Linux 内核 hlist 详解
在Linux内核中,hlist(哈希链表)使用非常广泛。本文将对其数据结构和核心函数进行分析。
和hlist相关的数据结构有两个:hlist_head 和 hlist_node
//hash桶的头结点
struct hlist_head
{
struct hlist_node *first;//指向每一个hash桶的第一个结点的指针
};
//hash桶的普通结点
struct hlist_node
{
struct hlist_node *next;//指向下一个结点的指针
struct hlist_node **pprev;//指向上一个结点的next指针的地址
};
结构如下图所示:
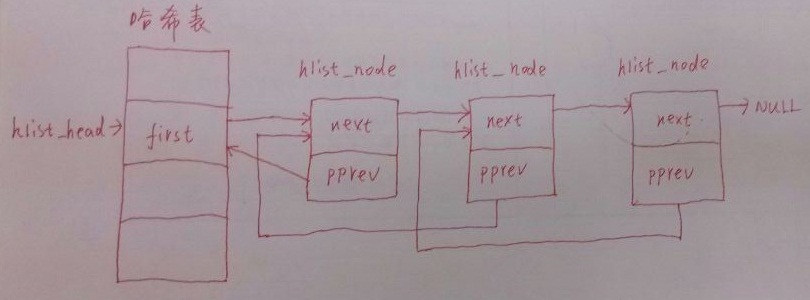
hlist_head结构体只有一个域,即first。 first指针指向该hlist链表的第一个节点。
hlist_node结构体有两个域,next 和pprev。 next指针很容易理解,它指向下个hlist_node结点,倘若该节点是链表的最后一个节点,next指向NULL。
pprev是一个二级指针, 它指向前一个节点的next指针的地址。为什么我们需要这样一个指针呢?它的好处是什么?
在回答这个问题之前,我们先研究另一个问题:为什么哈希表的实现需要两个不同的数据结构?
哈希表的目的是为了方便快速的查找,所以哈希表中hash桶的数量通常比较大,否则“冲突”的概率会非常大,这样也就失去了哈希表的意义。如何做到既能维护一张大表,又能不使用过多的内存呢?就只能从数据结构上下功夫了。所以对于哈希表的每个hash桶,它的结构体中只存放一个指针,解决了占用空间的问题。现在又出现了另一个问题:数据结构不一致。显然,如果hlist_node采用传统的next,prev指针,对于第一个节点和后面其他节点的处理会不一致。这样并不优雅,而且效率上也有损失。
hlist_node巧妙地将pprev指向上一个节点的next指针的地址,由于hlist_head的first域指向的结点类型和hlist_node指向的下一个结点的结点类型相同,这样就解决了通用性!
如果要删除hash桶对应链表中的第一个普通结点
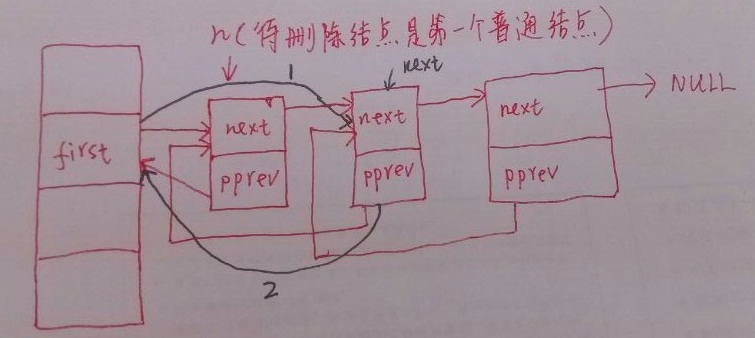
对应的程序代码如下:
static inline void __hlist_del(struct hlist_node *n)
{
struct hlist_node *next = n->next;//获取指向第二个普通结点的指针
struct hlist_node **pprev = n->pprev;//保留待删除的第一个结点的pprev域(即头结点first域的地址),此时 pprev = &first
*pprev = next;
/*
因为pprev = &first,所以*pprev = next,相当于 first = next
即将hash桶的头结点指针指向原来的第二个结点,如上图中的黑线1
*/
if (next) //如果第二个结点不为空
next->pprev = pprev;//将第二个结点的pprev域设置为头结点first域的地址,如上图中的黑线2
}
代码精简后
static inline void __hlist_del(struct hlist_node *n)
{
n->pprev=&(n->next);
if (next)
n->next->pprev =n->pprev;
}
如果要删除hash桶对应链表中的非第一个结点
对应的程序代码如下:
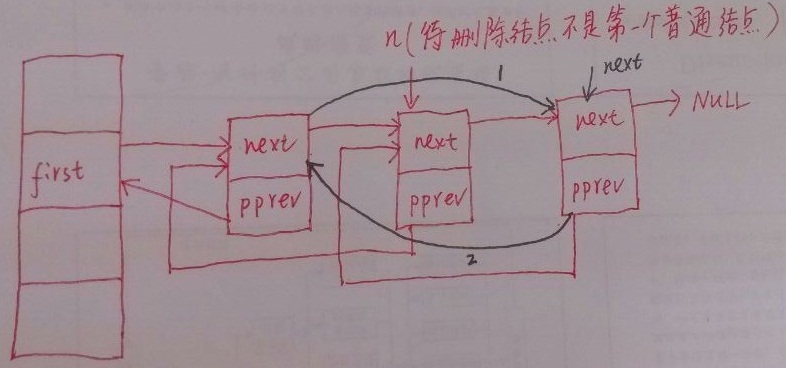
static inline void __hlist_del(struct hlist_node *n)
{
struct hlist_node *next = n->next;//获取指向待删除结点的下一个普通结点的指针
struct hlist_node **pprev = n->pprev;//获取待删除结点的pprev域
*pprev = next; //修改待删除结点的pprev域,逻辑上使待删除结点的前驱结点指向待删除结点的后继结点,如上图中的黑线1
if (next) //如果待删除结点的下一个普通结点不为空
next->pprev = pprev;//设置下一个结点的pprev域,如上图中的黑线2,保持hlist的结构
}
代码精简后
static inline void __hlist_del(struct hlist_node *n)
{
n->pprev=&(n->next);
if (next)
n->next->pprev =n->pprev;
}
