Kubernetes集群中Jmeter对公司演示的压力测试
6分钟阅读
背景
压力测试是评估Web应用程序性能的有效方法。此外,越来越多的Web应用程序被分解为几个微服务,每个微服务的性能可能会有所不同,因为有些是计算密集型的,而有些是IO密集型的。
基于微服务架构的Web应用程序压力测试起着更重要的作用。本博客将使用Kubernetes集群中的JMeter 3.2(一种功能强大的压力测试工具)评估我们公司演示的性能。
从上一篇文章中,我们发现Manager服务需要大部分资源。因此,在此计划中,我们将深入研究Manager服务的性能测试。
测试计划
我们的JMeter测试计划是:
在压力测试之前处理身份验证,因为身份验证可能会导致严重延迟。
继续在公司演示中访问服务,通过QueryWorker,QueryBeekeeperDrone,QueryBeekeeperQueen HTTP请求生成器强调Manager服务。
你可以从github获得测试计划。
git clone https://github.com/ServiceComb/ServiceComb-Company-WorkShop
cd ServiceComb-Company-WorkShop/stress-tests
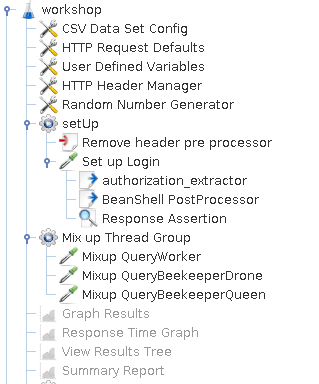 图1 JMeter测试计划
图1 JMeter测试计划
在我们的测试计划的第一个阶段,我们设置了一些在所有线程组之间共享的全局配置。该CSV数据集配置加载从本地CSV文件中我们的目标服务器的信息。在HTTP请求默认值设置在每个请求的默认主机和端口。所述用户定义的变量定义了全局共享的变量。在HTTP头管理器 将报头添加在其内部限定的每一个请求。
然后来到setUp线程组。它执行身份验证工作。在JMeter中进行身份验证的内置方式是HTTP Cookie管理器,因为cookie广泛用于Web应用程序。但是,我们的研讨会演示使用基于令牌的身份验证而不是基于cookie的身份验 我们需要绕道而行,以便在JMeter中完成身份验证。该预处理器删除头使用下面的脚本,以避免不必要的标头被注入到登录请求。
