SqlServer中的UNION操作符在合并数据时去重的原理以及UNION运算符查询结果默认排序的问题
本文出处:http://www.cnblogs.com/wy123/p/7884986.html
周围又有人在讨论UNION和UNION ALL,对于UNION和UNION ALL,网上说的最多的就是性能问题(实在不想说出来这句话:UNION ALL比UNION快)
其实根本不想炒UNION和UNION ALL这碗剩饭了,
每次看到网上说用这个不用那个,列举的一条一条的那种文章,只要看到说UNION ALL比UNION性能好的就……
对于合并的结果集,UNION是去重的,UNION ALL是不去重的,去重与不去重是两个目的,分别由UNION和UNION ALL实现
两个作用(功能)不同的东西,放一起比性能有什么意义?
这种问题真的是无聊至极,就好比“足球场上的某个中后卫和某个前腰哪个能力更强”一样没有可比性,
他们的作用本身就是不同的,难道说中后卫能力不行,把他撤下来,用一个牛逼的前腰球员替代中后卫,或者是前腰能力不行,撤下他用牛逼的中后卫替代?
这是在功能上的区别,至于性能,我个人认为对比起来没有任何意义。
如果非要放一起比的话,做同样的数据合并,
UNION因为要去重,相对UNION ALL来说,(相对)当然会耗费更多的资源(耗费的资源多少跟性能无关,做的事情多,当然需要更多的资源)
但是一定要弄清楚,合并数据的时候,到底要不要去掉重复数据,这是最终结果对与错的问题,不是性能问题!
这里不讨论UNION和UNION ALL的性能了,
从另外一个点入手来发起问题
UNION与UNION ALL最大的区别就是UNION会去重,那么问题就来了,这个去重是怎么实现的?去重会对查询的默认顺序集产生什么影响?
UNION去重的实现
测试一下UNION运算符去重的实现原理
create table TestUnion1
( Id1 INT PRIMARY KEY,
Id2 tinyint,
Name varchar(100)
);
create table TestUnion2
(
Id1 INT PRIMARY KEY,
Id2 tinyint,
Name varchar(100)
); insert into TestUnion1 values (500,9,'aaa')