可以看到删除第一个普通结点和删除非第一个普通结点的代码是一样的。
下面再来看看如果hlist_node中包含两个分别指向前驱结点和后继结点的指针
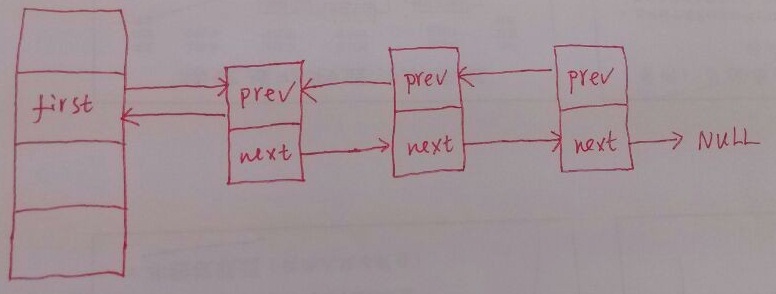
很明显删除hash桶对应链表中的非第一个普通结点,只需要如下两行代码:
n->next->prev = n->prev;
n->prev->next = n->next;
可是,如果是删除的hash桶对应链表中的第一个普通结点:
此时 n->prev->next = n->next 就会出问题,因为hash桶的表头结点没有next域
所以,明显在这种情况下删除hash桶对应链表的第一个普通结点和非第一个普通结点的代码是不一样的。
同样的情况也存在于插入操作。
附一张在hash桶头结点之后,插入第一个普通结点的图:
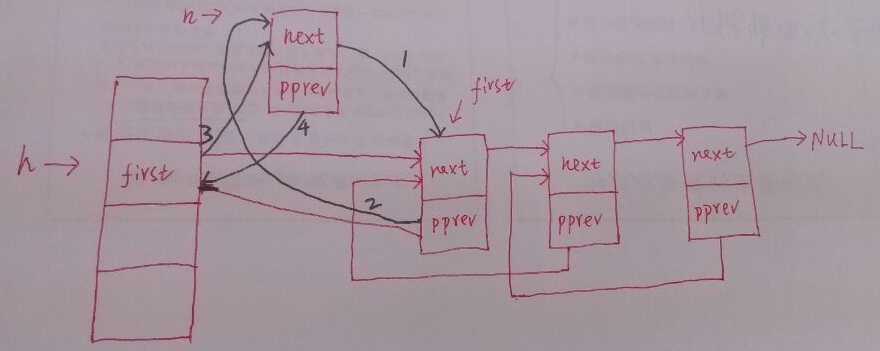
在遍历上,如果使用hlist_hode, list_node指针进行遍历,两者过程大致相似。
#define list_for_each(pos, head) \
for (pos = (head)->next; prefetch(pos->next), pos != (head); \
pos = pos->next)
#define hlist_for_each(pos, head) \
for (pos = (head)->first; pos && ({ prefetch(pos->next); 1; }); \
pos = pos->next)
如果使用其寄生结构的指针进行遍历,则hlist与list也略有不同,hlist在遍历时需要一个指向hlist_node的临时指针,该指针的引入,一是为了遍历,而list的遍历在list_entry的参数中实现了,更主要的目的在于判断结束,因为hlist最后一个节点的next为NULL,只有hlist_node指向NULL时才算结束,而这个NULL不包含在任何寄生结构内,不能通过tpos->member的方式访问到,故临时变量pos的引入时必须的。
#define list_for_each_entry(pos, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member); \
prefetch(pos->member.next), &pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))
#define hlist_for_each_entry(tpos, pos, head, member) \
for (pos = (head)->first; \
pos && ({ prefetch(pos->next); 1;}) && \
({ tpos = hlist_entry(pos, typeof(*tpos), member); 1;}); \
pos = pos->next)
另外,list和hlist的遍历都实现了safe版本,因在遍历时,没有任何特别的东西来阻止对链表执行删除操作(通常在使用链表时使用锁来保护并发访问)。安全版本的遍历函数使用临时存放的方法使得检索链表时能不被删除操作所影响。
#define list_for_each_safe(pos, n, head) \
for (pos = (head)->next, n = pos->next; pos != (head); \
pos = n, n = pos->next)
#define hlist_for_each_safe(pos, n, head) \
for (pos = (head)->first; pos && ({ n = pos->next; 1; }); \
pos = n)
附上linux内核中与hlist相关的完整代码:
//hash桶的头结点
struct hlist_head
{
struct hlist_node *first;//指向每一个hash桶的第一个结点的指针
};
//hash桶的普通结点
struct hlist_node
{
struct hlist_node *next;//指向下一个结点的指针
struct hlist_node **pprev;//指向上一个结点的next指针的地址
};
//以下三种方法都是初始化hash桶的头结点
#define HLIST_HEAD_INIT { .first = NULL }
#define HLIST_HEAD(name) struct hlist_head name = { .first = NULL }
#define INIT_HLIST_HEAD(ptr) ((ptr)->first = NULL)
