选择类排序 (简单选择排序,堆排序)— c语言实现
选择类排序包括:
(1) 简单选择排序
(2)树形选择排序
(3)堆排序
简单选择排序:
【算法思想】:在第 i 趟简单选择排序中,从第 i 个记录开始,通过 n - i 次关键字比较,从 n - i + 1 个记录中选出关键字最小的记录,并和第 i 个记录进行交换
时间复杂度:O(n^2)
//此函数中a[0]不用,即对 a[1] ~ a[length-1] 排序;
//如果对a[0]~a[length-1]排序,将 for 循环中的 i = 1 改为 i = 0 即可,注意输出
void select(int a[],int length){//length为数组的长度
int i,j;
int min;//记录最小值的位置 for(i = ;i < length - ;i++){
min = i;
//选择最小的值
for(j = i + ;j < length;j++){
if(a[j] < a[min]) //更新最小值的坐标
min = j;
}
if(min != i){
int temp;
temp = a[min];
a[min] = a[i];
a[i] = temp;
}
}
}
堆排序:
堆排序是威洛母斯在1964年提出的对树形选择排序的改进算法,其只需要一个记录大小的辅助空间,采用向量数组方式存储,采用完全二叉树的顺序结构的特征进行分析,而非采用树的存储结构。
从小到大排序采用大根(顶)堆:r[i].key >= r[2i].key && r[i].key >= r[2i+1].key (结点值大于等于其左子与右子)
从大到小排序采用小根(顶)堆:r[i].key <= r[2i].key && r[i].key<= r[2i+1].key (结点值小于等于其左子与右子)
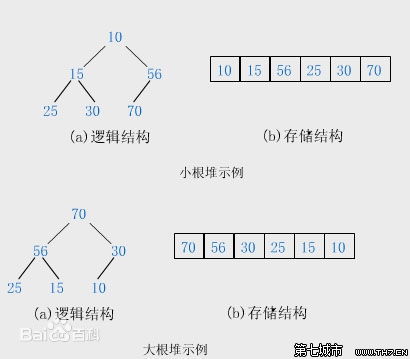
【算法思想】把待排序的记录的关键字存放在数组 r[1...n] 中,将 r 看成一棵完全二叉树的顺序表示,每个结点表示一个记录,第一个记录 r[1] 作为二叉树的根,以下各记录 r[2] ~ r[n] 依次逐层从左到右顺序排列,任意结点 r[i] 的左孩子是 r[2i] ,右孩子是 r[2i+1],双亲是 r[i/2]。对这棵二叉树进行调整建堆。
时间复杂度:O(nlog2n)
说明:在c语言中,i/2 的含义是整除,不同于数学中的定义,即 3/2 = 1,有一个向下取整的意思
堆排序可分为2步(从小到大排序):
<1> 建初堆:建立一个大根堆
<2>重建堆:进行 n - 1 趟的交换(r[1] 与 堆尾进行交换)和建堆的过程
/*堆排序*/
/*建初堆:大根堆*/
void AdjustDown(int a[],int k,int len);
void BuildMaxHeap(int a[],int len){
int i;
for(i = len/;i > ;i--){
AdjustDown(a,i,len);
}
}
//调整堆
void AdjustDown(int a[],int k,int len){
a[] = a[k];//将第一个记录移出
int i;
for(i = *k;i <= len;i = *i){
if(i < len && a[i] < a[i+])//不能忘记i < len,否则会超出范围
i++;//取左右子中的最大值
if(a[] >= a[i])
break;
else{
a[k] = a[i]; //将a[i]调整到其双亲结点上
k = i; //修改k值,以便继续向下筛选
}
}
a[k] = a[];
} void HeapSort(int a[],int len){
BuildMaxHeap(a,len);
int i;
int temp;
for(i = len;i > ;i--){
//第一个和堆尾进行交换
temp = a[];
a[] = a[i];
a[i] = temp;
//调整堆
AdjustDown(a,,i-);
}
}
图可参照:https://blog.csdn.net/u013384984/article/details/79496052
测试:
int main(){
int a[] = {-,,,,,,,,,,};
int b[] = {-,,,,,,,,,,};
int i,j;
select(a,); //没有用a[0],对后面的元素进行排序
HeapSort(b,);//数组的最后一个下标,a[0]为辅助单元
for ( i = ;i < ;i++){
printf("%d \t",a[i]);
}
printf("\n");
for ( i = ;i < ;i++){
printf("%d \t",b[i]);
}
printf("\n");
}
选择类排序 (简单选择排序,堆排序)— c语言实现的更多相关文章
- 选择排序—简单选择排序(Simple Selection Sort)
基本思想: 在要排序的一组数中,选出最小(或者最大)的一个数与第1个位置的数交换:然后在剩下的数当中再找最小(或者最大)的与第2个位置的数交换,依次类推,直到第n-1个元素(倒数第二个数)和第n个元素 ...
