互联网UV,PU,TopN统计
1. UV、PV、TopN概念
1.1 UV(unique visitor) 即独立访客数
指访问某个站点或点击某个网页的不同IP地址的人数。在同一天内,UV只记录第一次进入网站的具有独立IP的访问者,在同一天内再次访问该网站则不计数。UV提供了一定时间内不同观众数量的统计指标,而没有反应出网站的全面活动。
1.2 PV(page view)页面浏览量或点击量
页面浏览量或点击量,是衡量一个网站或网页用户访问量。具体的说,PV值就是所有访问者在24小时(0点到24点)内看了某个网站多少个页面或某个网页多少次。PV是指页面刷新的次数,每一次页面刷新,就算做一次PV流量。
1.3 TopN
顾名思义,就是获取前10或前N的数据。
2. 离线计算UV、PV、TopN
这里主要使用hive或者MapReduce计算。
2.1 统计每个时段网站的PV和UV
hive> select date,hour,count(url) pv, count(distinct guid) uv from track_log group by date, hour; date hour pv uv
2.2 hive中创建结果表
create table db_track_daily_hour_visit(
date string,
hour string,
pv string,
uv string
)
row format delimited fields terminated by "\t";
2.3 结果写入Hive表(这里最好使用shell脚本去做)
结果步骤2.1与2.2,把2.1产生的结果数据写入到2.2的结果表中
hive> insert overwrite table db_track_daily_hour_visit select date, hour, count(url), pv, count(distinct guid) uv from track_log group by date, hour;
2.4 创建crontab命令,每天定时调度2.3的shell脚本
2.5 mysql中创建一张表,永久存储分析结果
mysql> create table visit(
-> date int,
-> hour int,
-> pv bigint,
-> uv bigint
);
2.6 利用sqoop导入数据到Mysql
注:以下代码也可以放到crontab里面每天自动执行
$ bin/sqoop --options-file job1/visit.opt
mysql> select * from visit; +----------+------+-------+-------+
| date | hour | pv | uv |
+----------+------+-------+-------+
| | | | |
| | | | |
+----------+------+-------+-------+
3. 实时计算UV、PV、TopN
在实时流式计算中,最重要的是在任何情况下,消息不重复、不丢失,即Exactly-once。本文以Kafka->Spark Streaming->Redis为例,一方面说明一下如何做到Exactly-once,另一方面说明一下如何计算实时去重指标的。
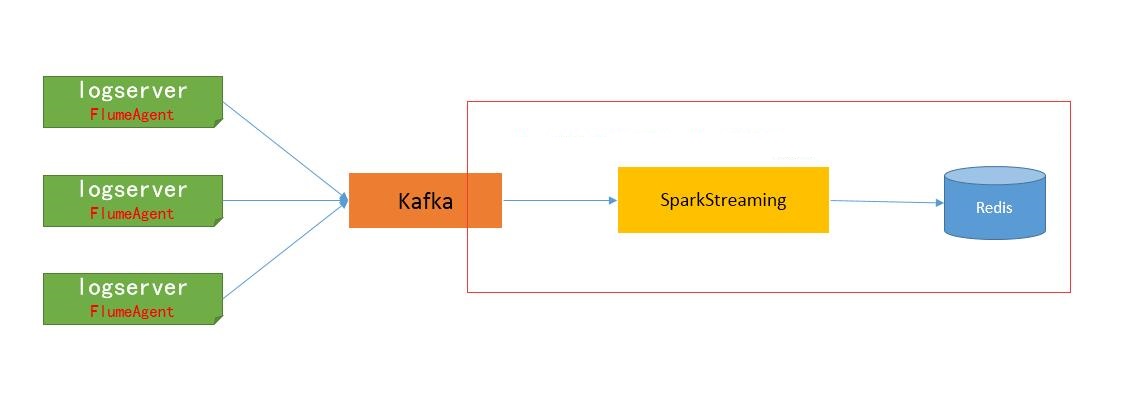
3.1 关于数据源
日志格式为:
2018-02-22T00:00:00+08:00|~|200|~|/test?pcid=DEIBAH&siteid=3
2018-02-22T00:00:00+08:00|~|200|~|/test?pcid=GLLIEG&siteid=3
2018-02-22T00:00:00+08:00|~|200|~|/test?pcid=HIJMEC&siteid=8
2018-02-22T00:00:00+08:00|~|200|~|/test?pcid=HMGBDE&siteid=3
2018-02-22T00:00:00+08:00|~|200|~|/test?pcid=HIJFLA&siteid=4
2018-02-22T00:00:01+08:00|~|200|~|/test?pcid=JCEBBC&siteid=9
2018-02-22T00:00:01+08:00|~|200|~|/test?pcid=KJLAKG&siteid=8
2018-02-22T00:00:01+08:00|~|200|~|/test?pcid=FHEIKI&siteid=3
2018-02-22T00:00:01+08:00|~|200|~|/test?pcid=IGIDLB&siteid=3
2018-02-22T00:00:01+08:00|~|200|~|/test?pcid=IIIJCD&siteid=5
日志是由测试程序模拟产生的,字段之间由|~|分隔。pcid为计算机pc的id,siteid为网站id
3.2 实时计算需求
分天、分小时PV、UV;
分天、分小时、分网站(siteid)PV、UV;
3.3 Spark Streaming消费Kafka数据
在Spark Streaming中消费Kafka数据,保证Exactly-once的核心有三点:
①使用Direct方式连接Kafka;
②自己保存和维护Offset;
③更新Offset和计算在同一事务中完成;
后面的Spark Streaming程序,主要有以下步骤:
①启动后,先从Redis中获取上次保存的Offset,Redis中的key为“topic_partition”,即每个分区维护一个Offset;
②使用获取到的Offset,创建DirectStream;
③在处理每批次的消息时,利用Redis的事务机制,确保在Redis中指标的计算和Offset的更新维护,在同一事务中完成。只有这两者同步,才能真正保证消息的Exactly-once。
./spark-submit \
--class com.lxw1234.spark.TestSparkStreaming \
--master local[] \
--conf spark.streaming.kafka.maxRatePerPartition= \