//初始化hash桶的普通结点
static inline void INIT_HLIST_NODE(struct hlist_node *h)
{
h->next = NULL;
h->pprev = NULL;
}
//判断一个结点是否已经存在于hash桶中
static inline int hlist_unhashed(const struct hlist_node *h)
{
return !h->pprev;
}
//判断一个hash桶是否为空
static inline int hlist_empty(const struct hlist_head *h)
{
return !h->first;
}
static inline void __hlist_del(struct hlist_node *n)
{
struct hlist_node *next = n->next;//获取指向待删除结点的下一个结点的指针
struct hlist_node **pprev = n->pprev;//保留待删除结点的pprev域
*pprev = next;//修改待删除结点的pprev域,逻辑上使待删除结点的前驱结点指向待删除结点的后继结点
if (next)
next->pprev = pprev;//设置待删除结点的下一个结点的pprev域,保持hlist的结构
}
static inline void hlist_del(struct hlist_node *n)
{
__hlist_del(n);//删除结点之后,需要将其next域和pprev域设置为无用值
n->next = LIST_POISON1;
n->pprev = LIST_POISON2;
}
static inline void hlist_del_init(struct hlist_node *n)
{
if (!hlist_unhashed(n))
{
__hlist_del(n);
INIT_HLIST_NODE(n);
}
}
//将普通结点n插入到头结点h对应的hash桶的第一个结点的位置
static inline void hlist_add_head(struct hlist_node *n, struct hlist_head *h)
{
struct hlist_node *first = h->first;
n->next = first;
if (first)
first->pprev = &n->next;
h->first = n;
n->pprev = &h->first;
}
/* next must be != NULL */
//在next结点之前插入结点n,即使next结点是hash桶中的第一个结点也可以
static inline void hlist_add_before(struct hlist_node *n, struct hlist_node *next)
{
n->pprev = next->pprev;
n->next = next;
next->pprev = &n->next;
*(n->pprev) = n;
}
//在结点next之后插入结点n
static inline void hlist_add_after(struct hlist_node *n, struct hlist_node *next)
{
n->next = next->next;
next->next = n;
n->pprev = &next->next;
if(n->next)
n->next->pprev = &n->next;
}
/* 用新的hlist_head 更换旧的hlist_head */
static inline void hlist_move_list(struct hlist_head *old, struct hlist_head *new)
{
new->first = old->first;
if (new->first)
new->first->pprev = &new->first;
old->first = NULL;
}
//通过一个结构体内部一个成员的地址获取结构体的首地址
#define hlist_entry(ptr, type, member) container_of(ptr,type,member)
#define hlist_for_each(pos, head) \
for (pos = (head)->first; pos && ({ prefetch(pos->next); 1; }); \
pos = pos->next)
#define hlist_for_each_safe(pos, n, head) \
