不同版本的ArcMap在Oracle中创建镶嵌数据集的不同行为
如果不同版本的ArcMap连接到同一个Oracle数据库上,分别执行"创建镶嵌数据集",它们的行为是一样的吗?
答案是:不一样,会有细微的差别
在本例中,ArcMap的版本分别是10.2.2与10.3,数据库服务器的版本是11.2.0.3,SDE Repository 的版本是10.1 。
- 使用10.3版本的ArcMap创建镶嵌数据集 MD1003
在创建镶嵌数据集之前,创建user_objects的备份表user_objects_b;

创建镶嵌数据集,完成后,数据库新增了如下的表、序列、触发器。
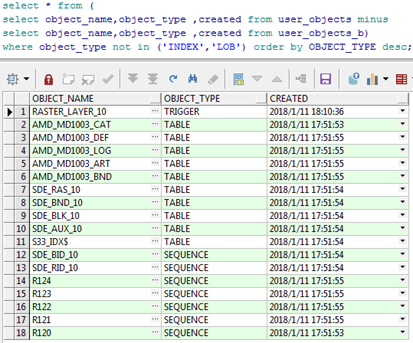
新增了1个触发器,10个表,7个序列。
这里有两个知识点,我稍微介绍一下。
其一,RASTER_LAYER_10以及SDE_RAS_10名称中的10代表什么?
这个值实际代表的是AMD_MD1003_CAT在sde. RASTER_COLUMNS表中rastercolumn_id字段的值,如下图:

其二,R120-R124这几个序列的数字代表什么?
这个值实际上代表的是上图以AMD开头的5张表在sde.table_registry表中registration_id字段的值,如下图:

R120-R124这几个序列是为了给所对应表的OBJECTID字段赋值而存在的。
那这几个序列是如何定义的呢?我们来看看:

注意这里序列的最大值为1028。
- 使用10.2.2版本的ArcMap创建镶嵌数据集 MD1002
删除user_objects_b,并重新创建user_objects的备份表user_objects_b;

创建镶嵌数据集,完成后,数据库新增了如下的表、序列、触发器。

新增了1个触发器,9个表,6个序列。与10.3版本创建镶嵌数据集相比,少了一个以AMD_%_DEF表以及该表所对应的序列。
同时,由上图可知,AMD_MD1002_CAT的rastercolumn_id值为11,如下图:

R开头的序列与AMD开头表的对应关系如下图:

序列的定义如下:

注意这里序列的最大值为2147483647,远小于10.3版本创建的序列最大值。
结论:
- 对于"创建镶嵌数据集"这一操作,尽管数据库版本和SDE repository 版本一致,但ArcMap版本的差异仍然会导致不同的递归操作。由此可以引申推测:对于其它操作,不排除因版本不同而导致最终行为不同的情况发生,所以测试与最终生产环节的使用,最好使用同样版本的ArcMap版本。
- 使用10.2.2版本创建的镶嵌数据集,其序列最大值为10亿级别,而每次递增值为16,因此可用的值仅为亿级,对于庞大的镶嵌数据集(包含多个数据集,或发生多次删除重入场景)极有可能导致序列被用满而造成添加数据集失败。(另外,由于序列的CACHE值为20,如果经常关闭实例,或经常执行"alter system flush shared_pool"会造成序列产生很多的"洞",而这些"洞"会加速突破序列的最大值限制)
不同版本的ArcMap在Oracle中创建镶嵌数据集的不同行为的更多相关文章
- 用ArcMap在PostgreSQL中创建要素类需要执行”create enterprise geodatabase”吗
问:用Acmap在PostgreSQL中创建要素类需要执行"create enterprise geodatabase"吗? 关于这个问题,是在为新员工做postgresql培训后 ...
- 在ArcMap 10.3中创建和编辑数据
在ArcMap 10.3中创建和编辑数据 .......待补充 新建 创建一个新文件((Points, Polylines, and Polygons/点.线.多边形)
- 在oracle中创建空间索引
Oracle spatial可以方便的存储空间数据,大量的空间数据必需要使用空间索引去查询.在oracle中创建空间索引必需先建立元数据,否则无法创建索引.创建元数据的代码: insert into ...
- oracle中创建数据库
一.在Oracle中创建数据库之前先改一下虚拟机的IP地址,以便访问 2. 3. 3.1 3.2 3.3 3.4 创建完成:输入sqlplus sys/123456 as sysdba测试
- Oracle中创建自增字段方法
oracle没有ORACLE自增字段这样的功能,但是通过触发器(trigger)和序列(sequence)可以实现. 下面给大家讲个例子: 1.在Oracle中创建一个表: .创建一个表 ) prim ...
- oracle中创建sequence指定起始值
oracle中创建sequence指定起始值 DECLARE V_Area_Id NUMBER; BEGIN SELECT MAX(T.Area_Id)+10 INTO V_Area_Id FROM ...
- Oracle中创建触发器示例及注意事项
1.oracle 中创建触发器示例 CREATE TABLE "CONCEPT"."FREQUENCYMODIFYLOG" ( "FREQUENCYI ...
- 在oracle中创建自动增长字段
参考http://www.cnblogs.com/jerrmy/archive/2013/03/13/2958352.html http://www.jb51.net/article/43382.ht ...
- Oracle中创建千万级大表归纳
从一月至今,我总共归纳了三种创建千万级大表的方案,它们是: 下面是这三种方案的对比表格: # 名称 地址 主要机制 速度 1 在Oracle中十分钟内创建一张千万级别的表 https://www.cn ...
随机推荐
- python 二、八、十六进制之间的快速转换
一.进制转换 1.2 十进制转二进制 bin(18)--> '0b10010' 去掉0b就是10010 即为十进制18转二进制是10010 十进制转八进制oct(18) --> ...
- 非阻塞IO的实现方式
1.状态轮询: 2.状态订阅: 3.完成回掉:
- Arduino OV7670 live image over USB to PC
https://www.youtube.com/watch?v=L9DTW1ulsT0 https://www.youtube.com/watch?v=Dp3RMb0e1eA
- Tasking
Put your plan on the tick list, and set the completion time limit, daily repetition, etc. according ...
- Python I/O编程 -- 序列化
序列化 pickle模块,json模块 (1)把变量从内存中变成可存储或传输的过程,称之为序列化.Python中叫pickling,其他语言中也被称为serialization,marshalling ...
- 数组排序代码,冒泡排序&快速排序&选择排序
冒泡排序: for(var i=0;i<arr.length-1;i++){ for(var j=0;j<arr.length-1-i;j++){ if(arr[j]>arr[j+1 ...
- LINUX下的gdb调试方法
首先对目标文件进行编译 例如: gcc test.c -o test 这时会生成一个文件test,然后我们就可以对test进行调试了 示例: gdb test 好了以后是设定断点 示例: break ...
- A1139 | 玩成模拟题的DFS
考试的时候有思路了,但是没写完.这题起码要40min写,思路太诡异了. 刚刚写了一段,只过了一个case,得了18分,还行.明日再战. #include <stdio.h> #includ ...
- 洛谷 P1195 【口袋的天空】
P1195 传送门 大体题意: 就是给你\(n\)个点\(m\)条边, 然后让你把这几个点连成\(k\)个部分. 解题思路: 很容易就可以想到生成树(别问我怎么想到的). 因为最小生成树中有一个判断 ...
- nginx之动静分离(nginx与php不在同一台服务器)
nginx实现动静分离(nginx与php不在同一个服务器) 使用wordpress-5.0.3-zh_CN.tar.gz做实验 Nginx服务器的配置: [root@app ~]# tar xf w ...