--jars /data1/home/dmp/lxw/realtime/commons-pool2-2.3.jar,\
/data1/home/dmp/lxw/realtime/jedis-2.9..jar,\
/data1/home/dmp/lxw/realtime/kafka-clients-0.11.0.1.jar,\
/data1/home/dmp/lxw/realtime/spark-streaming-kafka--10_2.-2.2..jar \
/data1/home/dmp/lxw/realtime/testsparkstreaming.jar \
--executor-memory 4G \
--num-executors
在启动Spark Streaming程序时候,有个参数最好指定:
spark.streaming.kafka.maxRatePartition=20000(每秒钟从topic的每个partition最多消费的消息条数)
如果程序第一次运行,或者因为某种原因暂停了很久重新启动时候,会积累很多消息,如果这些消息同时被消费,很有可能会因为内存不够而挂掉,因此,需要根据实际的数据量大小,以及批次的间隔时间来设置该参数,以限定批次的消息量。
如果该参数设置20000,而批次间隔时间未10秒,那么每个批次最多从Kafka中消费20万消息。
3.4 Redis中的数据模型
① 分小时、分网站PV
普通K-V结构,计算时候使用incr命令递增,
Key为 “site_pv_网站ID_小时”,
如:site_pv_9_2018-02-21-00、site_pv_10_2018-02-12-01
② 分小时PV、分天PV(分天的暂无)
普通K-V结构,计算时候使用incr命令递增,
Key为 “pv_小时”,如:pv_2018-02-21-14、pv_2018-02-22-03
该数据模型用于计算按小时及按天总PV。
③ 分小时、分网站UV
Set结构,计算时候使用sadd命令添加,
Key为 “site_uv_网站ID_小时”,如:site_uv_8_2018-02-21-12、site_uv_6_2019-09-12-09
该数据模型用户计算按小时和网站的总UV(获取时候使用SCARD命令获取Set元素个数)
④ 分小时UV、分天UV(分天的暂无)
Set结构,计算时候使用sadd命令添加,
Key为 “uv_小时”,如:uv_2018-02-21-08、uv_2018-02-20-09
该数据模型用户计算按小时及按天的总UV(获取时候使用SCARD命令获取Set元素个数)
注意:这些Key对应的时间,均有实际消息中的第一个字段(时间)而定。
3.5 代码程序
maven依赖包
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency> <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.</artifactId>
<version>${spark.version}</version>
</dependency> <!-- streaming kafka redis start-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.1.</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.</artifactId>
<version>2.1.</version>
</dependency> <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka--10_2.</artifactId>
<version>2.4.</version>
</dependency>
<!-- streaming kafka redis end --> <dependency>
<groupId>ch.ethz.ganymed</groupId>
<artifactId>ganymed-ssh2</artifactId>
<version></version>
</dependency> <dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-xml</artifactId>
<version>2.11.-M4</version>
</dependency>
</dependencies>
kafka偏移量管理工具类KafkaOffsetUtils:
package com.swordfall.common import java.time.Duration
import org.apache.kafka.clients.consumer.{Consumer, ConsumerConfig, KafkaConsumer, NoOffsetForPartitionException}
import org.apache.kafka.common.TopicPartition
import scala.collection.JavaConversions._
import scala.collection.mutable object KafkaOffsetUtils { /**
* 获取最小offset
*
* @param consumer 消费者
* @param partitions topic分区
* @return
*/
def getEarliestOffsets(consumer: Consumer[_, _], partitions: Set[TopicPartition]): Map[TopicPartition, Long] = {
consumer.seekToBeginning(partitions)
partitions.map(tp => tp -> consumer.position(tp)).toMap
} /**
* 获取最小offset
* Returns the earliest (lowest) available offsets, taking new partitions into account.