import org.apache.jmeter.protocol.http.control.Header;
sampler.getHeaderManager().removeHeaderNamed("Authorization");
然后我们在设置登录请求中检索登录凭据。所述authorization_extractor是一个正则表达式提取用于提取的值授权报头。由于变量无法从一个线程组传递到另一个线程组,因此需要转换为全局属性,而BeanShell PostProcessor中的脚本可以完成工作。
${__setProperty(Authorization,${Authorization},)}
我们测试计划的最后一部分是对我们的服务执行的压力测试。我们测试了三个端点,因为它们都从管理服务传递到另外两个微服务,即工人和养蜂人。在我们测试之前,我们通过在管理器中启用StressTest配置文件来禁用缓存功能,以便工作服务和养蜂人服务可以始终为传入的计算任务提供服务。此外,我们通过将请求参数设置为1来简化计算任务。
测试步骤
在没有资源限制的Kubernetes集群中启动公司演示。
使用Kubernetes集群中运行的Company演示的IP地址和端口替换hosts.csv文件的内容。hosts.csv中的内容是:
127.0.0.1,8083
运行测试。使用200个线程同时生成请求,并将持续时间设置为600秒。
jmeter -n -t workshop.jmx -j workshop.log -l workshop.jtl -Jthreads=200 -Jduration=600
检测结果
各种并发性能如下:
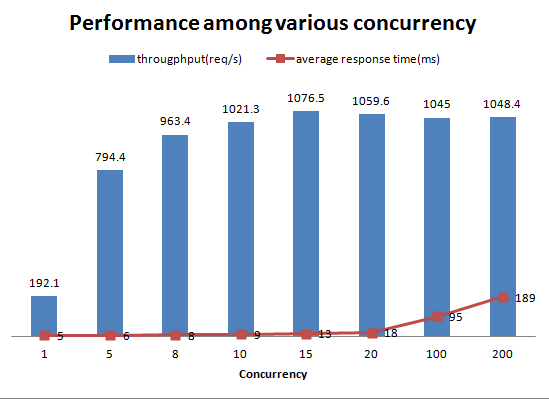 fig-2各种并发性能
fig-2各种并发性能
