由目标 也就数据库实例组
apply 1 匹配目标后直接转发
路由策略 所有请求到 default_hostgroup 设置的默认数据库实例组 然后根据路由规则把查询请求分发到hostgroup_id为2的数据库实例组
查询添加结果
select rule_id,active,match_digest,destination_hostgroup,log,apply from mysql_query_rules;
如下图:

规则1:查询更新结果的语句匹配搭配到hostgrouo_id 为1的实例组 也就是写的实例组
规则2: 匹配所有查询路由到hostgroup_id 为 2的实例组 也就是读的实例组
注意 proxysql的匹配规则是从路由编号 1开始的 所以这两条规则顺序不能颠倒 否则查询更新结果的语句永远不会路由到写的实例 因为查询包含查询更新结果。
添加监控账号
所谓监控账号就是用来监控数据库实例状态的账号,这里我和上面使用了同一个账号,可以分开 但是要在所有实例上都要创建。
set mysql-monitor_username='proxysql';
set mysql-monitor_password='jishuzhai';
查看监控情况
SELECT * FROM monitor.mysql_server_connect_log ORDER BY time_start_us DESC LIMIT 10;
结果如下图:

如果 connect_error 不为null 说明配置 监控账号失败 请检查监控账号是否正确
设置数据库版本和语法兼容
set mysql-server_version='8.0.21'; #设置数据库版本 如果不设置使用druid连接的时候会出现问题
set mysql-set_query_lock_on_hostgroup=0; # 设置语法兼容 如果不配置使用数据库连接工具比如说navicat 连接执行一些特殊查询比如说select @@version 就会提示语法不兼容
加载到配置到内存
