机器学习之主成分分析PCA原理笔记
1. 相关背景
在许多领域的研究与应用中,通常需要对含有多个变量的数据进行观测,收集大量数据后进行分析寻找规律。多变量大数据集无疑会为研究和应用提供丰富的信息,但是也在一定程度上增加了数据采集的工作量。更重要的是在很多情形下,许多变量之间可能存在相关性,从而增加了问题分析的复杂性。如果分别对每个指标进行分析,分析往往是孤立的,不能完全利用数据中的信息,因此盲目减少指标会损失很多有用的信息,从而产生错误的结论。
因此需要找到一种合理的方法,在减少需要分析的指标同时,尽量减少原指标包含信息的损失,以达到对所收集数据进行全面分析的目的。由于各变量之间存在一定的相关关系,因此可以考虑将关系紧密的变量变成尽可能少的新变量,使这些新变量是两两不相关的,那么就可以用较少的综合指标分别代表存在于各个变量中的各类信息。主成分分析与因子分析就属于这类降维算法。
2. 数据降维
降维就是一种对高维度特征数据预处理方法。降维是将高维度的数据保留下最重要的一些特征,去除噪声和不重要的特征,从而实现提升数据处理速度的目的。在实际的生产和应用中,降维在一定的信息损失范围内,可以为我们节省大量的时间和成本。降维也成为应用非常广泛的数据预处理方法。
降维具有如下一些优点:
- 使得数据集更易使用。
- 降低算法的计算开销。
- 去除噪声。
- 使得结果容易理解。
降维的算法有很多,比如奇异值分解(SVD)、主成分分析(PCA)、因子分析(FA)、独立成分分析(ICA)
3. PCA原理
3.1. PCA的概念
PCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法。PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。依次类推,可以得到n个这样的坐标轴。通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。
思考:我们如何得到这些包含最大差异性的主成分方向呢?
答案:事实上,通过计算数据矩阵的协方差矩阵,然后得到协方差矩阵的特征值特征向量,选择特征值最大(即方差最大)的k个特征所对应的特征向量组成的矩阵。这样就可以将数据矩阵转换到新的空间当中,实现数据特征的降维。
由于得到协方差矩阵的特征值特征向量有两种方法:特征值分解协方差矩阵、奇异值分解协方差矩阵,所以PCA算法有两种实现方法:基于特征值分解协方差矩阵实现PCA算法、基于SVD分解协方差矩阵实现PCA算法。
3.2 协方差和散度矩阵
样本均值:
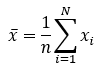
样本方差:
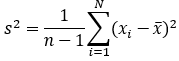
样本X和样本Y的协方差:
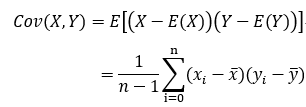
由上面的公式,我们可以得到以下结论:
(1) 方差的计算公式是针对一维特征,即针对同一特征不同样本的取值来进行计算得到;而协方差则必须要求至少满足二维特征;方差是协方差的特殊情况。
(2) 方差和协方差的除数是n-1,这是为了得到方差和协方差的无偏估计。
协方差为正时,说明X和Y是正相关关系;协方差为负时,说明X和Y是负相关关系;协方差为0时,说明X和Y是相互独立。Cov(X,X)就是X的方差。当样本是n维数据时,它们的协方差实际上是协方差矩阵(对称方阵)。例如,对于3维数据(x,y,z),计算它的协方差就是:

散度矩阵定义可以参照地址:https://blog.csdn.net/guyuealian/article/details/68922981
对于数据X的散度矩阵为 XXT 。其实协方差矩阵和散度矩阵关系密切,散度矩阵就是协方差矩阵乘以(总数据量n-1)。因此它们的特征值和特征向量是一样的。这里值得注意的是,散度矩阵是SVD奇异值分解的一步,因此PCA和SVD是有很大联系。
3.3 特征值分解矩阵原理:
https://blog.csdn.net/zhengwei223/article/details/78913898
其实线性代数只是没有提到在机器学习中的应用,大学时候的线代讲的已经很完完美了。
3.4 SVD分解矩阵原理
https://mp.weixin.qq.com/s/Dv51K8JETakIKe5dPBAPVg
SVD分解矩阵A的步骤:
(1) 求AAT 的特征值和特征向量,用单位化的特征向量构成 U。
(2) 求 AT A的特征值和特征向量,用单位化的特征向量构成 V。
