14-2-Unsupervised Learning ----Word Embedding
Introduction
词嵌入(word embedding)是降维算法(Dimension Reduction)的典型应用
那如何用vector来表示一个word呢?
1-of-N Encoding
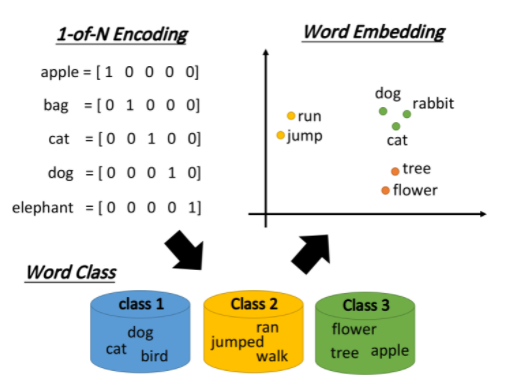
最传统的做法是1-of-N Encoding,假设这个vector的维数就等于世界上所有单词的数目,那么对每一个单词来说,只需要某一维为1,其余都是0即可;但这会导致任意两个vector都是不一样的,你无法建立起同类word之间的联系
Word Class
还可以把有同样性质的word进行聚类(clustering),划分成多个class,然后用word所属的class来表示这个word,但光做clustering是不够的,不同class之间关联依旧无法被有效地表达出来
Word Embedding
词嵌入(Word Embedding)把每一个word都投影到高维空间上,当然这个空间的维度要远比1-of-N Encoding的维度低,假如后者有10w维,那前者只需要50~100维就够了,这实际上也是Dimension Reduction的过程
类似语义(semantic)的词汇,在这个word embedding的投影空间上是比较接近的,而且该空间里的每一维都可能有特殊的含义
假设词嵌入的投影空间如下图所示,则横轴代表了生物与其它东西之间的区别,而纵轴则代表了会动的东西与静止的东西之间的差别
怎么做Word Embedding?
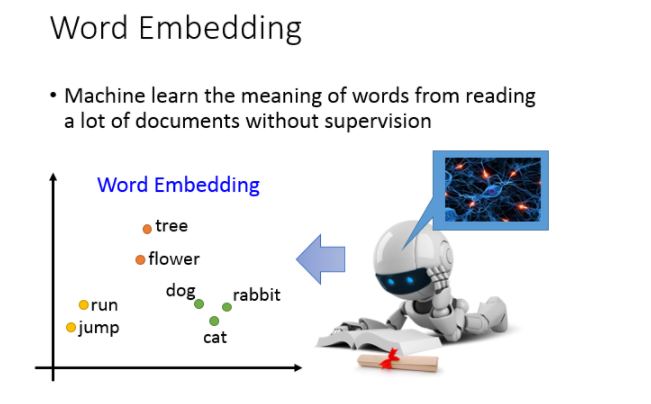
那怎么做word Embedding呢?word Embedding是Unsupervised 。我们怎么让machine知道每一个词汇的含义是什么呢,你只要透过machine阅读大量的文章,它就可以知道每一个词汇它的embeding feature vector应该长什么样子。
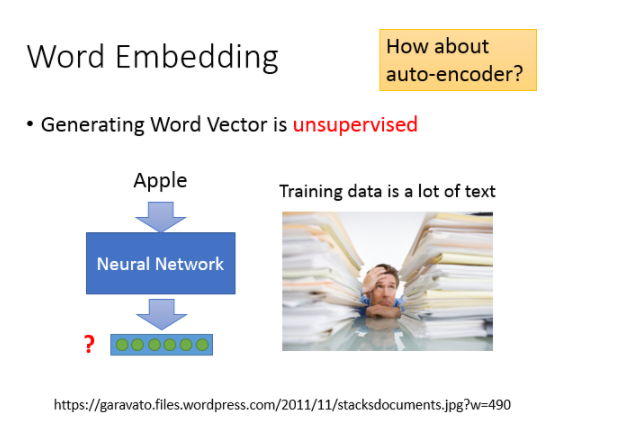
word embedding是一个无监督的方法(unsupervised approach),只要让机器阅读大量的文章,它就可以知道每一个词汇embedding之后的特征向量应该长什么样子。
我们的任务就是训练一个neural network,input是词汇,output则是它所对应的word embedding vector,实际训练的时候我们只有data的input,该如何解这类问题呢?