*
* @param kafkaParams kafka客户端配置
* @param topics 获取offset的topic
*/
def getEarliestOffsets(kafkaParams: Map[String, Object], topics: Iterable[String]): Map[TopicPartition, Long] = {
val newKafkaParams = mutable.Map[String, Object]()
newKafkaParams ++= kafkaParams
newKafkaParams.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest")
val consumer: KafkaConsumer[String, Array[Byte]] = new KafkaConsumer[String, Array[Byte]](newKafkaParams)
consumer.subscribe(topics)
val parts = consumer.assignment()
consumer.seekToBeginning(parts)
consumer.pause(parts)
val offsets = parts.map(tp => tp -> consumer.position(tp)).toMap
consumer.unsubscribe()
consumer.close()
offsets
} /**
* 获取最大offset
*
* @param consumer 消费者
* @param partitions topic分区
* @return
*/
def getLatestOffsets(consumer: Consumer[_, _], partitions: Set[TopicPartition]): Map[TopicPartition, Long] = {
consumer.seekToEnd(partitions)
partitions.map(tp => tp -> consumer.position(tp)).toMap
} /**
* 获取最大offset
* Returns the latest (highest) available offsets, taking new partitions into account.
*
* @param kafkaParams kafka客户端配置
* @param topics 需要获取offset的topic
**/
def getLatestOffsets(kafkaParams: Map[String, Object], topics: Iterable[String]): Map[TopicPartition, Long] = {
val newKafkaParams = mutable.Map[String, Object]()
newKafkaParams ++= kafkaParams
newKafkaParams.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest")
val consumer: KafkaConsumer[String, Array[Byte]] = new KafkaConsumer[String, Array[Byte]](newKafkaParams)
consumer.subscribe(topics)
val parts = consumer.assignment()
consumer.seekToEnd(parts)
consumer.pause(parts)
val offsets = parts.map(tp => tp -> consumer.position(tp)).toMap
consumer.unsubscribe()
consumer.close()
offsets
} /**
* 获取消费者当前offset
*
* @param consumer 消费者
* @param partitions topic分区
* @return
*/
def getCurrentOffsets(consumer: Consumer[_, _], partitions: Set[TopicPartition]): Map[TopicPartition, Long] = {
partitions.map(tp => tp -> consumer.position(tp)).toMap
} /**
* 获取offsets
*
* @param kafkaParams kafka参数
* @param topics topic
* @return
*/
def getCurrentOffset(kafkaParams: Map[String, Object], topics: Iterable[String]): Map[TopicPartition, Long] = {
val offsetResetConfig = kafkaParams.getOrElse(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest").toString.toLowerCase()
val newKafkaParams = mutable.Map[String, Object]()
newKafkaParams ++= kafkaParams
newKafkaParams.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "none")
val consumer: KafkaConsumer[String, Array[Byte]] = new KafkaConsumer[String, Array[Byte]](newKafkaParams)
consumer.subscribe(topics)
val notOffsetTopicPartition = mutable.Set[TopicPartition]() try {
consumer.poll(Duration.ofMillis(0))
} catch {
case ex: NoOffsetForPartitionException =>
println(s"consumer topic partition offset not found:${ex.partition()}")
notOffsetTopicPartition.add(ex.partition())
} val parts = consumer.assignment().toSet
consumer.pause(parts)
val topicPartition = parts.diff(notOffsetTopicPartition)
//获取当前offset
val currentOffset = mutable.Map[TopicPartition, Long]()
topicPartition.foreach(x => {
try {
currentOffset.put(x, consumer.position(x))
} catch {
case ex: NoOffsetForPartitionException =>
println(s"consumer topic partition offset not found:${ex.partition()}")
notOffsetTopicPartition.add(ex.partition())
}
})
//获取earliiestOffset
val earliestOffset = getEarliestOffsets(consumer, parts)