for (pos = (head)->first; pos && ({ n = pos->next; 1; }); \
pos = n)
/**
* hlist_for_each_entry - iterate over list of given type
* @tpos: the type * to use as a loop cursor.
* @pos: the &struct hlist_node to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the hlist_node within the struct.
*/
#define hlist_for_each_entry(tpos, pos, head, member) \
for (pos = (head)->first; \
pos && ({ prefetch(pos->next); 1;}) && \
({ tpos = hlist_entry(pos, typeof(*tpos), member); 1;}); \
pos = pos->next)
/**
* hlist_for_each_entry_continue - iterate over a hlist continuing after current point
* @tpos: the type * to use as a loop cursor.
* @pos: the &struct hlist_node to use as a loop cursor.
* @member: the name of the hlist_node within the struct.
*/
#define hlist_for_each_entry_continue(tpos, pos, member) \
for (pos = (pos)->next; \
pos && ({ prefetch(pos->next); 1;}) && \
({ tpos = hlist_entry(pos, typeof(*tpos), member); 1;}); \
pos = pos->next)
/**
* hlist_for_each_entry_from - iterate over a hlist continuing from current point
* @tpos: the type * to use as a loop cursor.
* @pos: the &struct hlist_node to use as a loop cursor.
* @member: the name of the hlist_node within the struct.
*/
#define hlist_for_each_entry_from(tpos, pos, member) \
for (; pos && ({ prefetch(pos->next); 1;}) && \
({ tpos = hlist_entry(pos, typeof(*tpos), member); 1;}); \
pos = pos->next)
/**
* hlist_for_each_entry_safe - iterate over list of given type safe against removal of list entry
* @tpos: the type * to use as a loop cursor.
* @pos: the &struct hlist_node to use as a loop cursor.
* @n: another &struct hlist_node to use as temporary storage
* @head: the head for your list.
* @member: the name of the hlist_node within the struct.
*/
#define hlist_for_each_entry_safe(tpos, pos, n, head, member) \
for (pos = (head)->first; \
pos && ({ n = pos->next; 1; }) && \
({ tpos = hlist_entry(pos, typeof(*tpos), member); 1;}); \
pos = n)
Linux 内核 hlist 详解的更多相关文章
- uboot引导linux内核过程详解【转】
http://blog.chinaunix.net/uid-7828352-id-4472376.html 写的不错,尤其是uboot向linux内核传递参数的过程写的比较详细.