insert into TestUnion1 values (700,3,'ccc')
insert into TestUnion1 values (200,7,'eee') insert into TestUnion2 values (300,2,'bbb')
insert into TestUnion2 values (800,8,'ddd')
insert into TestUnion2 values (100,5,'fff') --TestUnionALL1和TestUnionALL2中相同的数据
insert into TestUnion1 values (600,6,'xxx')
insert into TestUnion2 values (600,6,'xxx')
UNION在去重的过程中,使用的执行计划是Merge Join,UNION ALL是不去重的,同样步骤对应的执行计划是Concatenation
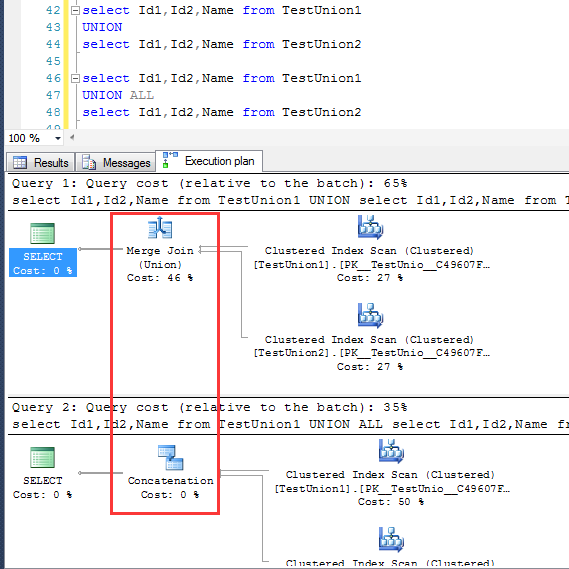
这里UNION的去重动作是通过merge实现,这里的merge join并不是表与表之间的merge join
这里可以看出来,UNION产生的merge与 inner join产生的Merge的作用是有差异的

对于UNION的去重的这一动作,去当然不是说只有merge join一种,这里只不过是两个结果的数据都刚好有序才采用merge join来去重罢了
如果查询字段的顺序的第一个字段是聚集索引(或者主键),,正如上文提到的,UNION的双方就会以merge的方式区中
如果查询字段的顺序非聚集索引,UNION的过程是现将两个结果集合并起来(上文提到的Concatenation),然后再做sort排序去重
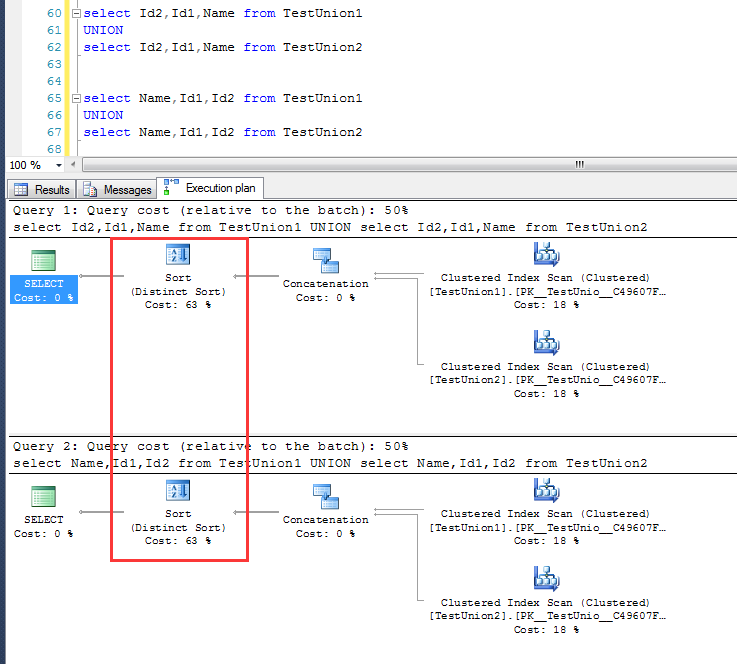
UNION之后结果集的最终排序结果
UNION之后结果集的最终排序结果跟查询字段的顺序有关,
如果查询字段的顺序的第一个字段是聚集索引(或者主键),正如上文提到的,UNION的双方就会以merge的方式区中
如果查询字段的顺序的第一个字段是非聚集索引字段,UNION的过程是现将两个结果集合并起来(上文提到的Concatenation),然后再做sort排序去重
