Kafka介绍与消息队列
消息队列的好处:
消息队列(Message Queue)
消息: 网络中的两台计算机或者两个通讯设备之间传递的数据。例如说:文本、音乐、视频等内容。
队列:一种特殊的线性表(数据元素首尾相接),特殊之处在于只允许在首部删除元素和在尾部追加元素。入队、出队。
消息队列:顾名思义,消息+队列,保存消息的队列。消息的传输过程中的容器;主要提供生产、消费接口供外部调用做数据的存储和获取。
消息队列分类
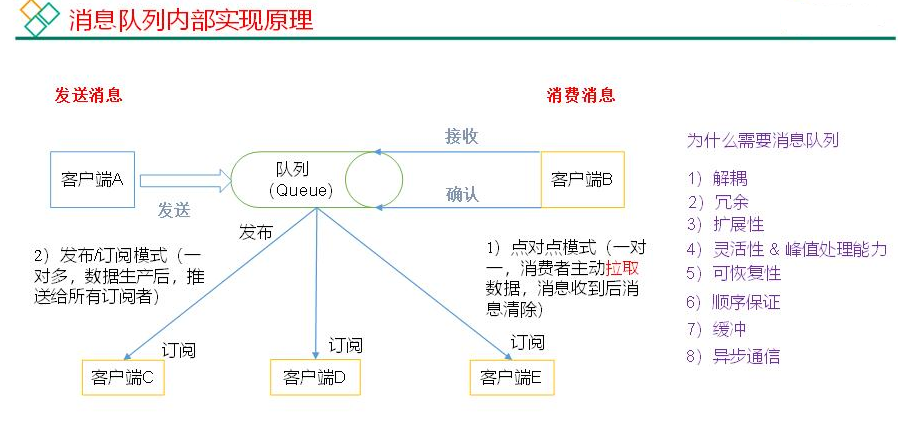
MQ分类:点对点(P2P)、发布订阅(Pub/Sub)
共同点:消息生产者生产消息发送到queue中,然后消息消费者从queue中读取并且消费消息。
不同点: P2P模型包含:消息队列(Queue)、发送者(Sender)、接收者(Receiver)一个生产者生产的消息只有一个消费者(Consumer)(即一旦被消费,消息就不在消息队列中)。打电话。
Pub/Sub包含:消息队列(Queue)、主题(Topic)、发布者(Publisher)、订阅者(Subscriber)
每个消息可以有多个消费者,彼此互不影响。比如我发布一个微博:关注我的人都能够看到。
消息队列模式
- 点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接收者接收处理,即使有多个消息监听者也是如此。
- 发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
发布订阅模型则是一个基于推送的消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即使当前订阅者不可用,处于离线状态。
消息队列的实现原理
消息队列的好处
- 解耦:允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
- 冗余:消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的”插入-获取-删除”范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
- 扩展性:因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。
- 灵活性 & 峰值处理能力: 在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
- 可恢复性:系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
- 顺序保证:在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。(Kafka保证一个Partition内的消息的有序性)
- 缓冲:有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
- 异步通信:很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
!
Kafka
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
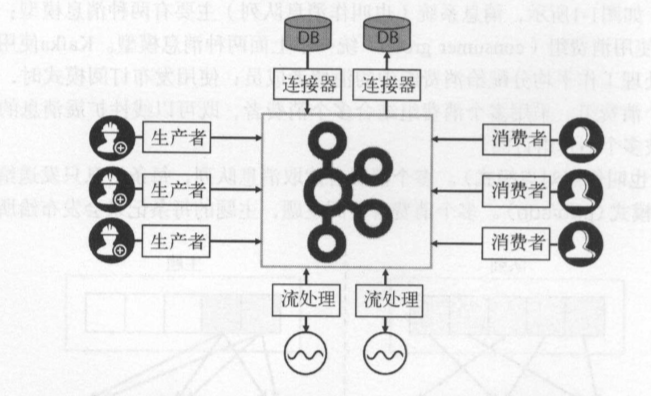
Producer :消息生产者,就是向kafka broker发消息的客户端;
- Consumer :消息消费者,向kafka broker取消息的客户端;
- Topic :可以理解为一个队列
- Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic;
- Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic;
- Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序;
- Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka。
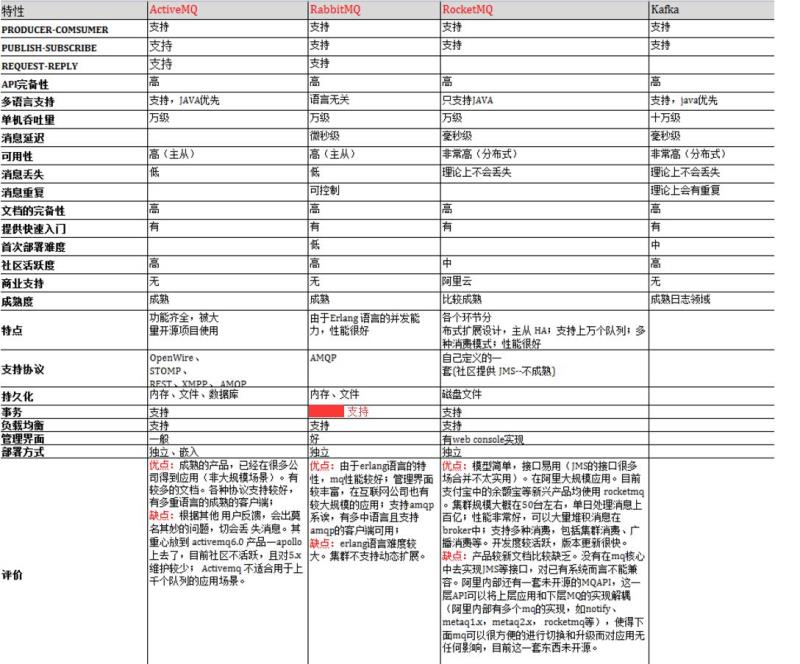
Kafka 和其他消息队列的比较
Kafka介绍与消息队列的更多相关文章
- RabbitMQ,RocketMQ,Kafka 几种消息队列的对比
常用的几款消息队列的对比 前言 RabbitMQ 优点 缺点 RocketMQ 优点 缺点 Kafka 优点 缺点 如何选择合适的消息队列 参考 常用的几款消息队列的对比 前言 消息队列的作用: 1. ...