图2显示管理器服务的性能在达到瓶颈(并发为15)之前保持稳定,每秒加速约1000次请求,同时保持平均响应时间较短。随后,随着并发性的增加,平均响应时间急剧增加。在评估断路超时设置时,响应时间统计信息会很有用。
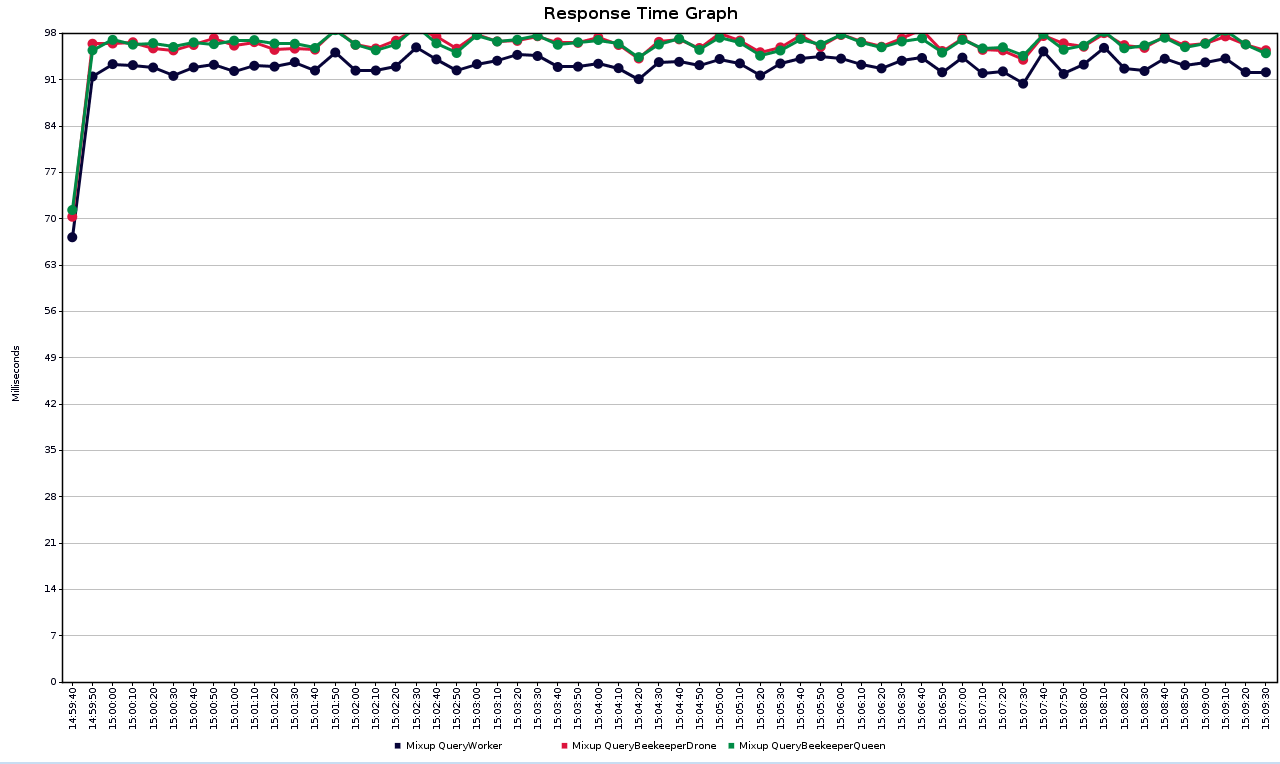 fig-3不同服务之间的平均响应时间
fig-3不同服务之间的平均响应时间
图3显示了不同服务的平均响应时间。由于养蜂人服务依赖于工作人员服务,因此其响应时间比工作人员服务更长。
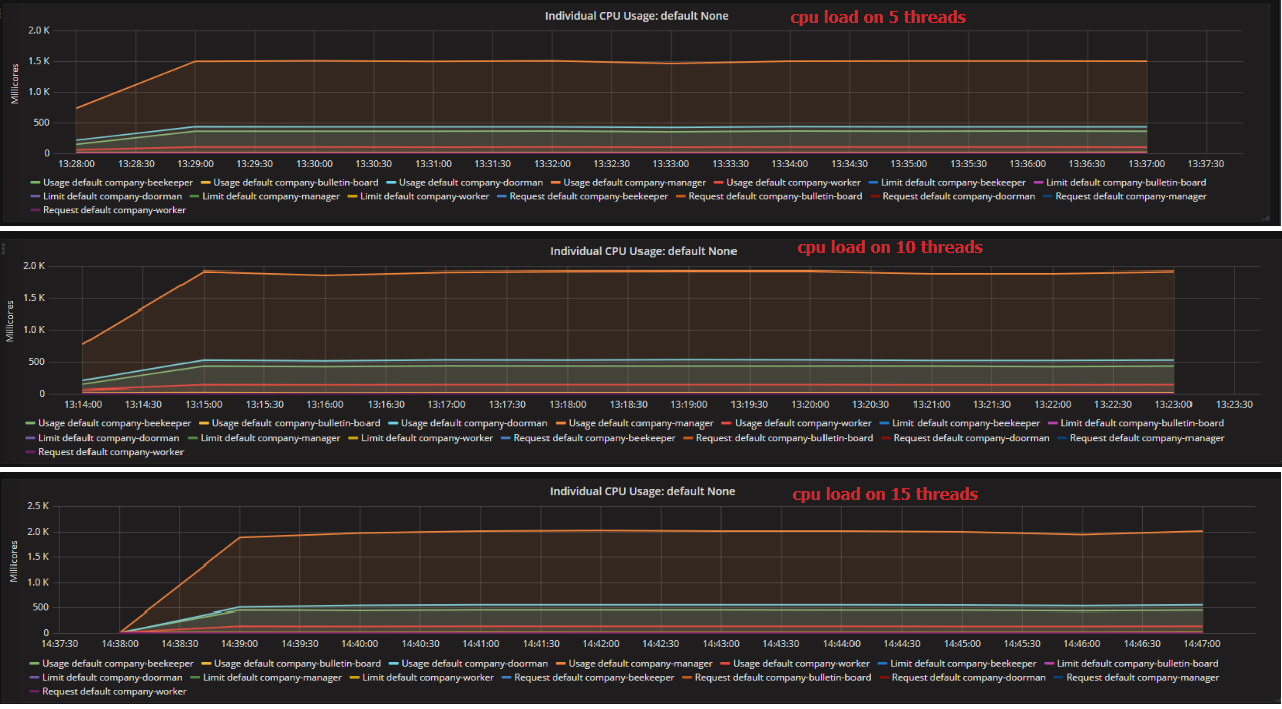 图4各种并发的CPU负载
图4各种并发的CPU负载
为了找出性能坚持15的并发性,我们检查了来自Heapster的监控数据,如图4所示。显然,经理服务成为整个系统的瓶颈。当吞吐量大约为1000 req / s时,它达到了最大cpu负载。其他服务的增长速度远低于经理服务,并且所需资源较少。
由于管理器服务直接记录到stdout,并且在单个主机上运行的JMeter测试客户端可能无法同时模拟足够的并发。因此,我们在200的并发性上测试了日志设置的不同场景(log4j1 stdout,log4j2 stdout,log4j2 asynchronous,none).log4j2.xml文件中的异步日志设置如下:
<?xml version="1.0" encoding="UTF-8" ?>
<Configuration status="INFO">
<Appenders>
<RandomAccessFile name="RandomAccessFile" fileName="manager.log" immediateFlush="false" append="false">
<PatternLayout pattern="%d [%p] %m %l%n"/>
</RandomAccessFile>
</Appenders>
<Loggers>
<asyncRoot level="info">
<AppenderRef ref="RandomAccessFile"/>
</asyncRoot>