load mysql users to runtime;
load mysql servers to runtime;
load mysql query rules to runtime;
load mysql variables to runtime;
load admin variables to runtime;
写入配置到硬盘
save mysql users to disk;
save mysql servers to disk;
save mysql query rules to disk;
save mysql variables to disk;
save admin variables to disk;
建议每次修改完配置都执行一遍
接下来关闭从数据库的数据复制 在所有从数据库 执行
stop slave # 接着上篇 关闭主从复制
登录到proxysql 客户端 可以使用数据库连接工具登录也可以使用mysql客户端登录
mysql -uproxysql -pjishuzhai -h127.0.0.1 -P6033 --default-auth=mysql_native_password
show databaases; #登录后执行 显示所有数据
出现如下图:
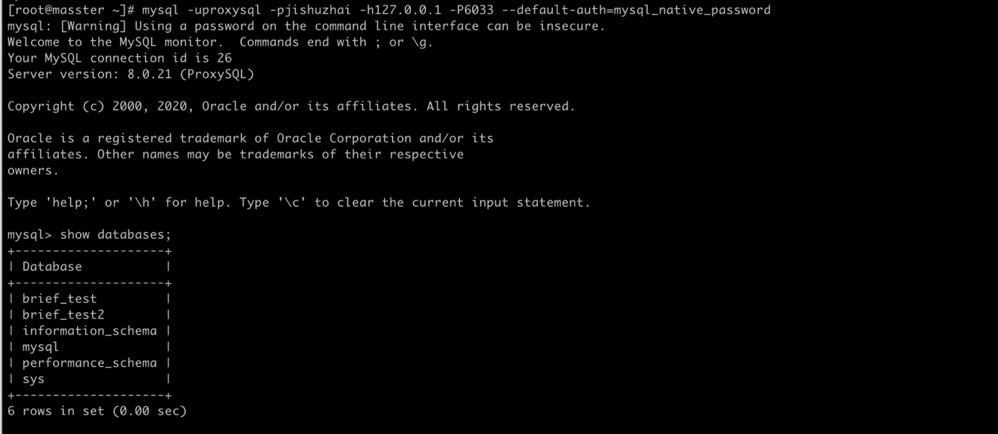
出现这个结果说明配置成功了。
测试读写分离路由规则
1.添加一条数据 然后查询看结果
INSERT INTO `test` VALUES (4, 'master4');
如下图:
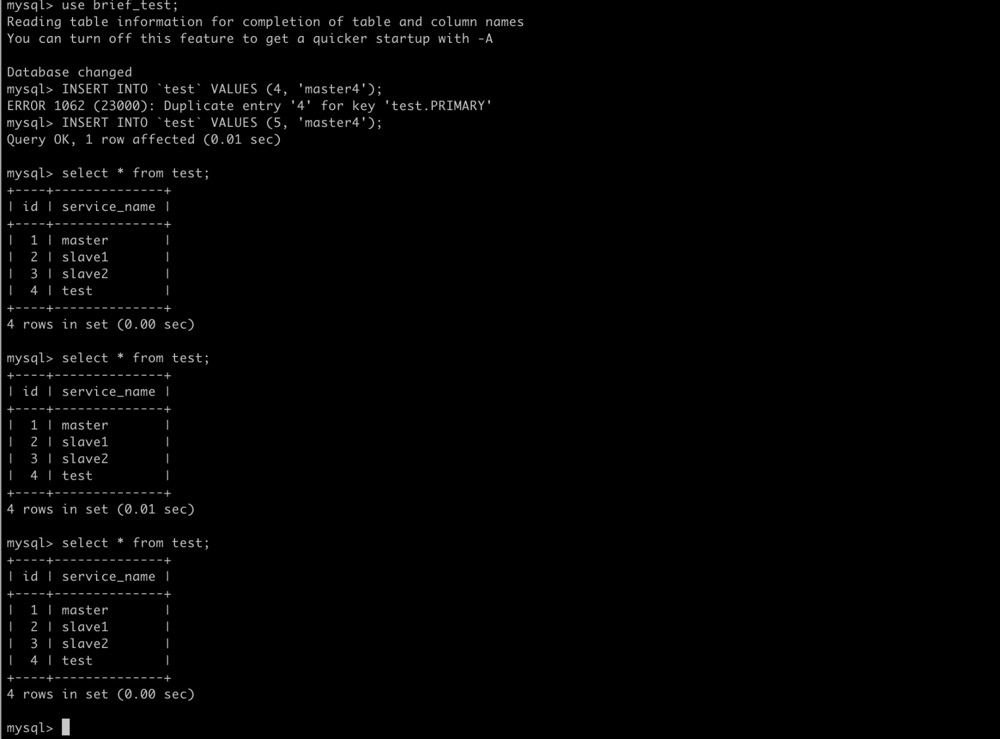
我添加了一条数据成功了 但是查询看不到结果 然后我们单独登录master数据 也就是hostgroup_id 为 1的数据实例查看 结果如下图:
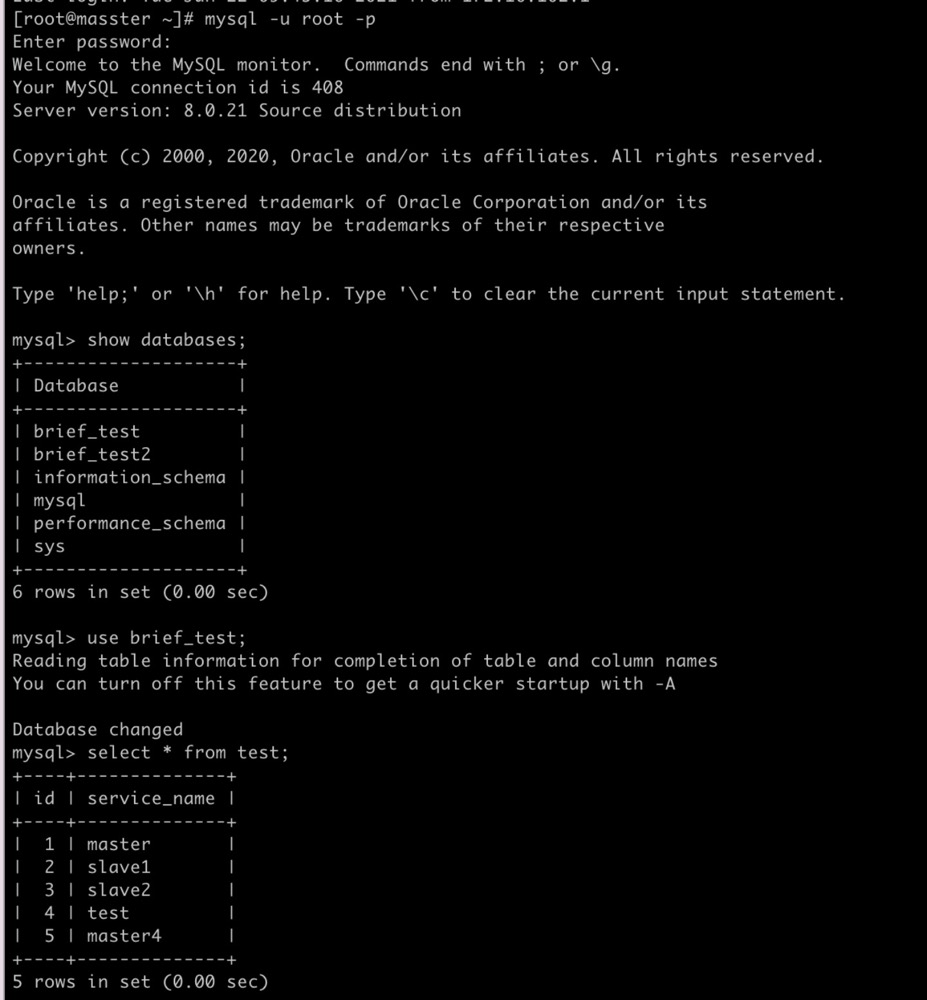
结果有五条数据 说明读写分离是配置成功了
现在我们在做一个实验 更换主数据库 把从数据库 slave1 设置为主数据库
登录proxysql 管理端
