ubuntu下hadoop完全分布式部署
三台机器分别命名为:
hadoop-master ip:192.168.0.25
hadoop-slave1 ip:192.168.0.26
hadoop-slave2 ip:192.168.0.27
部署前的基本准备:三台机器共同的用户hadoop,三台机器已经设置好静态ip且能互相ping通,三台机器的jdk已经安装好,路径最好一样。
大概流程:
1、修改主机名并在各个机器的/etc/hosts中相互添加ip和主机名
2、每台机器安装ssh,并实现master主机到slave主机无密码登录
3、hadoop安装和配置,记住路径要一样,最好都是/home/hadoop/xxxx
4、从master启动hadoop
一、修改主机名
1)设置静态ip,参照http://www.cnblogs.com/jhldreams/p/4161123.html
2)修改主机名
sudo gedit /etc/hostname (先修改hostname) sudo gedit /etc/hosts (在hosts文档中加入相应ip和对应主机)
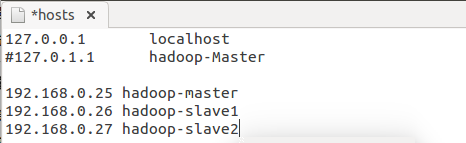
这个是master机器上面的hosts,在两个slave里面也是一样
有的时候修改了这两个你仍然会看到使用的命令行名字不是你修改的,可以su获取root权限,然后hostname xxxx,这样退出terminal后再次进入就会发现名字已经改过来了
二、安装ssh并设置免密码登录
sudo apt-get install ssh
安装完了后设置密码
$ssh-keygen -t rsa(执行完本条命令后一直回车) $cd .ssh (进入.ssh目录) $cp id_rsa.pub authorized_keys (到此处已经可以免密码登录本机,ssh localhost可测试)
以上每台机器都做一遍,不过需要master主机能够免密码登录slave主机,还需要将master的公钥复制到两个slave节点的公钥中去,在master上执行命令:
$scp authorized_keys 从节点主机名@名字(如hadoop@hadoop-slave1):/home/hadoop/.ssh。 虽然公钥都弄好了,但是需要权限,你可以设置777权限,不过644权限就已经够了,在所有主机中将authorized)_keys文件的许可权限改为644
$chmod authorized_keys 这时可以从master向slave主机发起ssh连接,需要输入yes的地方输入yes,可能第一次连接时候仍然需要输入一次密码。 以上实现了从master主机访问slave主机免密码登录问题
三、在所有机器安装hadoop并配置hadoop
我用的是hadoop-1.2.1版本
去官网下载hadoop-1.2.1的tar的包
$tar zxvf xxxx.tar.gz
我没用sudo解压,因为linux下的权限问题真的把我搞怕了,我的hadoop是安装在home文件下的,包括jdk的解压,都没用sudo
解压好之后,主要配置hadoop文件夹下conf中的hadoop-env.sh,core-site.xml,mapred-site.xml,hdfs-site.xml三个文件
hadoop-env.sh中主要找到JAVA_HOME那一行,去掉#号,并且把路径填写为自己的jdk路径
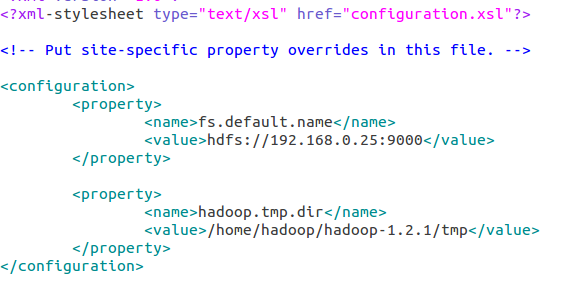
core-site.xml
配置hadoop.tmp.dir的原因是为了避免重复格式化hdfs文件系统,如果没有配置hadoop.tmp.dir参数,此时系统默认的临时目录为:/tmp/hadoo-hadoop。而这个目录在每次重启后都会被删掉,必须重新执行format才行,否则会出错
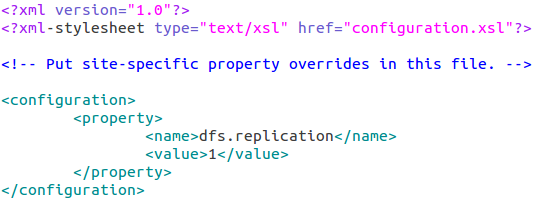
hdfs-site.xml
replication 是数据副本数量,默认为3,salve少于3台就会报错
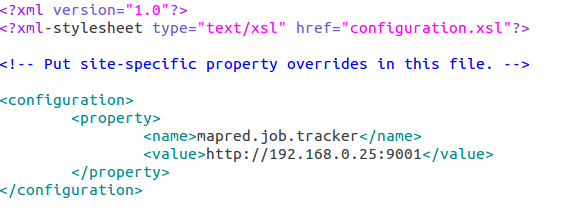
mapred-site.xml
以上做好后,开始在master主机上配置masters文件和slaves文件
$cd hadoop-1.2./conf
$sudo gedit masters
修改内容为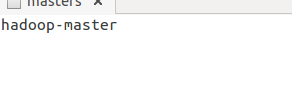 当然也可以写成之前规定的静态ip192.168.0.25
当然也可以写成之前规定的静态ip192.168.0.25
配置slaves文件内容为:

到此位置,master主机上面的配置已经完成了,slave主机和此配置基本一样,可以直接从master主机拷贝hadoop文件夹过去(这样的话slave主机没必要提前下载hadoop)
$scp -r hadoop-1.2. hadoop@hadoop-slave1:/home/hadoop
slave2一样执行如此命令
四、启动
第一次启动需要格式化分布式文件系统,后来就不需要了
先进入到hadoop文件夹下
$cd hadoop-1.2.