- 选择排序—简单选择排序(Simple Selection Sort)原理以及Java实现
基本思想: 在要排序的一组数中,选出最小(或者最大)的一个数与第1个位置的数交换:然后在剩下的数当中再找最小(或者最大)的与第2个位置的数交换,依次类推,直到第n-1个元素(倒数第二个数)和第n个元素 ...
- 9, java数据结构和算法: 直接插入排序, 希尔排序, 简单选择排序, 堆排序, 冒泡排序,快速排序, 归并排序, 基数排序的分析和代码实现
内部排序: 就是使用内存空间来排序 外部排序: 就是数据量很大,需要借助外部存储(文件)来排序. 直接上代码: package com.lvcai; public class Sort { publi ...
- 八大排序算法之三选择排序—简单选择排序(Simple Selection Sort)
基本思想: 在要排序的一组数中,选出最小(或者最大)的一个数与第1个位置的数交换:然后在剩下的数当中再找最小(或者最大)的与第2个位置的数交换,依次类推,直到第n-1个元素(倒数第二个数)和第n个元素 ...
- 内部排序->选择排序->简单选择排序
文字描述 简单排序的基本思想是:每一趟在n-i+1(i=1,2,…,n)个记录中选取关键字最小的记录作为有序列表中的第i个记录. 示意图 略 算法分析 简单排序算法中,所需进行记录移动的操作次数较少, ...
- Python实现八大排序(基数排序、归并排序、堆排序、简单选择排序、直接插入排序、希尔排序、快速排序、冒泡排序)
目录 八大排序 基数排序 归并排序 堆排序 简单选择排序 直接插入排序 希尔排序 快速排序 冒泡排序 时间测试 八大排序 大概了解了一下八大排序,发现排序方法的难易程度相差很多,相应的,他们计算同一列 ...
- 常见排序算法总结:插入排序,希尔排序,冒泡排序,快速排序,简单选择排序以及java实现
今天来总结一下常用的内部排序算法.内部排序算法们需要掌握的知识点大概有:算法的原理,算法的编码实现,算法的时空复杂度的计算和记忆,何时出现最差时间复杂度,以及是否稳定,何时不稳定. 首先来总结下常用内 ...
- 程序员必知的8大排序(二)-------简单选择排序,堆排序(java实现)
程序员必知的8大排序(一)-------直接插入排序,希尔排序(java实现) 程序员必知的8大排序(二)-------简单选择排序,堆排序(java实现) 程序员必知的8大排序(三)-------冒 ...
- 简单选择排序 Selection Sort 和树形选择排序 Tree Selection Sort
选择排序 Selection Sort 选择排序的基本思想是:每一趟在剩余未排序的若干记录中选取关键字最小的(也可以是最大的,本文中均考虑排升序)记录作为有序序列中下一个记录. 如第i趟选择排序就是在 ...
随机推荐
- 【学习笔记】fwt&&fmt&&子集卷积
前言:yyb神仙的博客 FWT 基本思路:将多项式变成点值表达,点值相乘之后再逆变换回来得到特定形式的卷积: 多项式的次数界都为\(2^n\)的形式,\(A_0\)定义为前一半多项式(下标二进制第一位 ...
- R = [obj for obj in recs[imagename] if obj['name'] == classname] KeyError: '007765'
在用RFBNet做测试的时候,好几次总是遇到 R = [obj for obj in recs[imagename] if obj['name'] == classname] KeyError: ' ...
- An internal error occurred during: "Synchronizing"
An internal error occurred during: "Synchronizing" “同步”期间发生内部错误. 处理方法 :单个文件进行更新,将无法更新的文件进行 ...
- noscript 标签介绍
noscript 标签介绍 一.总结 一句话总结: noscript 标签在不支持JavaScript 的浏览器中显示替代的内容. 1.noscript标签使用实例? html标签直接放在noscri ...
- Cesium原理篇:6 Render模块(6: Instance实例化)【转】
https://www.cnblogs.com/fuckgiser/p/6027520.html 最近研究Cesium的实例化,尽管该技术需要在WebGL2.0,也就是OpenGL ES3.0才支持. ...
- Shared variable in python's multiprocessing
Shared variable in python's multiprocessing https://www.programcreek.com/python/example/58176/multip ...
- Android ConstraintLayout 小记
* 可以圆形定位view之间的位置,通过View的中心,来定位不同半径和弧度的距离. layout_constraintCircle : references another widget id la ...
- SpringMVC 事件监听 ApplicationListener
1. 实现 ApplicationListener<T> 接口(T为监听类型,稍后会列出具体可监听事件) 2. 将该自定义监听类,注册为Spring容器组件.(即将该类注入Spring容器 ...
- python-- python threadpool 的前世今生
引出 首先需要了解的是threadpool 的用途,他更适合于用到一些大量的短任务合集,而非一些时间长的任务,换句话说,适合大量的CPU密集型短任务,那些消耗时间较长的IO密集型长任务适合用协程去解决 ...
- centos6.10环境下启动多个redis实例
# 启动redis端口6379的配置 [root@newcms:/usr/local/nginx/conf]# /etc/redis.conf daemonize yes pidfile /usr/l ...