在Java Web中使用Spark MLlib训练的模型
PMML是一种通用的配置文件,只要遵循标准的配置文件,就可以在Spark中训练机器学习模型,然后再web接口端去使用。目前应用最广的就是基于Jpmml来加载模型在javaweb中应用,这样就可以实现跨平台的机器学习应用了。
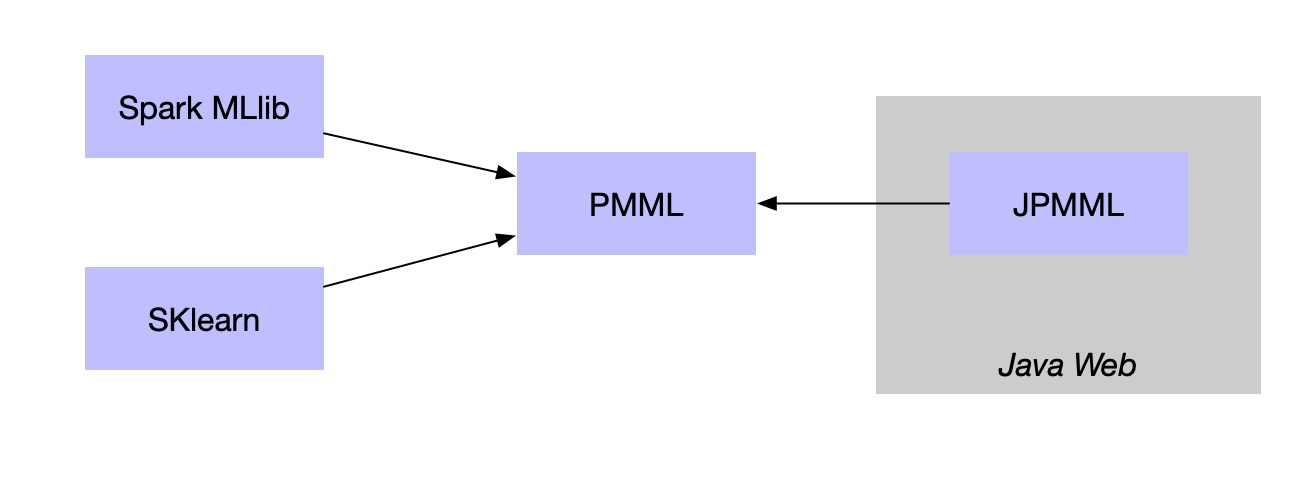
训练模型
首先在spark MLlib中使用mllib包下的逻辑回归训练模型:
import org.apache.spark.mllib.classification.{LogisticRegressionModel, LogisticRegressionWithLBFGS}
import org.apache.spark.mllib.evaluation.MulticlassMetrics
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.util.MLUtils
val training = spark.sparkContext
.parallelize(Seq("0,1 2 3 1", "1,2 4 1 5", "0,7 8 3 6", "1,2 5 6 9").map( line => LabeledPoint.parse(line)))
// Run training algorithm to build the model
val model = new LogisticRegressionWithLBFGS()
.setNumClasses(2)
.run(training)
val test = spark.sparkContext
.parallelize(Seq("0,1 2 3 1").map( line => LabeledPoint.parse(line)))
// Compute raw scores on the test set.
val predictionAndLabels = test.map { case LabeledPoint(label, features) =>
val prediction = model.predict(features)
(prediction, label)
}
// Get evaluation metrics.