之前提到过一种基于神经网络的降维方法,Auto-encoder,就是训练一个model,让它的输入等于输出,取出中间的某个隐藏层就是降维的结果,自编码的本质就是通过自我压缩和解压的过程来寻找各个维度之间的相关信息;但word embedding这个问题是不能用Auto-encoder来解的,因为输入的向量通常是1-of-N编码,各维无关,很难通过自编码的过程提取出什么有用信息。
Word Embedding
basic idea
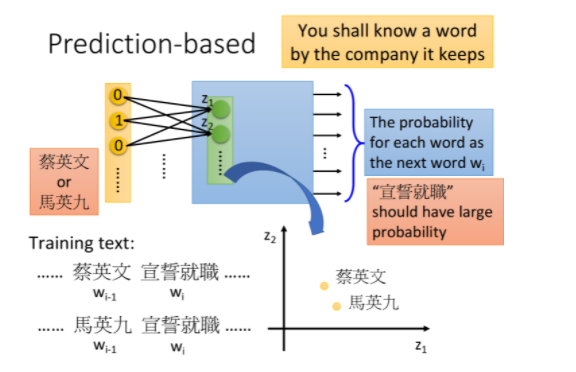
基本精神就是,每一个词汇的含义都可以根据它的上下文来得到
比如机器在两个不同的地方阅读到了“马英九520宣誓就职”、“蔡英文520宣誓就职”,它就会发现“马英九”和“蔡英文”前后都有类似的文字内容,于是机器就可以推测“马英九”和“蔡英文”这两个词汇代表了可能有同样地位的东西,即使它并不知道这两个词汇是人名

怎么用这个思想来找出word embedding的vector呢?有两种做法:
- Count based
- Prediction based
Count based

Prediction based
how to do perdition
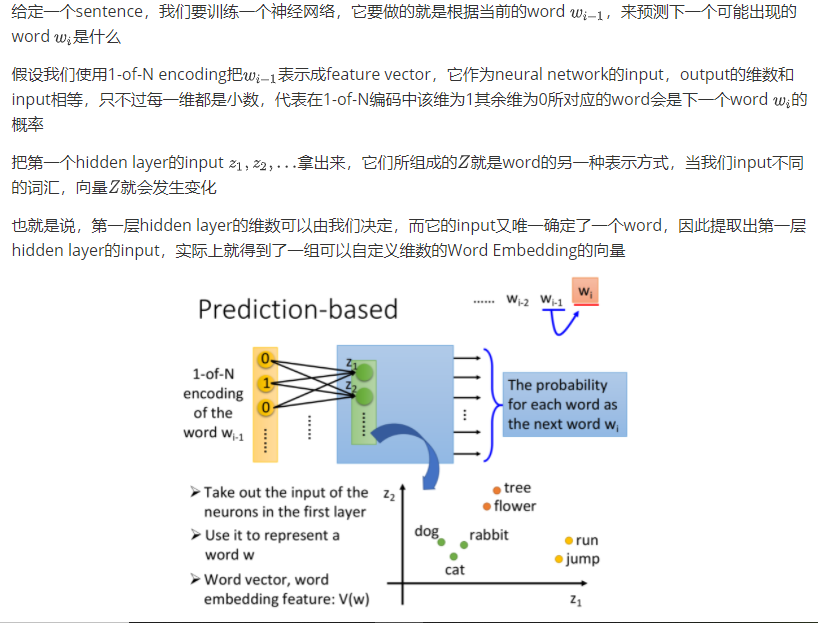
Why prediction works

Sharing Parameters
14-2-Unsupervised Learning ----Word Embedding的更多相关文章
- Unsupervised Learning: Use Cases
Unsupervised Learning: Use Cases Contents Visualization K-Means Clustering Transfer Learning K-Neare ...