mysql -uadmin -padmin -h127.0.0.1 -P6032 --prompt='Admin> ' --default-auth=mysql_native_password
1.更新mysql_servers 表 将master 的 hostgroup_id 更新为 2, 将slave1 的hostgroup_id 更新为3
2.更新mysql_users 表 将 default_hostgroup 更新为3
3.更新mysql_query_rules 表 将 destination_hostgroup 更新为 3
4.然后加载到内存中
update mysql_servers set hostgroup_id = 2 where comment = 'master'; update mysql_servers set hostgroup_id = 3 where comment = 'slave1'; update mysql_users set default_hostgroup = 3; update mysql_query_rules set destination_hostgroup = 3 where rule_id =1;
load mysql users to runtime;
load mysql servers to runtime;
load mysql query rules to runtime;
save mysql users to disk;
save mysql servers to disk;
save mysql query rules to disk;
登录客户端测试 结果如下图:

插入 slave6 插入成功了 但是查询的结果一个是5条记录 一个是4条记录 分别对应之前master数据 和 slave2 数据库
登录到我们刚才设置为主库的slave1数据库实例插入 结果如下图:
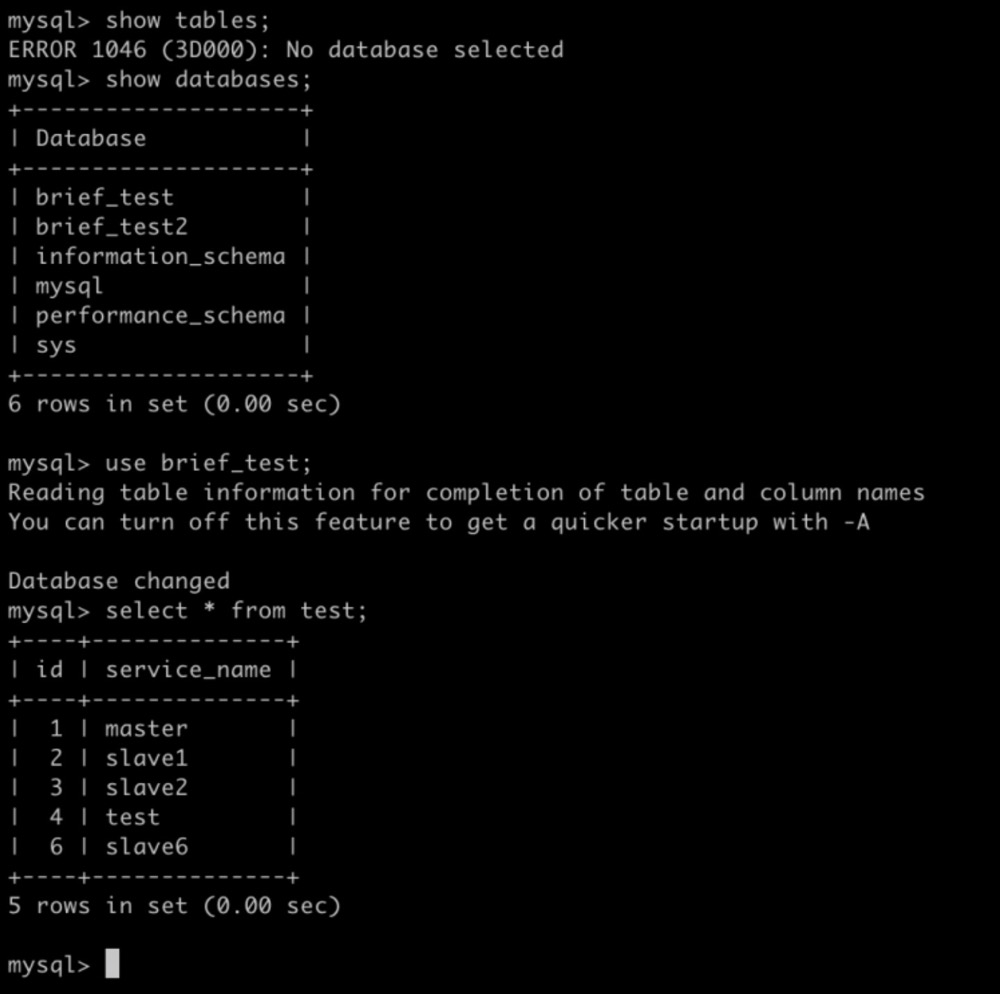