(3) 将 AAT 或者 AT A 的特征值求平方根,然后构成 Σ。
3.5 PCA算法两种实现方法
(1) 基于特征值分解协方差矩阵实现PCA算法
输入:数据集X={ x1, x2, x3, …, xn },需要降到k维。
1) 去平均值(即去中心化),即每一位特征减去各自的平均值。
2) 计算协方差矩阵(1/n)XXT ,注:这里除或不除样本数量n或n-1,其实对求出的特征向量没有影响。
3) 用特征值分解方法求协方差矩阵(1/n)XXT,的特征值与特征向量。
4) 对特征值从大到小排序,选择其中最大的k个。然后将其对应的k个特征向量分别作为行向量组成特征向量矩阵P。
5) 将数据转换到k个特征向量构建的新空间中,即Y=PX。
总结:
1)关于这一部分为什么用 , ,这里面含有很复杂的线性代数理论推导
PCA的数学原理: http://blog.codinglabs.org/articles/pca-tutorial.html
2)关于为什么用特征值分解矩阵,是因为 是方阵,能很轻松的求出特征值与特征向量。当然,用奇异值分解也可以,是求特征值与特征向量的另一种方法。
注意:如果我们通过特征值分解协方差矩阵,那么我们只能得到一个方向的PCA降维。这个方向就是对数据矩阵X从行(或列)方向上压缩降维。
(2) 基于SVD分解协方差矩阵实现PCA算法
输入:数据集X={ x1, x2, x3, …, xn },需要降到k维。
1) 去平均值,即每一位特征减去各自的平均值。
2) 计算协方差矩阵。
3) 通过SVD计算协方差矩阵的特征值与特征向量。
4) 对特征值从大到小排序,选择其中最大的k个。然后将其对应的k个特征向量分别作为列向量组成特征向量矩阵。
5) 将数据转换到k个特征向量构建的新空间中。
在PCA降维中,我们需要找到样本协方差矩阵XXT的最大k个特征向量,然后用这最大的k个特征向量组成的矩阵来做低维投影降维。可以看出,在这个过程中需要先求出协方差矩阵 XXT,当样本数多、样本特征数也多的时候,这个计算还是很大的。当我们用到SVD分解协方差矩阵的时候,SVD有两个好处:
1) 有一些SVD的实现算法可以先不求出协方差矩阵XXT 也能求出我们的右奇异矩阵V。也就是说,我们的PCA算法可以不用做特征分解而是通过SVD来完成,这个方法在样本量很大的时候很有效。实际上,scikit-learn的PCA算法的背后真正的实现就是用的SVD,而不是特征值分解。
2)注意到PCA仅仅使用了我们SVD的左奇异矩阵,没有使用到右奇异值矩阵,那么右奇异值矩阵有什么用呢?
假设我们的样本是m*n的矩阵X,如果我们通过SVD找到了矩阵 XXT 最大的k个特征向量组成的k*n的矩阵VT ,则我们可以做如下处理:

可以得到一个m*k的矩阵X',这个矩阵和我们原来m*n的矩阵X相比,列数从n减到了k,可见对列数进行了压缩。也就是说,左奇异矩阵可以用于对行数的压缩;右奇异矩阵可以用于对列(即特征维度)的压缩。这就是我们用SVD分解协方差矩阵实现PCA可以得到两个方向的PCA降维(即行和列两个方向)。
4. PCA的理论推导
PCA可以通过两个思路推导,1)最大方差理论;2)最小化降维造成的损失
他们最终推导的结果相同
https://zhuanlan.zhihu.com/p/37777074
降维后低维空间的位数d’通常是由用户事先指定,或通过在d’ 值不同的低维空间中对k近邻分类器(或其它开销较小的学习器)进行交叉验证来选取较好的d’ 值。对PCA,还可从重构的角度设置一个阈值,例如t=95%,然后选取使下式成立的最小值d’:
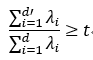
PCA仅需保留投影矩阵与样本的均值向量即可通过简单的向量减法和矩阵向量乘法将新样本投影至低维空间中。显然,低维空间与原始高维空间必有不同,因为对应于最小的d-d’个特征值的特征向量被舍弃了,这是降维导致的结果。但舍弃这部分信息往往是必要的:一方面,舍弃这部分信息之后能使样本的采样密度增大,这正是降维的重要动机;另一方面,当数据收到噪声影响时,最小的特征值所对应的特征向量往往与噪声有关,将它们舍弃能在一定程度上起到去噪的效果。
机器学习之主成分分析PCA原理笔记的更多相关文章
- 主成分分析(PCA)原理与实现
主成分分析原理与实现 主成分分析是一种矩阵的压缩算法,在减少矩阵维数的同时尽可能的保留原矩阵的信息,简单来说就是将 \(n×m\)的矩阵转换成\(n×k\)的矩阵,仅保留矩阵中所存在的主要特性,从 ...