val metrics = new MulticlassMetrics(predictionAndLabels)
val accuracy = metrics.accuracy
println(s"Accuracy = $accuracy")
// Save and load model
// model.save(spark.sparkContext, "target/tmp/scalaLogisticRegressionWithLBFGSModel")
// val sameModel = LogisticRegressionModel.load(spark.sparkContext,"target/tmp/scalaLogisticRegressionWithLBFGSModel")
model.toPMML(spark.sparkContext, "/tmp/xhl/data/test2")
训练得到的模型保存到hdfs。
PMML模型文件
模型下载到本地,重新命名为xml。
可以看到默认四个特征分别叫做feild_0,field_1...目标为target
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<PMML version="4.2" xmlns="http://www.dmg.org/PMML-4_2">
<Header description="logistic regression">
<Application name="Apache Spark MLlib" version="2.2.0"/>
<Timestamp>2018-11-15T10:22:25</Timestamp>
</Header>
<DataDictionary numberOfFields="5">
<DataField name="field_0" optype="continuous" dataType="double"/>
<DataField name="field_1" optype="continuous" dataType="double"/>
<DataField name="field_2" optype="continuous" dataType="double"/>
<DataField name="field_3" optype="continuous" dataType="double"/>
<DataField name="target" optype="categorical" dataType="string"/>
</DataDictionary>
<RegressionModel modelName="logistic regression" functionName="classification" normalizationMethod="logit">
<MiningSchema>
<MiningField name="field_0" usageType="active"/>
<MiningField name="field_1" usageType="active"/>
<MiningField name="field_2" usageType="active"/>
<MiningField name="field_3" usageType="active"/>
<MiningField name="target" usageType="target"/>
</MiningSchema>
<RegressionTable intercept="0.0" targetCategory="1">
<NumericPredictor name="field_0" coefficient="-5.552297758753701"/>
<NumericPredictor name="field_1" coefficient="-1.4863480719075117"/>
<NumericPredictor name="field_2" coefficient="-5.7232298850417855"/>
<NumericPredictor name="field_3" coefficient="8.134075057437393"/>
</RegressionTable>
<RegressionTable intercept="-0.0" targetCategory="0"/>
</RegressionModel>
</PMML>
接口使用
在接口的web工程中引入maven jar:
<!-- https://mvnrepository.com/artifact/org.jpmml/pmml-evaluator -->
<dependency>
<groupId>org.jpmml</groupId>
<artifactId>pmml-evaluator</artifactId>
<version>1.4.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.jpmml/pmml-evaluator-extension -->
<dependency>
<groupId>org.jpmml</groupId>
<artifactId>pmml-evaluator-extension</artifactId>
<version>1.4.3</version>
</dependency>
接口代码中直接读取pmml,使用模型进行预测:
package soundsystem;
import org.dmg.pmml.FieldName;
import org.dmg.pmml.PMML;
import org.jpmml.evaluator.*;
import java.io.FileInputStream;
import java.io.InputStream;
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
public class PMMLDemo2 {
private Evaluator loadPmml(){
PMML pmml = new PMML();
try(InputStream inputStream = new FileInputStream("/Users/xingoo/Desktop/test2.xml")){
pmml = org.jpmml.model.PMMLUtil.unmarshal(inputStream);
} catch (Exception e) {
e.printStackTrace();
}
ModelEvaluatorFactory modelEvaluatorFactory = ModelEvaluatorFactory.newInstance();
return modelEvaluatorFactory.newModelEvaluator(pmml);
}
private Object predict(Evaluator evaluator,int a, int b, int c, int d) {
Map<String, Integer> data = new HashMap<String, Integer>();
data.put("field_0", a);
data.put("field_1", b);
data.put("field_2", c);
data.put("field_3", d);
List<InputField> inputFields = evaluator.getInputFields();
//过模型的原始特征,从画像中获取数据,作为模型输入
Map<FieldName, FieldValue> arguments = new LinkedHashMap<FieldName, FieldValue>();
for (InputField inputField : inputFields) {
FieldName inputFieldName = inputField.getName();
Object rawValue = data.get(inputFieldName.getValue());
FieldValue inputFieldValue = inputField.prepare(rawValue);
arguments.put(inputFieldName, inputFieldValue);
}
Map<FieldName, ?> results = evaluator.evaluate(arguments);
List<TargetField> targetFields = evaluator.getTargetFields();
TargetField targetField = targetFields.get(0);
FieldName targetFieldName = targetField.getName();
ProbabilityDistribution target = (ProbabilityDistribution) results.get(targetFieldName);
System.out.println(a + " " + b + " " + c + " " + d + ":" + target);
return target;
}
public static void main(String args[]){
PMMLDemo2 demo = new PMMLDemo2();
Evaluator model = demo.loadPmml();
demo.predict(model,2,5,6,8);
demo.predict(model,7,9,3,6);
demo.predict(model,1,2,3,1);
demo.predict(model,2,4,1,5);
}
}
得到输出内容:
2 5 6 8:ProbabilityDistribution{result=1, probability_entries=[1=0.9999949538769296, 0=5.046123070395758E-6]}
7 9 3 6:ProbabilityDistribution{result=0, probability_entries=[1=1.1216598160542013E-9, 0=0.9999999988783402]}
1 2 3 1:ProbabilityDistribution{result=0, probability_entries=[1=2.363331367481431E-8, 0=0.9999999763666864]}
2 4 1 5:ProbabilityDistribution{result=1, probability_entries=[1=0.9999999831203591, 0=1.6879640907241367E-8]}
其中result为LR最终的结果,概率为二分类的概率。
参考资料
- 官方文档:https://openscoring.io/
- JPMML官方文档:https://github.com/jpmml/jpmml-evaluator
- jpmml-sklearn:https://github.com/jpmml/jpmml-sklearn
- jpmml-sparkml:https://github.com/jpmml/jpmml-sparkml/tree/master
- 用PMML实现机器学习模型的跨平台上线:http://www.cnblogs.com/pinard/p/9220199.html
- PMML模型文件在机器学习的实践经验:https://blog.csdn.net/hopeztm/article/details/78321700
在Java Web中使用Spark MLlib训练的模型的更多相关文章
- Java Web 中 过滤器与拦截器的区别
过滤器,是在java web中,你传入的request,response提前过滤掉一些信息,或者提前设置一些参数,然后再传入servlet或者struts的 action进行业务逻辑,比如过滤掉非法u ...