Slave6 这条记录在slave1的实例上 说明我们切换主数据库成功了
做这个实验是想说明 proxysql的主数据库 是通过 mysql_user 用户表 和mysql_query_rules 路由规则表结合配置的。
开发中注意的事项:
proxysql 关于一主多从数据库的配置实验结果
1.transaction_persistent必须设置为1
2.必须开启事物
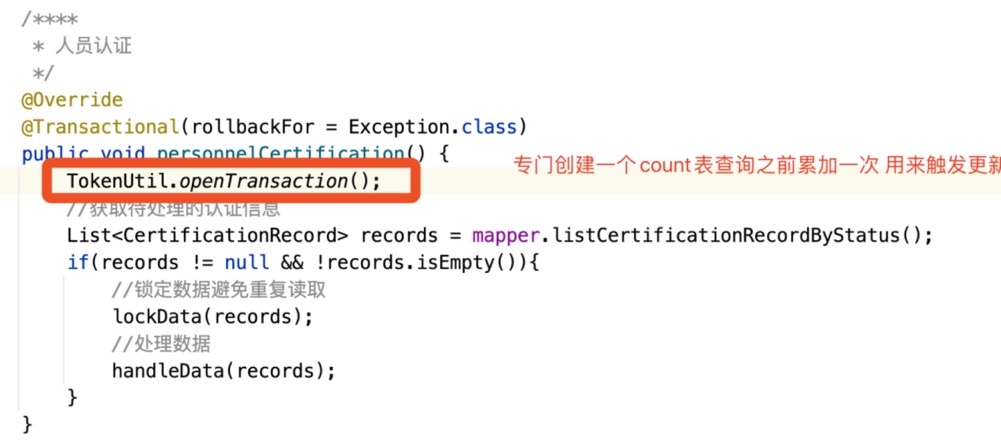
3.更新或修改方法在前 查询会路由到主库
4.如果查询方法在前 更新方法在后那么查询将路由到从库 出现脏读。
我针对查询方法在前 更新方法在后这种情况单独写一个更新操作的方法并且封装为静态方法 在查询之前先调用一次更新操作 然后在查询 在更新 如下图:
Centos8.3、proxysql2.0读写分离实战记录的更多相关文章
- Amoeba-mysql读写分离实战
Amoeba-mysql读写分离实战 Amoeba用途有很多,这里看标题我们就先说读写分离,因为我也只会这个.Amoeba定义为国内的,开源的.目前(2015年10月20日)我们用amoeba2.2版 ...
- ProxySQL+Mysql实现数据库读写分离实战
ProxySQL介绍 ProxySQL是一个高性能的MySQL中间件,拥有强大的规则引擎.具有以下特性:http://www.proxysql.com/ 1.连接池,而且是multiplexing 2 ...
- 构建高性能web之路------mysql读写分离实战(转)
一个完整的mysql读写分离环境包括以下几个部分: 应用程序client database proxy database集群 在本次实战中,应用程序client基于c3p0连接后端的database ...
- mysql读写分离实战
一个完整的MySQL读写分离环境包括以下几个部分: 应用程序client database proxy database集群 在本次实战中,应用程序client基于c3p0连接后端的database ...