$bin/hadoop namenode -format(格式化)
启动
$cd hadoop-1.2.
$bin/start-all.sh
可以用jps命令查看运行的进程情况
至此,hadoop完全分布式已经安装成功
ubuntu下hadoop完全分布式部署的更多相关文章
- Ubuntu下Zabbix服务器监控工具部署
Ubuntu下Zabbix服务器监控工具部署 一 安装安装Apache.Mysql.Php.zabbix sudo apt-get update sudo apt-get install apache ...
- Ubuntu下hadoop环境的搭建(伪分布模式)
Ubuntu下hadoop环境的搭建(伪分布模式) 一.必要资源的下载 1.Java jdk(jdk-8u25-linux-x64.tar.gz)的下载 具体链接为: http://www.oracl ...
- CentOS7下Hadoop伪分布式环境搭建
CentOS7下Hadoop伪分布式环境搭建 前期准备 1.配置hostname(可选,了解) 在CentOS中,有三种定义的主机名:静态的(static),瞬态的(transient),和灵活的(p ...
- Hadoop 完全分布式部署
完全分布式部署Hadoop 分析: 1)准备3台客户机(关闭防火墙.静态ip.主机名称) 2)安装jdk 3)配置环境变量 4)安装hadoop 5)配置环境变量 6)安装ssh 7)集群时间同步 7 ...
- Hadoop 完全分布式部署(三节点)
用来测试,我在VMware下用Centos7搭起一个三节点的Hadoop完全分布式集群.其中NameNode和DataNode在同一台机器上,如果有条件建议大家把NameNode单独放在一台机器上,因 ...
- Hadoop学习---Ubuntu中hadoop完全分布式安装教程
软件版本 Hadoop版本号:hadoop-2.6.0-cdh5.7.0: VMWare版本号:VMware 9或10 Linux系统:CentOS 6.4-6.5 或Ubuntu版本号:ubuntu ...
- 超级无敌详细使用ubuntu搭建hadoop完全分布式集群
一.软件准备 安装VMware 下载ubuntu镜像(阿里源ubuntu下载地址)选择自己适合的版本,以下我使用的是18.04-server版就是没有桌面的.安装桌面版如果自己电脑配置不行的话启动集群 ...
- ubuntu下nginx+php5的部署
ubuntu下nginx+php5环境的部署和centos系统下的部署稍有不同,废话不多说,以下为操作记录:1)nginx安装root@ubuntutest01-KVM:~# sudo apt-get ...
- Ubuntu下Hadoop的安装和配置
最近又需要要搭hadoop环境,所以开始学习,下面是我的笔记,仅供大家参考! Hadoop安装: JDK1.6+ 操作系统:Linux,Window和Unix也可以做Hadoop的开发,只有Linux ...
随机推荐
- Gray Code 解答
Question The gray code is a binary numeral system where two successive values differ in only one bit ...
- pyqt menu子级方向例子学习
代码和UI文件:http://yunpan.cn/QCkXbX8mnSNke(提取码:51e1) 图片如: 代码如下: from PyQt4 import QtCore,QtGui,Qt import ...
- [转]Laravel 4之路由
Laravel 4之路由 http://dingjiannan.com/2013/laravel-routing/ Laravel 4路由是一种支持RESTful的路由体系, 基于symfony2的R ...
- 使用INTERVAL YEAR TO MONTH类型
Oracle Database 9i数据库引入了一种新特性,可以用来存储时间间隔.时间间隔的例子包括: ● 1年零3个月 ● 25个月 ● -3天5小时16分 ● 1天7小时 ● -56小时 注意: ...
- [汇编学习笔记][第十七章使用BIOS进行键盘输入和磁盘读写
第十七章 使用BIOS进行键盘输入和磁盘读写 17.1 int 9 中断例程对键盘输入的处理 17.2 int 16 读取键盘缓存区 mov ah,0 int 16h 结果:(ah)=扫描码,(al) ...
- html_day2
总结下今天学的HTML知识.单词 跑马灯标记 <marquee></marquee>属性: direction:滚动的方向 取值:left .right. up. down b ...
- spring mvc + mybatis + spring aop声明式事务管理没有作用
在最近的一个项目中,采用springMVC.mybatis,发现一个很恼人的问题:事务管理不起作用!!网上查阅了大量的资料,尝试了各种解决办法,亦未能解决问题! spring版本:3.0.5 myba ...
- js控制html5 audio的暂停、播放、停止
<!DOCTYPE HTML> <html> <head> <meta charset="utf-8"> <meta name ...
- web前端中实现多标签页切换的效果
在这里,实现多标签页效果的方法有两个,一个是基于DOM的,另一个是基于jquery的,此次我写的是一个对于一个电话套餐的不同,显示不同的标签页 方法一: 首先,我们要把页面的大体框架和样式写出来,ht ...
- Win8.1系统下安装nodeJS
Nodejs简介 Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境.Node.js 使用了一个事件驱动.非阻塞式 I/O 的模型,使其轻量又高效.Node.js ...