</Loggers>
</Configuration>
此外,我们还需要添加disruptor依赖项以启用异步日志设置。
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.3.6</version>
</dependency>
在没有日志设置只需更换信息日志记录级别,以关闭在上面的设置。我们还测试了分布式JMeter测试客户端环境。在分布式模式下运行Jmeter需要两个步骤:
在每个测试节点上运行JMeter slave,命令如下:
jmeter-server -Djava.rmi.server.hostname=$(ifconfig eth0 | grep "inet addr" | awk '{print $2}' | cut -d ":" -f2)
运行JMeter master,命令如下:
jmeter -n -R host1,host2 -t workshop.jmx -j workshop.log -l workshop.jtl -Gmin=1 -Gmax=2 -Gthreads=200 -Gduration=600
注意: JMeter属性在分布式模式下不起作用。它需要被声明为全局属性。这就是我们在这里使用-G选项而不是-J选项的原因。
结果如下: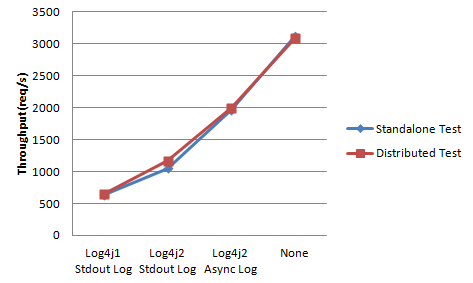 从上图中我们可以得出结论:
从上图中我们可以得出结论:
JMeter分布式模式和单模式的性能非常接近,似乎单个JMeter测试客户端能够为当前测试模拟足够的并发性。
直接输出到stdout时,日志占用了太多的计算资源,异步方式提高了原始吞吐量的近100%。在生产环境中使用同步日志设置似乎不太明智。
log4j2提高了log4j1的吞吐量约40%,并减少了少量内存。因此,为了提高性能,建议将log4j1替换为log4j2。
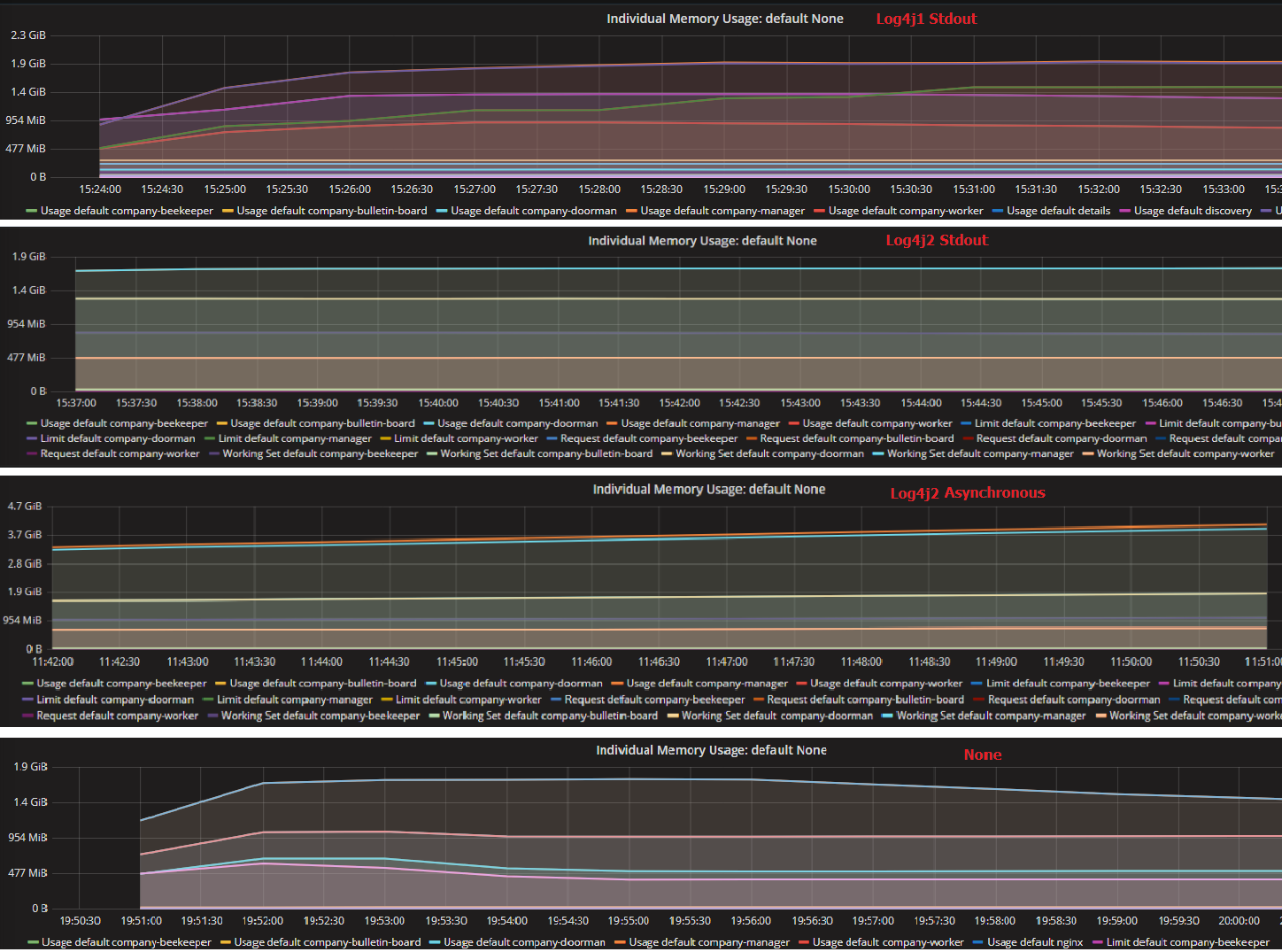 图-5不同日志设置的内存使用情况