- Kafka与常见消息队列的对比
Kafka与常见消息队列的对比 RabbitMQ Erlang编写 支持很多的协议:AMQP,XMPP, SMTP, STOMP 非常重量级,更适合于企业级的开发 发送给客户端时先在中心队列排队.对路 ...
- kafka——分布式的消息队列系统
总听公司人说kafka kafka... 所以这玩意到底是个啥? 好像是一个高级版的消息队列,什么高吞吐量,数据持久,消息均衡,emmm https://blog.csdn.net/nawenqian ...
- 深入浅出理解基于 Kafka 和 ZooKeeper 的分布式消息队列
消息队列中间件是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题.实现高性能,高可用,可伸缩和最终一致性架构,是大型分布式系统不可缺少的中间件. 本场 Chat 主要内容: Kafk ...
- Kafka消息队列初识
一.Kafka简介 1.1 什么是kafka kafka是一个分布式.高吞吐量.高扩展性的消息队列系统.kafka最初是由Linkedin公司开发的,后来在2010年贡献给了Apache基金会,成为了 ...
- 消息队列的使用<一>:介绍、使用场景和JMS概念知识
目录 介绍 消息队列的理解 举个栗子 使用场景 消息队列的模型与概念理解 JMS模型 基本概念: 内容: JMS定义的消息结构: PTP式消息传递 PUB/SUB式消息传递 可靠性机制 事务 消息持久 ...
- Kafka 和 ZooKeeper 的分布式消息队列分析
1. Kafka 总体架构 基于 Kafka-ZooKeeper 的分布式消息队列系统总体架构如下: 如上图所示,一个典型的 Kafka 体系架构包括若干 Producer(消息生产者),若干 bro ...
- 第1节 kafka消息队列:11、kafka的数据不丢失机制,以及kafka-manager监控工具的使用;12、课程总结
12.kafka如何保证数据的不丢失 12.1生产者如何保证数据的不丢失 kafka的ack机制:在kafka发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够被收到 如果是同步模 ...
- 消息队列——kafka
原文:再过半小时,你就能明白kafka的工作原理了 会出现什么情况呢? 1.为了这个女朋友,我请假回去拿(老板不批). 2.小哥一直在你楼下等(小哥还有其他的快递要送). 3.周末再送(显然等不及). ...
随机推荐
- VSTO:使用C#开发Excel、Word【15】
使用文档属性DocumentProperties集合和DocumentProperty对象位于Microsoft Office 11.0 Object Library(office.dll)中,该对象 ...
- Vuejs的$watch实现原理
大概原理如下面代码所示: class Vue { //Vue对象 constructor (options) { this.$options=options; let data = this._dat ...
- Java容器解析系列(5) AbstractSequentialList LinkedList 详解
AbstractSequentialList为顺序访问的list提供了一个骨架实现,使实现顺序访问的list变得简单; 我们来看源码: /** AbstractSequentialList 继承自 A ...
- ionic2一个需求模块的文件该是这样子的
1.组件文件夹的文件 除了index.ts 其他文件为各个页面组件文件 2.index.ts的代码如下 import {SecurityFinance} from "./security-f ...
- JAVA集合接口及类
各接口及类关系图 Iterable 所有集合的初始接口,实现该接口可进行foreach操作,只有一个iterator()方法,并返回iterator类型: Iterable在java.lang下,It ...
- mysql8.0.13 的docker镜像安装
1.从docker中获取mysql8.0.13镜像 docker pull mysql:8.0.13通过 docker images 命令查看镜像是否获取到了 2.运行 mysql8.0.13 镜像 ...
- Hide Data into bitmap with ARGB8888 format
将保存重要信息,如银行卡密码的文本文件隐藏到ARGB8888的A通道. bitmap.h #ifndef BMP_H #define BMP_H #include <fstream> #i ...
- Django runserver UnicodeDecodeError
编码问题可以说是我遇到过的python 2.7最大的败笔 今天写django时,很简单的一个项目却报UnicodeDecodeError,而我的代码中一个中文字符都没有出现. 如下: 网上找到的所谓解 ...
- 周强 201771010141《面向对象程序设计(java)》第四周学习总结
实验目的与要求 (1) 理解用户自定义类的定义: (2) 掌握对象的声明: (3) 学会使用构造函数初始化对象: (4) 使用类属性与方法的使用掌握使用: (5) 掌握package和import语句 ...
- 自动化测试-14.selenium加载FireFox配置
前言 有小伙伴在用脚本启动浏览器时候发现原来下载的插件不见了,无法用firebug在打开的页面上继续定位页面元素,调试起来不方便 . 加载浏览器配置,需要用FirefoxProfile(profile ...