earliestOffset.foreach(x => {
val value = currentOffset.get(x._1)
if (value.isEmpty){
currentOffset(x._1) = x._2
}else if (value.get < x._2){
println(s"kafka data is lost from partition:${x._1} offset ${value.get} to ${x._2}")
currentOffset(x._1) = x._2
}
})
// 获取lastOffset
val lateOffset = if (offsetResetConfig.equalsIgnoreCase("earliest")){
getLatestOffsets(consumer, topicPartition)
}else {
getLatestOffsets(consumer, parts)
} lateOffset.foreach(x => {
val value = currentOffset.get(x._1)
if (value.isEmpty || value.get > x._2){
currentOffset(x._1) = x._2
}
})
consumer.unsubscribe()
consumer.close()
currentOffset.toMap
}
}
Redis资源管理工具类InternalRedisClient:
package com.swordfall.streamingkafka import org.apache.commons.pool2.impl.GenericObjectPoolConfig
import redis.clients.jedis.JedisPool /**
* @Author: Yang JianQiu
* @Date: 2019/9/10 0:19
*/
object InternalRedisClient extends Serializable { @transient private var pool: JedisPool = null def makePool(redisHost: String, redisPort: Int, redisTimeout: Int, maxTotal: Int, maxIdle: Int, minIdle: Int): Unit ={
makePool(redisHost, redisPort, redisTimeout, maxTotal, maxIdle, minIdle, true, false, 10000)
} def makePool(redisHost: String, redisPort: Int, redisTimeout: Int, maxTotal: Int, maxIdle: Int, minIdle: Int, testOnBorrow: Boolean, testOnReturn: Boolean, maxWaitMills: Long): Unit ={
if (pool == null){
val poolConfig = new GenericObjectPoolConfig()
poolConfig.setMaxTotal(maxTotal)
poolConfig.setMaxIdle(maxIdle)
poolConfig.setMinIdle(minIdle)
poolConfig.setTestOnBorrow(testOnBorrow)
poolConfig.setTestOnReturn(testOnReturn)
poolConfig.setMaxWaitMillis(maxWaitMills)
pool = new JedisPool(poolConfig, redisHost, redisPort, redisTimeout) val hook = new Thread{
override def run = pool.destroy()
}
sys.addShutdownHook(hook.run)
}
} def getPool: JedisPool = {
if (pool != null) pool else null
} }
核心Spark Streaming处理kafka数据,并统计UV、PV到redis里面,同时在redis里面维护kafka偏移量:
package com.swordfall.streamingkafka import com.swordfall.common.KafkaOffsetUtils
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, HasOffsetRanges, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import redis.clients.jedis.Pipeline /**
* 获取topic最小的offset
*/
object SparkStreamingKafka { def main(args: Array[String]): Unit = {
val brokers = "192.168.187.201:9092"
val topic = "nginx"
val partition: Int = 0 // 测试topic只有一个分区
val start_offset: Long = 0L // Kafka参数
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> brokers,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "test",
"enable.auto.commit" -> (false: java.lang.Boolean),
"auto.offset.reset" -> "latest"
) // Redis configurations
val maxTotal = 10
val maxIdle = 10
val minIdle = 1
val redisHost = "192.168.187.201"
val redisPort = 6379
val redisTimeout = 30000
// 默认db,用户存放Offset和pv数据
val dbDefaultIndex = 8
InternalRedisClient.makePool(redisHost, redisPort, redisTimeout, maxTotal, maxIdle, minIdle) val conf = new SparkConf().setAppName("SparkStreamingKafka").setIfMissing("spark.master", "local[2]")
val ssc = new StreamingContext(conf, Seconds(10)) // 从Redis获取上一次存的Offset
val jedis = InternalRedisClient.getPool.getResource
jedis.select(dbDefaultIndex)
val topic_partition_key = topic + "_" + partition val lastSavedOffset = jedis.get(topic_partition_key)
var fromOffsets: Map[TopicPartition, Long] = null
if (null != lastSavedOffset){