图-5不同日志设置的内存使用情况
虽然异步方式为我们节省了大量的计算资源,但同时如图5所示,它占用了大量内存。
 图6内存使用不同的服务
图6内存使用不同的服务
图6显示了测试期间不同服务的内存使用情况。由于公司演示是一个简单的用例,因此在测试期间内存使用率保持相当稳定。与公告板服务的内存使用(用go编写)相比,用Java编写的其他服务会占用大量内存。
结论
对应用程序进行压力测试可以帮助我们在生产环境中运行服务之前发现服务中的潜在问题。它模拟生产环境并验证我们的服务是否符合规范要求。我们可以根据压力测试结果将我们的pod部署设置调整为系统的最大吞吐量,同时保持SLA。
基于微服务架构的应用程序不仅在设计,编程和测试方面变得更加灵活,而且在部署方面也变得更加灵活。基于微服务架构的服务使资源可以非常快速地扩展和缩小。我们可以根据最大吞吐量为不同的服务选择不同规格的机器和不同的副本,以节省资源。此外,云的可扩展性使服务容易处理访问风暴。
Kubernetes集群中Jmeter对公司演示的压力测试的更多相关文章
- (转)在Kubernetes集群中使用JMeter对Company示例进行压力测试
背景 压力测试是评估应用性能的一种有效手段.此外,越来越多的应用被拆分为多个微服务而每个微服务的性能不一,有的微服务是计算密集型,有的是IO密集型. 因此,压力测试在基于微服务架构的网络应用中扮演着越 ...
- 初试 Kubernetes 集群中使用 Traefik 反向代理
初试 Kubernetes 集群中使用 Traefik 反向代理 2017年11月17日 09:47:20 哎_小羊_168 阅读数:12308 版权声明:本文为博主原创文章,未经博主允许不得转 ...
- 【转载】浅析从外部访问 Kubernetes 集群中应用的几种方式
一般情况下,Kubernetes 的 Cluster Network 是属于私有网络,只能在 Cluster Network 内部才能访问部署的应用.那么如何才能将 Kubernetes 集群中的应用 ...