- 必须知道的Linux内核常识详解
一.内核功能.内核发行版 1.到底什么是操作系统 (1)linux.windows.android.ucos就是操作系统: (2)操作系统本质上是一个程序,由很多个源文件构成,需要编译连接成操作系统程 ...
- 【转】Linux内核结构详解
Linux内核主要由五个子系统组成:进程调度,内存管理,虚拟文件系统,网络接口,进程间通信. 1.进程调度 (SCHED):控制进程对CPU的访问.当需要选择下一个进程运行时,由调度程序选择最值得运行 ...
- linux内核sysfs详解【转】
转自:http://blog.csdn.net/skyflying2012/article/details/11783847 "sysfs is a ram-based filesystem ...
- Linux内核参数详解
所谓Linux服务器内核参数优化(适合Apache.Nginx.Squid等多种web应用,特殊的业务有可能需要做略微调整),主要是指在Linux系统中针对业务服务应用而进行的系统内核参数调整,优化并 ...
- Linux启动过程详解(inittab、rc.sysinit、rcX.d、rc.local)
启动第一步--加载BIOS 当你打开计算机电源,计算机会首先加载BIOS信息,BIOS信息是如此的重要,以至于计算机必须在最开始就找到它.这是因为BIOS中包含了CPU的相关信息.设备启动顺序信息.硬 ...
- Linux启动过程详解
Linux启动过程详解 附上两张图,加深记忆 图1: 图2: 第一张图比较简洁明了,下面对第一张图的步骤进行详解: 加载BIOS 当你打开计算机电源,计算机会首先加载BIOS信息,BIOS信息是如此的 ...
- Linux /dev目录详解和Linux系统各个目录的作用
Linux /dev目录详解(转http://blog.csdn.net/maopig/article/details/7195048) 在linux下,/dev目录是很重要的,各种设备都在下面.下面 ...
- linux iostat命令详解 磁盘操作监控工具
Linux系统中的 iostat是I/O statistics(输入/输出统计)的缩写,iostat工具将对系统的磁盘操作活动进行监视. 它的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使用情况. ...
随机推荐
- Trouble shooting(问题解决):centos 7 gnome show someting has gone wrong.
centos 7 升级 内核 3.10,startx启动不了了.进界面也是oh,no!someting has gone wrong . 参见帖子:http://bbs.csdn.net/topics ...
- mysql复杂查询
所谓复杂查询,指涉及多个表.具有嵌套等复杂结构的查询.这里简要介绍典型的几种复杂查询格式. 一.连接查询 连接是区别关系与非关系系统的最重要的标志.通过连接运算符可以实现多个表查询.连接查询主要包括内 ...
- 普通PC安装ESXi5.5以及以上的方法
原贴内容 With ESXi 5, ESX no longer uses MBR for boot, it has gone to GPT-based partitions instead. W ...
- python之设置控制台字体颜色
# 设置控制台输出字体颜色 # 格式:\033[显示方式;前景色;背景色m # 采用终端默认设置:\033[0m # 红色字体 print('\033[1;31m') print('*' * 10) ...
- Highcharts之折线图
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- r=a*(1-sinx)
a=-2*pi:.001:2*pi; %设定角度b=(1-sin(a)); %设定对应角度的半径polar(a, b,'r') %绘图 夏目漱石“今夜月色很好” 王家卫“我已经很久没有坐过摩托车了,也 ...
- 在property里面设置版本号可灵活引用
- python异常提示表
Python常见的异常提示及含义对照表如下: 异常名称 描述 BaseException 所有异常的基类 SystemExit 解释器请求退出 KeyboardInterrupt 用户中断执行(通常是 ...
- Assign the task HDU - 3974(dfs序+线段树)
There is a company that has N employees(numbered from 1 to N),every employee in the company has a im ...
- BZOJ 2901: 矩阵求和
2901: 矩阵求和 Time Limit: 20 Sec Memory Limit: 256 MBSubmit: 411 Solved: 216[Submit][Status][Discuss] ...