var lastOffset = 0L
try{
lastOffset = lastSavedOffset.toLong
}catch{
case ex: Exception => println(ex.getMessage)
println("get lastSavedOffset error, lastSavedOffset from redis [" + lastSavedOffset + "]")
System.exit(1)
}
// 设置每个分区起始的Offset
fromOffsets = Map{ new TopicPartition(topic, partition) -> lastOffset } println("lastOffset from redis -> " + lastOffset)
}else{
//等于null,表示第一次, redis里面没有存储偏移量,但是可能会存在kafka存在一部分数据丢失或者过期,但偏移量没有记录在redis里面,
// 偏移量还是按0的话,会导致偏移量范围出错,故需要拿到earliest或者latest的偏移量
fromOffsets = KafkaOffsetUtils.getCurrentOffset(kafkaParams, List(topic))
}
InternalRedisClient.getPool.returnResource(jedis) // 使用Direct API 创建Stream
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Assign[String, String](fromOffsets.keys.toList, kafkaParams, fromOffsets)
) // 开始处理批次消息
stream.foreachRDD{
rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
val result = processLogs(rdd)
println("================= Total " + result.length + " events in this batch ..") val jedis = InternalRedisClient.getPool.getResource
// redis是单线程的,下一次请求必须等待上一次请求执行完成后才能继续执行,然而使用Pipeline模式,客户端可以一次性的发送多个命令,无需等待服务端返回。这样就大大的减少了网络往返时间,提高了系统性能。
val pipeline: Pipeline = jedis.pipelined()
pipeline.select(dbDefaultIndex)
pipeline.multi() // 开启事务 // 逐条处理消息
result.foreach{
record => // 增加网站小时pv
val site_pv_by_hour_key = "site_pv_" + record.site_id + "_" + record.hour
pipeline.incr(site_pv_by_hour_key) // 增加小时总pv
val pv_by_hour_key = "pv_" + record.hour
pipeline.incr(pv_by_hour_key) // 使用set保存当天每个小时网站的uv
val site_uv_by_hour_key = "site_uv_" + record.site_id + "_" + record.hour
pipeline.sadd(site_uv_by_hour_key, record.user_id) // 使用set保存当天每个小时的uv
val uv_by_hour_key = "uv_" + record.hour
pipeline.sadd(uv_by_hour_key, record.user_id)
} // 更新Offset
offsetRanges.foreach{
offsetRange =>
println("partition: " + offsetRange.partition + " fromOffset: " + offsetRange.fromOffset + " untilOffset: " + offsetRange.untilOffset)
val topic_partition_key = offsetRange.topic + "_" + offsetRange.partition
pipeline.set(topic_partition_key, offsetRange.untilOffset + "")
} pipeline.exec() // 提交事务
pipeline.sync() // 关闭pipeline InternalRedisClient.getPool.returnResource(jedis)
} ssc.start()
ssc.awaitTermination()
} case class MyRecord(hour: String, user_id: String, site_id: String) def processLogs(messages: RDD[ConsumerRecord[String, String]]): Array[MyRecord] = {
messages.map(_.value()).flatMap(parseLog).collect()
} def parseLog(line: String): Option[MyRecord] = {
val ary: Array[String] = line.split("\\|~\\|", -1)
try{
val hour = ary(0).substring(0, 13).replace("T", "-")
val uri = ary(2).split("[=|&]", -1)
val user_id = uri(1)
val site_id = uri(3)
return scala.Some(MyRecord(hour, user_id, site_id))
}catch{
case ex: Exception => println(ex.getMessage)
}
return None
} }
4. 总结
【github地址】
https://github.com/SwordfallYeung/SparkStreamingDemo
【参考资料】
http://www.cj318.cn/?p=4
https://blog.csdn.net/liam08/article/details/80155006
http://www.ikeguang.com/2018/08/03/statistic-hive-daily-week-month/
https://dongkelun.com/2018/06/25/KafkaUV/
https://blog.csdn.net/wwwzydcom/article/details/89506227
http://lxw1234.com/archives/2018/02/901.htm
https://blog.csdn.net/qq_35946969/article/details/83654369
互联网UV,PU,TopN统计的更多相关文章
- 怎么区分PV、IV、UV以及网站统计名词解释(pv、曝光、点击)
PV(Page View)访问量,即页面访问量,每打开一次页面PV计数+1,刷新页面也是. IV(Internet Protocol)访问量指独立IP访问数,计算是以一个独立的IP在一个计算时段内访问 ...