- JAVA WEB 中的编码分析
JAVA WEB 中的编码分析 */--> pre.src {background-color: #292b2e; color: #b2b2b2;} pre.src {background-co ...
- Java web中常见编码乱码问题(一)
最近在看Java web中中文编码问题,特此记录下. 本文将会介绍常见编码方式和Java web中遇到中文乱码问题的常见解决方法: 一.常见编码方式: 1.ASCII 码 众所周知,这是最简单的编码. ...
- Java web中常见编码乱码问题(二)
根据上篇记录Java web中常见编码乱码问题(一), 接着记录乱码案例: 案例分析: 2.输出流写入内容或者输入流读取内容时乱码(内容中有中文) 原因分析: a. 如果是按字节写入或读取时乱码, ...
- 深入分析Java Web中的编码问题
编码问题一直困扰着我,每次遇到乱码或者编码问题,网上一查,问题解决了,但是实际的原理并没有搞懂,每次遇到,都是什么头疼. 决定彻彻底底的一次性解决编码问题. 1.为什么要编码 计算机的基本单元是字节, ...
- 解决java web中safari浏览器下载后文件中文乱码问题
解决java web中safari浏览器下载后文件中文乱码问题 String fileName = "测试文件.doc"; String userAgent = request.g ...
- Java Web 中使用ffmpeg实现视频转码、视频截图
Java Web 中使用ffmpeg实现视频转码.视频截图 转载自:[ http://www.cnblogs.com/dennisit/archive/2013/02/16/2913287.html ...
- java web中servlet、jsp、html 互相访问的路径问题
java web中servlet.jsp.html 互相访问的路径问题 在java web种经常出现 404找不到网页的错误,究其原因,一般是访问的路径不对. java web中的路径使用按我的分法可 ...
- java web 中 读取windows图标并显示
java web中读取windows对应文件名的 系统图标 ....显示 1.获取系统图标工具类 package utils; import java.awt.Graphics; import j ...
随机推荐
- JMeter处理返回结果unicode转码为中文
问题举例: { "ServerCode":"200","ServerMsg":"\u6210\u529f"," ...
- 微信小程序星星评价
https://www.jianshu.com/p/4d7359dfa040
- Secondary Indices
[Secondary Indices] EOSIO has the ability to sort tables by up to 16 indices. A table's struct cann ...
- java学习笔记(十):scanner输入
可以通过 Scanner 类来获取用户的输入. 通过next()类和nextLine()类来获取字符串. 通过 Scanner 类的 next() 类来获取输入的字符串. import java.ut ...
- springboot整合mybatis遇到的那些坑
1.接口类(指*Mapper.java)在spring中注册的问题 当控制台打印如下信息: A component required a bean named '*Mapper' that could ...
- POJ-2387.Til the Cows Come Home.(五种方法:Dijkstra + Dijkstra堆优化 + Bellman-Ford + SPFA + Floyd-Warshall)
昨天刚学习完最短路的算法,今天开始练题发现我是真的菜呀,居然能忘记邻接表是怎么写的,真的是菜的真实...... 为了弥补自己的菜,我决定这道题我就要用五种办法写出,并在Dijkstra算法堆优化中另外 ...
- 华为NB-IOT报告
转 https://blog.csdn.net/np4rHI455vg29y2/article/details/78958137 [NB-IoT]华为NB-IoT网络报告(完整版) 2018年01月0 ...
- 项目总结18-使用textarea无法判断空值之坑
项目总结18-使用textarea无法判断空值之坑 今天使用js判断textarea为空,发现怎么都无法成功仔细做了对比测试,发现结果如下: 1-JS代码 if($("#content&qu ...
- PHP开发——超全局数组变量
概述 l JS中的变量分两类:局部变量.全局变量. l PHP中的变量分三类:局部变量.全局变量.超全局变量. l 局部变量:在函数内部声明的变量,就是局部变量.函数执行完毕,局部变量就消失了. ...
- maven插件后报错:org.apache.maven.archiver.MavenArchiver.getManifest(org.apache.maven.project
在给eclipse换了高版本的maven插件后,引入jar包报如下的错误: org.apache.maven.archiver.MavenArchiver.getManifest(org.apache ...