- 主成分分析(PCA)原理及推导
原文:http://blog.csdn.net/zhongkejingwang/article/details/42264479 什么是PCA? 在数据挖掘或者图像处理等领域经常会用到主成分分析,这样 ...
- 【机器学习】--主成分分析PCA降维从初识到应用
一.前述 主成分分析(Principal Component Analysis,PCA), 是一种统计方法.通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分. ...
- 【机器学习】主成分分析PCA(Principal components analysis)
1. 问题 真实的训练数据总是存在各种各样的问题: 1. 比如拿到一个汽车的样本,里面既有以“千米/每小时”度量的最大速度特征,也有“英里/小时”的最大速度特征,显然这两个特征有一个多余. 2. 拿到 ...
- 主成分分析(PCA)原理详解_转载
一.PCA简介 1. 相关背景 在许多领域的研究与应用中,往往需要对反映事物的多个变量进行大量的观测,收集大量数据以便进行分析寻找规律.多变量大样本无疑会为研究和应用提供了丰富的信息,但也在一定程度上 ...
- 机器学习入门-主成分分析(PCA)
主成分分析: 用途:降维中最常用的一种方法 目标:提取有用的信息(基于方差的大小) 存在的问题:降维后的数据将失去原本的数据意义 向量的内积:A*B = |A|*|B|*cos(a) 如果|B| = ...
- 机器学习 —— 基础整理(四)特征提取之线性方法:主成分分析PCA、独立成分分析ICA、线性判别分析LDA
本文简单整理了以下内容: (一)维数灾难 (二)特征提取--线性方法 1. 主成分分析PCA 2. 独立成分分析ICA 3. 线性判别分析LDA (一)维数灾难(Curse of dimensiona ...
- 机器学习13—PCA学习笔记
主成分分析PCA 机器学习实战之PCA test13.py #-*- coding:utf-8 import sys sys.path.append("pca.py") impo ...
- 机器学习降维方法概括, LASSO参数缩减、主成分分析PCA、小波分析、线性判别LDA、拉普拉斯映射、深度学习SparseAutoEncoder、矩阵奇异值分解SVD、LLE局部线性嵌入、Isomap等距映射
机器学习降维方法概括 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/u014772862/article/details/52335970 最近 ...
随机推荐
- #C++初学记录(判断子串#数学结合)
A Count Task Problem Description Count is one of WNJXYK's favorite tasks. Recently, he had a very lo ...
- gogs 实现webhook钩子(php接口形式)
1.概要流程 2.准备工作 gogs服务器 linux网站服务器(宝塔) 本地客户端 3.编写钩子访问的接口 在public下新建githook.php文件,代码如下: <?php $cmd = ...
- OpenJudge 计算概论1007:点评赛车
总时间限制: 1000ms 内存限制: 65536kB描述4名专家对4款赛车进行评论1)A说:2号赛车是最好的:2)B说:4号赛车是最好的:3)C说:3号赛车不是最好的:4)D说: B说错了.事实上只 ...
- layui日历控件设置选择日期不能超过当前日期
layui.use('laydate', function() { var laydate = layui.laydate; laydate.render({ elem : '#begin', max ...
- ISO/IEC 9899:2011 条款6.9.1——函数定义
6.9.1 函数定义 语法 1.function-definition: declaration-specifiers declarator declaration-listopt ...
- Python3基础 print 格式化输出 %f %d 保留浮点数的位数 整数的位数不够零来凑
Python : 3.7.3 OS : Ubuntu 18.04.2 LTS IDE : pycharm-community-2019.1.3 ...
- Java统计文件数量
Java统计文件数量 package com.vfsd; import java.io.File; import java.io.IOException; /********************* ...
- SIEBEL BIP报表平台端口被占用
管理-服务器配置S 找到对应的服务名称: CRMSS2 组件输入:XMLP Report Server 选择[高级]后,查找 Static Port Number 即可修改端口号. 端口号可查询测试环 ...
- win10更新之后vmware使用失败
1.现象 2.解决:把所有更新卸载
- 【插件】thinkphp5+百度编辑器自定义上传
1 官方下载sdk 2 在引入编辑器页面.写入js // 百度编辑器 UE.Editor.prototype._bkGetActionUrl = UE.Editor.prototype.getActi ...