SpringCloud升级之路2020.0.x版-10.使用Log4j2以及一些核心配置

本系列代码地址:https://github.com/HashZhang/spring-cloud-scaffold/tree/master/spring-cloud-iiford

我们使用 Log4j2 异步日志配置,防止日志过多的时候,成为性能瓶颈。这里简单说一下 Log4j2 异步日志的原理:Log4j2 异步日志基于高性能数据结构 Disruptor,Disruptor 是一个环形 buffer,做了很多性能优化(具体原理可以参考我的另一系列:高并发数据结构(disruptor)),Log4j2 对此的应用如下所示:
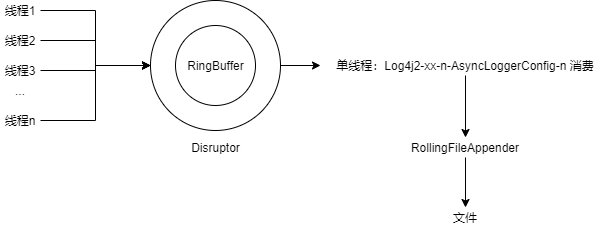
简单来说,多线程通过 log4j2 的门面类 org.apache.logging.log4j.Logger 进行日志输出,被封装成为一个 org.apache.logging.log4j.core.LogEvent,放入到 Disruptor 的环形 buffer 中。在消费端有一个单线程消费这些 LogEvent 写入对应的 Appender.
这里我们给出一个我们日志配置的模板,供大家参考:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<Properties>
<Property name="springAppName">app名称</Property>
<Property name="LOG_ROOT">log</Property>
<Property name="LOG_DATEFORMAT_PATTERN">yyyy-MM-dd HH:mm:ss.SSS</Property>
<Property name="LOG_EXCEPTION_CONVERSION_WORD">%xwEx</Property>
<!--对于日志级别,为了日志能对齐好看,我们占 5 个字符-->
<Property name="LOG_LEVEL_PATTERN">%5p</Property>
<Property name="logFormat">
%d{${LOG_DATEFORMAT_PATTERN}} ${LOG_LEVEL_PATTERN} [${springAppName},%X{traceId},%X{spanId}] [${sys:PID}] [%t][%C:%L]: %m%n${sys:LOG_EXCEPTION_CONVERSION_WORD}
</Property>
</Properties>
<appenders>
<RollingFile name="file" append="true"
filePattern="${LOG_ROOT}/app.log-%d{yyyy.MM.dd.HH}"
immediateFlush="false">
<PatternLayout pattern="${logFormat}"/>
<Policies>
<TimeBasedTriggeringPolicy interval="1" modulate="true"/>
</Policies>
<DirectWriteRolloverStrategy maxFiles="72"/>
</RollingFile>
</appenders>
<loggers>
<!--default logger -->
<Asyncroot level="info" includeLocation="true">
<appender-ref ref="file" />
</Asyncroot>
<AsyncLogger name="org.mybatis" level="off" additivity="false" includeLocation="false">
<appender-ref ref="file"/>
</AsyncLogger>
</loggers>
</configuration>
对于其中一些重要的配置,我们这里单独拿出来分析下。

我们项目的依赖中包含了 spring-cloud-sleuth 这个链路追踪相关的依赖,其核心基于 Opentracing 标准实现。日志中可以通过打印 Span 的 SpanContext 中的 traceId 以及 spanId,就能通过这些信息,确定日志中的一条完整链路。spring-cloud-sleuth 是如何将这些信息放入日志中的呢? Log4j2 中有这样一个抽象,即 org.apache.logging.log4j.ThreadContext,这个其实就是 Java 日志中 MDC(Mapped Diagnostic Context)的实现,可以理解成是一个线程本地的 Map,每个线程可以将日志需要的元素放入这个 ThreadContext 中,这样这个线程在打印日志的时候,就可以从这个 ThreadContext 中取出放入日志内容。日志需要有对应的占位符,例如下面这个就是将 ThreadContext 中 key 为 traceId 以及 spanId 的值取出输出:
%X{traceId},%X{spanId}
Spring Cloud 2020.0.x 之后,也就是 spring-cloud-sleuth 3.0.0 之后,放入 ThreadContext 的 key 发生了变化,原来的 traceId 与 spanId 分别是 X-B3-traceId 与 X-B3-spanId,现在改成了更为通用的 traceId 和 spanId。