- 使用redis做pv、uv、click统计
redis实时统计 设计思路: 1. 前端smarty插件(smarty_function_murl),将网站所有的连接生成一个urlid,后端根据获取的参数将需要的数据存入redis. 2.后端插件 ...
- 43、内置函数及每日uv、销售额统计案例
一.spark1.5内置函数 在Spark 1.5.x版本,增加了一系列内置函数到DataFrame API中,并且实现了code-generation的优化.与普通的函数不同,DataFrame的函 ...
- 统计uv(转)
UV是unique visitor的简写,是指通过互联网访问.浏览这个网页的自然人.在同一天内,uv只记录第一次进入网站的具有独立IP的访问者,在同一天内再次访问该网站则不计数.独立IP访问者提供了一 ...
- 网站流量统计之PV和UV
转自:http://blog.csdn.NET/webdesman/article/details/4062069 如果您是一个站长,或是一个SEO,您一定对于网站统计系统不会陌生,对于SEO新手来说 ...
- pyspark进行词频统计并返回topN
Part I:词频统计并返回topN 统计的文本数据: what do you do how do you do how do you do how are you from operator imp ...
- Linux运维之每日小技巧-检测网站状态以及PV、UV等介绍
[root@ELK-chaofeng07 httpd]# curl -o /dev/null -w %{http_code}\\n -s www.baidu.com 状态码为200表示成功. PV.U ...
- 基于flink快速开发实时TopN程序
TopN 是统计报表和大屏非常常见的功能,主要用来实时计算排行榜.流式的TopN可以使业务方在内存中按照某个统计指标(如出现次数)计算排名并快速出发出更新后的排行榜. 我们以统计词频为例展示一下如何快 ...
- 一种统计ListView滚动距离的方法
注:本文同步发布于微信公众号:stringwu的互联网杂谈 一种统计ListView滚动距离的方法 ListView做为Android中最常使用的列表控件,主要用来显示同一类的数据,如应用列表,商品列 ...
随机推荐
- [转帖]使用 Vagrant 打造跨平台开发环境
使用 Vagrant 打造跨平台开发环境 https://segmentfault.com/a/1190000000264347 Vagrant 是一款用来构建虚拟开发环境的工具,非常适合 php/p ...
- SACD-ISO音频镜像播放方式
SACD-ISO 音频文件不需要解压也不需要挂载光盘,可以直拖入播放器播放. 播放器下载 foobar2000https://www.foobar2000.org/download 解码插件下载 Su ...
- Redis初识01 (简介、安装、使用)
一.Reids介绍 redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zset(s ...
- 给定一个二叉搜索树的根节点 root 和一个值 key,删除二叉搜索树中的 key 对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用
一般来说,删除节点可分为两个步骤: 首先找到需要删除的节点: 如果找到了,删除它. 说明: 要求算法时间复杂度为 O(h),h 为树的高度. 示例: root = [5,3,6,2,4,null,7] ...
- Ubuntu中shell脚本无法使用source命令的原因与解决方法
本文简要描述了在ubuntu系统下无法使用source命令的原因,及对应的两种解决方法,并在附录中引用一篇文章来详细解释source命令的用法 问题: 由于在交叉编译时,需要在当前shell内执行so ...
- appium 方法整理
1.contexts contexts(self): Returns the contexts within the current session. 返回当前会话中的上下文,使用后可 ...
- liunx下Oracle安装
1. 引言 将近一个月没有更新博客了,最近忙着数据库数据迁移工作:自己在服务器上搭建了oracle数据库,一步步走下来遇见很多BUG:现在自己记录下,方便以后有用上的地方: 2. 准备工作 oracl ...
- MySQL单表数据量过千万,采坑优化记录,完美解决方案
问题概述 使用阿里云rds for MySQL数据库(就是MySQL5.6版本),有个用户上网记录表6个月的数据量近2000万,保留最近一年的数据量达到4000万,查询速度极慢,日常卡死.严重影响业务 ...
- 【开发工具】-解决Myeclipse 的 Server窗口报空指针错误
Eclipse 或者 MyEclipse 查看 server面板的时候,报错,如图所示,错误 代码:java.lang.NullPointerException .另外,由于此错误,导致 项目不能够 ...
- Maven项目命名规范
Guide to naming conventions on groupId, artifactId and versiongroupId will identify your project uni ...