- Unsupervised Learning and Text Mining of Emotion Terms Using R
Unsupervised learning refers to data science approaches that involve learning without a prior knowle ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
- 建模角度理解word embedding及tensorflow实现
http://www.jianshu.com/p/d44ce1e3ec2f 1. 前言 本篇主要介绍关键词的向量表示,也就是大家熟悉的word embedding.自Google 2013 年开源wo ...
- Word Embedding与Word2Vec
http://blog.csdn.net/baimafujinji/article/details/77836142 一.数学上的“嵌入”(Embedding) Embed这个词,英文的释义为, fi ...
- DeepNLP的核心关键/NLP词的表示方法类型/NLP语言模型 /词的分布式表示/word embedding/word2vec
DeepNLP的核心关键/NLP语言模型 /word embedding/word2vec Indexing: 〇.序 一.DeepNLP的核心关键:语言表示(Representation) 二.NL ...
- [DeeplearningAI笔记]序列模型2.1-2.2词嵌入word embedding
5.2自然语言处理 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.1词汇表征 Word representation 原先都是使用词汇表来表示词汇,并且使用1-hot编码的方式来表示词汇 ...
- Unsupervised learning, attention, and other mysteries
Unsupervised learning, attention, and other mysteries Get notified when our free report “Future of M ...
- 无监督学习(Unsupervised Learning)
无监督学习(Unsupervised Learning) 聚类无监督学习 特点 只给出了样本, 但是没有提供标签 通过无监督学习算法给出的样本分成几个族(cluster), 分出来的类别不是我们自己规 ...
随机推荐
- Docker里面没有你期望的命令、甚至没有yum怎么办?
分享小知识点 跟大家分享一个实用的小知识点 有时候在docker容器里面不仅没有你期望的那些常用的命令,甚至没有yum命令让你去安装那些常用的命令 怎么办呢?不要慌! 没有yum命令说明这个容器的系统 ...
- heoi2020信号传递
状压dp 我状压学得是真烂..... 考试的时候想了状压,可是一直都是在枚举位置,没有神魔实质性突破.其实这道题的关键瓶颈也在于此,状压压的是号,而不是位置.如果 $i<=j$ 那么贡献为 $j ...
- Serverless 对研发效能的变革和创新
作者 | 杨皓然(不瞋) 对企业而言,Serverless 架构有着巨大的应用潜力.随着云产品的完善,产品的集成和被集成能力的加强,软件交付流程自动化能力的提高,我们相信在 Serverless 架构 ...
- jenkins+allure中测试包括为空,没有数据
- 攻防世界XCTF-WEB入门全通关
为了更好的体验,请见我的---->个人博客 XCTF的web块入门区非常简单,适合一些刚接触安全或者对网络安全常识比较了解的同学在安全搞累之余娱乐娱乐. 其主要考察下面几点: 基本的PHP.Py ...
- 分享一份软件测试项目实战(web+app+h5+小程序)
大家好,我是谭叔. 本次,谭叔再度出马,给大家找了一个非常适合练手的软件测试项目,此项目涵盖web端.app端.h5端.小程序端,可以说非常之全面. 缘起 在这之前,谭叔已经推出了九套实战教程. 但是 ...
- BUAA 软工 结对项目作业
1.相关信息 Q A 这个作业属于哪个课程 2020春季计算机学院软件工程(罗杰 任健) 这个作业的要求在哪里 结对项目作业 我在这个课程的目标是 系统地学习软件工程开发知识,掌握相关流程和技术,提升 ...
- Noip模拟53 2021.9.14
T1 ZYB和售货机 首先这道题有两种做法. 一种是发现每个点都可以先被取到只剩一个,只要收益大于$0$ 然后发现建一个$i->f[i]$的图时出现环,要把它去掉, 那么跑一个$tarjan$枚 ...
- python2和python3并存下的pip使用
py -2 -m pip install *.whl py -3 -m pip intall *.wl
- Python课程笔记(十)
不陌生,之前学习一个开源SpringBoot项目,Mysql5.5更换到5.7搞得头疼. 数据库连接的坑之前写的IDEA系列连接会遇到的问题.课程代码 今天上课就主要学习了python如何连接mysq ...