- Windows环境下Mysql 5.7读写分离简单记录
一.目的 本文记录了在Windows环境中,mysql数据库读写分离配置过程. 二.准备: Master机器:Windows 10 虚拟机,IP:192.168.3.32 Slave机器:Window ...
- SpringBoot + MyBatis + MySQL 读写分离实战
1. 引言 读写分离要做的事情就是对于一条SQL该选择哪个数据库去执行,至于谁来做选择数据库这件事儿,无非两个,要么中间件帮我们做,要么程序自己做.因此,一般来讲,读写分离有两种实现方式.第一种是依靠 ...
- 构建高性能web之路------mysql读写分离实战
http://blog.csdn.net/cutesource/article/details/5710645 http://www.jb51.net/article/38953.htm http:/ ...
- ProxySQL实现Mysql读写分离 - 部署手册
ProxySQL是一个高性能的MySQL中间件,拥有强大的规则引擎.ProxySQL是用C++语言开发的,也是percona推的一款中间件,虽然也是一个轻量级产品,但性能很好(据测试,能处理千亿级的数 ...
- Windows环境下Mysql 5.7读写分离之使用mysql-proxy练习篇
本文使用mysql-proxy软件,结合mysql读写分离,实现实战练习. 前期准备: 三台机器: 代理机,IP:192.168.3.33 mysql Master,IP:192.168.3.32 m ...
随机推荐
- Win10安装MySQL5和MySQL8
1. 下载数据库,配置环境变量 因为是安装两个MySQL数据库,端口号要不一样,MySQL默认端口号是3306,建议先配置非默认端口号,以免出现问题 1.1 官网下载5.7和8.0的压缩包 我下载的是 ...
- 微信小程序中的常见弹框
显示加载中的提示框 wx.showLoading() 当我们正在在进行网络请求时,常常就需要这个提示框 手动调用wx.hideLoading()方法才能够关闭这个提示框,通常在数据请求完毕时就应该关闭 ...
- Codeforces Round #661 (Div. 3)
A. Remove Smallest 题意:数组是否满足任意i,j保证|ai-aj|<=1,如果都可以满足,输出YES,否则输出NO 思路:直接排序遍历即可 代码: 1 #include< ...
- JVM虚拟机-垃圾回收机制与垃圾收集器概述
目录 前言 什么是垃圾回收 垃圾回收的区域 垃圾回收机制 流程 怎么判断对象已经死亡 引用计数法 可达性分析算法 不可达的对象并非一定会回收 关于引用 强引用(StrongReference) 软引用 ...
- 通过Dapr实现一个简单的基于.net的微服务电商系统(十一)——一步一步教你如何撸Dapr之自动扩/缩容
上一篇我们讲到了dapr提供的bindings,通过绑定可以让我们的程序轻装上阵,在极端情况下几乎不需要集成任何sdk,仅需要通过httpclient+text.json即可完成对外部组件的调用,这样 ...
- C++ primer plus读书笔记——第1章 预备知识
第1章 预备知识 1. Ritchie希望有一种语言能将低级语言的效率.硬件访问能力和高级语言的通用性.可移植性融合在一起,于是他在旧语言的基础上开发了C语言. 2. 在C++获得一定程度的成功后,S ...
- 面向对象JML系列作业总结
面向对象JML系列作业总结 一.综述 本单元作业,由简到难地迭代式实现了三种JML需求,主要学习了面向规格的编程方法. 第一次:实现Path类和PathContainer类 第二次:继承PathCon ...
- ALPHA任务拆解
项目 内容 这个作业属于哪个课程 BUAA2020软件工程 这个作业的要求在哪里 作业要求 我们在这个课程的目标是 学会团队合作,共同开发一个完整的项目 这个作业在哪个具体方面帮助我们实现目标 团队任 ...
- 5分钟让你理解K8S必备架构概念,以及网络模型(中)
写在前面 在这用XMind画了一张导图记录Redis的学习笔记和一些面试解析(源文件对部分节点有详细备注和参考资料,欢迎关注我的公众号:阿风的架构笔记 后台发送[导图]拿下载链接, 已经完善更新): ...
- [Linux] Shell 脚本实例(超实用)
文件操作 为文件(test.sh)增加执行权限 chmod +x test.sh 列出当前文件夹下所有文件(每行输出一个) 1 #!/bin/bash 2 dir=`ls ./` 3 for i in ...