- 在Kubernetes集群中使用calico做网络驱动的配置方法
参考calico官网:http://docs.projectcalico.org/v2.0/getting-started/kubernetes/installation/hosted/kubeadm ...
- 在kubernetes集群中创建redis主从多实例
分类 > 正文 在kubernetes集群中创建redis主从多实例 redis-slave镜像制作 redis-master镜像制作 创建kube的配置文件yaml 继续使用上次实验环境 ht ...
- Kubernetes集群中Service的滚动更新
Kubernetes集群中Service的滚动更新 二月 9, 2017 0 条评论 在移动互联网时代,消费者的消费行为已经“全天候化”,为此,商家的业务系统也要保持7×24小时不间断地提供服务以满足 ...
- kubernetes集群中的pause容器
昨天晚上搭建好了k8s多主集群,启动了一个nginx的pod,然而每启动一个pod就伴随这一个pause容器,考虑到之前在做kubelet的systemd unit文件时有见到: 1 2 3 4 5 ...
- 解决项目迁移至Kubernetes集群中的代理问题
解决项目迁移至Kubernetes集群中的代理问题 随着Kubernetes技术的日益成熟,越来越多的企业选择用Kubernetes集群来管理项目.新项目还好,可以选择合适的集群规模从零开始构建项目: ...
- 如何在 Kubernetes 集群中玩转 Fluid + JuiceFS
作者简介: 吕冬冬,云知声超算平台架构师, 负责大规模分布式机器学习平台架构设计与功能研发,负责深度学习算法应用的优化与 AI 模型加速.研究领域包括高性能计算.分布式文件存储.分布式缓存等. 朱唯唯 ...
随机推荐
- linux学习11 Linux基础命令及命令历史
一.Linux系统上的文件类型 1.- :常规文件:在其它程序中用f表示.比如我们用ls -l命令查看的第一个内容 [root@localhost ~]# ls -l total -rw------- ...
- shell中脚本参数传递getopts
while getopts ":a:b:c:" opt do case $opt in a) echo "参数a的值$OPTARG" ;; b) echo &q ...
- Mongoose 预定义模式修饰符 Getters 与 Setters 自定义修饰符
mongoose 预定义模式修饰符 mongoose 提供的预定义模式修饰符,可以对我们增加的数据进行一些格式化,主要有:lowercase.uppercase .trim,这里不一一演示,对trim ...
- R包 survival 生存分析
https://cran.r-project.org/web/packages/survival/index.html
- sql server查看表大小
查看SqlServer 数据库中各个表多少行 : SELECT A.NAME ,B.ROWS FROM sysobjects A JOIN sysindexes B ON A.id = B.id WH ...
- vs code搭建python和tensorflow环境
anaconda 安装tensorflow-gpu环境见https://www.cnblogs.com/wintersoft/p/11620267.html vscode中设置python虚拟环境Ct ...
- 支付宝小程序开发——如何获取支付宝小程序页面的https链接
前边介绍过通过配置支付宝Scheme协议alipays://来实现h5到小程序的跳转,其实还可以获取小程序页面的https格式链接,虽然支付宝官方并没有直接提供方案,但是通过小程序后台的“码管理”给页 ...
- 编写基于TCP的应用程序
编写基于TCP的应用程序 这似乎是一个非常简单的话题, 就跟"是个人就能做网站"一样, 你可能也认为"是个人就能写使用TCP socket的网络程序". 不 ...
- 闲聊一下百度的Unit
这几天在弄一个闲聊的机器人,想起之前的图灵机器人,捣鼓之后,发现用不了,咨询后得知,以前是可以免费使用,一天1000次,后来降到100次,其实也没有那么多人去闲聊,也无所谓,再后来,需要手持身份证实名 ...
- IntelliJ IDEA 安装使用 FindBugs 代码分析详述
1 下载 2 重启idea 选中文件,右键 附:一些常见的错误信息 Bad practice 代码中的一些坏习惯 Class names should start with an upper case ...