这个主要因为你打日志的地方不在 spring-cloud-sleuth 管理的范围内,或者是 Span 提前结束了。这种时候,你可以在确定有 Span 的地方将 Span 缓存起来,之后再没有链路追踪信息的地方使用这个 Span,例如:
import brave.Tracer;
@Autowire
private Tracer tracer;
//在确定有 span 的地方获取当前 span 将 span 缓存起来
Span span = tracer.currentSpan();
//之后在没有链路追踪信息的地方,使用 span 包裹起来
try (Tracer.SpanInScope cleared = tracer.withSpanInScope(span)) {
//你的业务代码
}

设置 includeLocation=false,这样在日志中就无法看到日志属于的代码以及行数了。获取这个代码行数,其实是通过获取当前调用堆栈实现的。Java 9 之前是通过 new 一个 Exception 获取堆栈,Java 9 之后是通过 StackWalker。两者其实都有性能问题,在高并发的情况下,会吃掉很多 CPU,得不偿失。所以我推荐,在日志内容中直接体现所在代码行数,就不通过这个 includeLocation 获取当前堆栈从而获取代码行数了。

关闭 immediateFlush,可以减少硬盘 IO,会先写入内存 Buffer(默认是 8 KB),之后在 RingBuffer 目前消费完或者 Buffer 写满的时候才会刷盘。这个 Buffer 可以通过系统变量 log4j.encoder.byteBufferSize 改变。
这里的原理对应源码:
AbstractOutputStreamAppender.java
protected void directEncodeEvent(final LogEvent event) {
getLayout().encode(event, manager);
//如果配置了 immdiateFlush (默认为 true)或者当前事件是 EndOfBatch
if (this.immediateFlush || event.isEndOfBatch()) {
manager.flush();
}
}
那么对于 Log4j2 Disruptor 异步日志来说,什么时候 LogEvent 是 EndOfBatch 呢?是在消费到的 index 等于生产发布到的最大 index 的时候,这也是比较符合性能设计考虑,即在没有消费完的时候,尽可能地不 flush,消费完当前所有的时候再去 flush:
private void processEvents()
{
T event = null;
long nextSequence = sequence.get() + 1L;
while (true)
{
try
{
final long availableSequence = sequenceBarrier.waitFor(nextSequence);
if (batchStartAware != null)
{
batchStartAware.onBatchStart(availableSequence - nextSequence + 1);
}
while (nextSequence <= availableSequence)
{
event = dataProvider.get(nextSequence);
//这里 nextSequence == availableSequence 就是 EndOfBatch
eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence);
nextSequence++;
}
sequence.set(availableSequence);
}
catch (final TimeoutException e)
{
notifyTimeout(sequence.get());
}
catch (final AlertException ex)
{
if (running.get() != RUNNING)
{
break;
}
}
catch (final Throwable ex)
{
exceptionHandler.handleEventException(ex, nextSequence, event);
sequence.set(nextSequence);
nextSequence++;
}
}
}

我们这一节详细分析了我们微服务框架中日志相关的各种配置,包括基础配置,链路追踪实现与配置以及如果没有链路追踪信息时候的解决办法,并且针对一些影响性能的核心配置做了详细说明。下一节我们将会开始分析针对日志的 RingBuffer 进行的监控。
微信搜索“我的编程喵”关注公众号,每日一刷,轻松提升技术,斩获各种offer:

SpringCloud升级之路2020.0.x版-10.使用Log4j2以及一些核心配置的更多相关文章
- SpringCloud升级之路2020.0.x版-1.背景
本系列为之前系列的整理重启版,随着项目的发展以及项目中的使用,之前系列里面很多东西发生了变化,并且还有一些东西之前系列并没有提到,所以重启这个系列重新整理下,欢迎各位留言交流,谢谢!~ Spring ...
- SpringCloud升级之路2020.0.x版-41. SpringCloudGateway 基本流程讲解(1)
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 接下来,将进入我们升级之路的又一大模块,即网关模块.网关模块我们废弃了已经进入维护状态的 ...
- SpringCloud升级之路2020.0.x版-6.微服务特性相关的依赖说明
本系列代码地址:https://github.com/HashZhang/spring-cloud-scaffold/tree/master/spring-cloud-iiford spring-cl ...
- SpringCloud升级之路2020.0.x版-43.为何 SpringCloudGateway 中会有链路信息丢失
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 在开始编写我们自己的日志 Filter 之前,还有一个问题我想在这里和大家分享,即在 Sp ...
- SpringCloud升级之路2020.0.x版-5.所有项目的parent与spring-framework-common说明
本系列代码地址:https://github.com/HashZhang/spring-cloud-scaffold/tree/master/spring-cloud-iiford 源代码文件:htt ...
- SpringCloud升级之路2020.0.x版-11.Log4j2 监控相关
本系列代码地址:https://github.com/HashZhang/spring-cloud-scaffold/tree/master/spring-cloud-iiford Log4j2 异步 ...
- SpringCloud升级之路2020.0.x版-13.UnderTow 核心配置
本系列代码地址:https://github.com/HashZhang/spring-cloud-scaffold/tree/master/spring-cloud-iiford Undertow ...
- SpringCloud升级之路2020.0.x版-20. 启动一个 Eureka Server 集群
本系列代码地址:https://github.com/HashZhang/spring-cloud-scaffold/tree/master/spring-cloud-iiford 我们的业务集群结构 ...
- SpringCloud升级之路2020.0.x版-42.SpringCloudGateway 现有的可供分析的请求日志以及缺陷
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 网关由于是所有外部用户请求的入口,记录这些请求中我们需要的元素,对于线上监控以及业务问题定 ...
随机推荐
- 18、linux文件属性
文件的描述信息: [root@centos6 /]# ls -lih 总用量 118K 3538945 drwxr-xr-x 3 root root 4.0K 8月 23 17:12 app 3276 ...
- .net获取项目根目录方法集合
这篇文章是别的博客复下来,收藏的: 编写程序的时候,经常需要用的项目根目录.自己总结如下 1.取得控制台应用程序的根目录方法 方法1.Environment.CurrentDirectory ...
- bootstrap validate 验证插件 动态添加和动态删除验证项
//添加验证项 function addField(field, notEmptyMsg, othercon) { if (!othercon) { $("#gyssave").b ...
- Html:行级元素和块级元素标签列表
块级元素 div p h1-h6 form ul ol dl dt dd li table tr td th hr blockquote address table menu pre HTML5: h ...
- Linux:Ubuntu银河麒麟防火墙操作
查看防火墙状态 #防火墙状态 sudo ufw status inactive状态是防火墙 关闭 状态 active状态是防火墙 开启 状态 开启防火墙 #开启防火墙 sudo ufw enable ...
- Vue3 + TypeScript 开发实践总结
前言 迟来的Vue3文章,其实早在今年3月份时就把Vue3过了一遍.在去年年末又把 TypeScript 重新学了一遍,为了上 Vue3 的车,更好的开车.在上家公司4月份时,上级领导分配了一个内部的 ...
- Acunetix引入了Docker支持,扫描统计信息以及将漏洞发送到AWS WAF的功能
已针对Windows,Linux和macOS发布了新的Acunetix更新:14.2.210503151. 此Acunetix更新引入了Docker支持,针对每次扫描显示的新"扫描统计信息& ...
- WPF教程八:如何更好的使用Application程序集资源
这一篇单独拿出来分析这个程序集资源,为的就是不想让大家把程序集资源和exe程序强关联,因为程序集资源实际上是二进制资源,后续编译过程中会被嵌入到程序集中,而为了更方便的使用资源,我们要好好梳理一下程序 ...
- cron表达式详解(转)
Cron表达式是一个字符串,字符串以5或6个空格隔开,分为6或7个域,每一个域代表一个含义,Cron有如下两种语法格式: (1) Seconds Minutes Hours DayofMonth Mo ...
- Luogu P2754 星际转移问题
Luogu P2754 星际转移问题 思路 首先,对于地球能否到达月球的问题,考虑使用并查集维护. 对于每艘飞船能够到达的站点,放进一个集合里,若两艘飞船的集合有交集,那么就合并两个集合,最后只要地球 ...