如下的实例能说说明这个问题,当查询字段的顺序发生变化之后,两者的执行计划完全不一致。
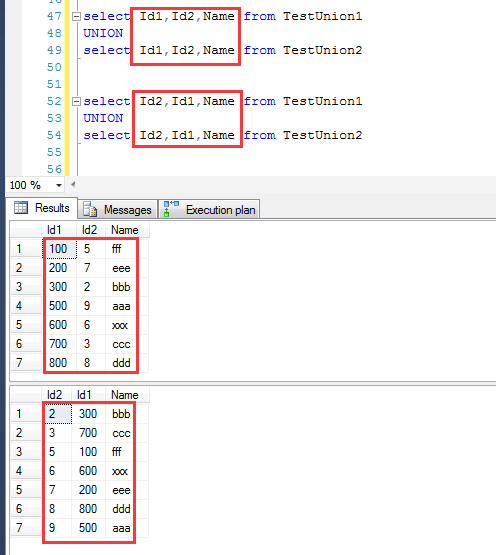

或者再看一个case,当Name在最前面的时候,最终的结果就是按照name排序。
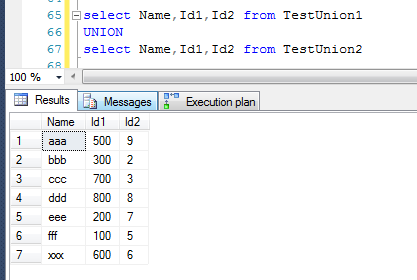
可能有人会怀疑是不是数据量太小了,是不是巧合,这里可以加大测试数据库,在查询条件中,让非聚集索引参与到运算之中
create table TestUnion1
( Id1 INT PRIMARY KEY,
Id2 tinyint,
Name varchar(100),
CreateDate datetime
); create table TestUnion2
(
Id1 INT PRIMARY KEY,
Id2 tinyint,
Name varchar(100),
CreateDate datetime
); begin tran
declare @i int = 0
while @i<1000000
begin
insert into TestUnion1 values (@i,rand()*200,newid(),getdate()-rand()*1000)
insert into TestUnion2 values (@i,rand()*200,newid(),getdate()-rand()*1000)
set @i=@i+1
end
commit create index idx_CreateDate on TestUnion1(CreateDate)
create index idx_CreateDate on TestUnion2(CreateDate)
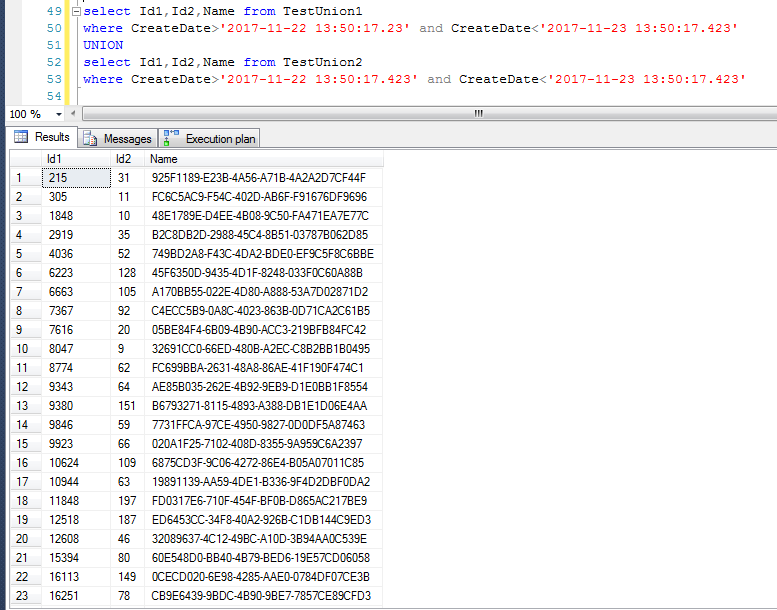
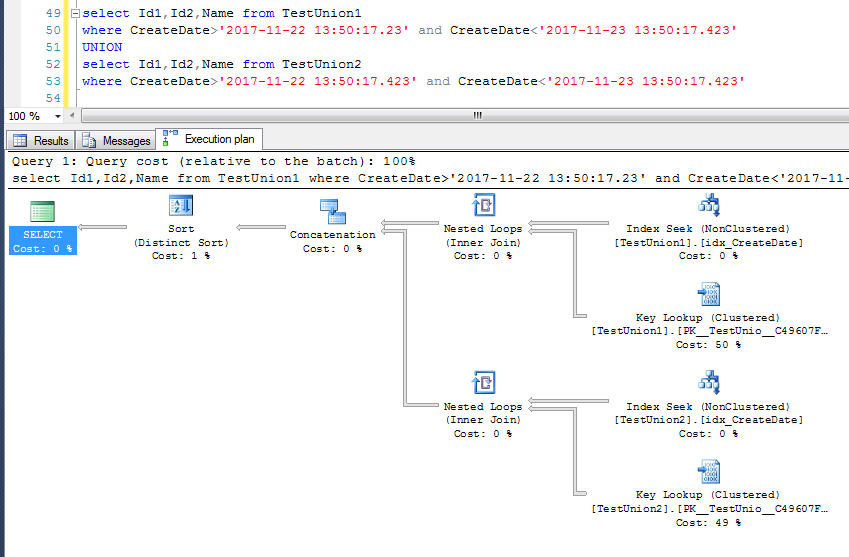
参考下图,一旦查询结果集不是按照查询字段聚集索引排序的话,
比如这里走的是createDate时间字段的索引,执行计划都是先按照普通的方式合并结果集,也即Concatenation
然后在利用Sort(Distinct)的方式排序去重,对于去重的结果的最终的排序,跟查询结果的第一个字段有关,且结果总是按照查询的第一个字段排序的。
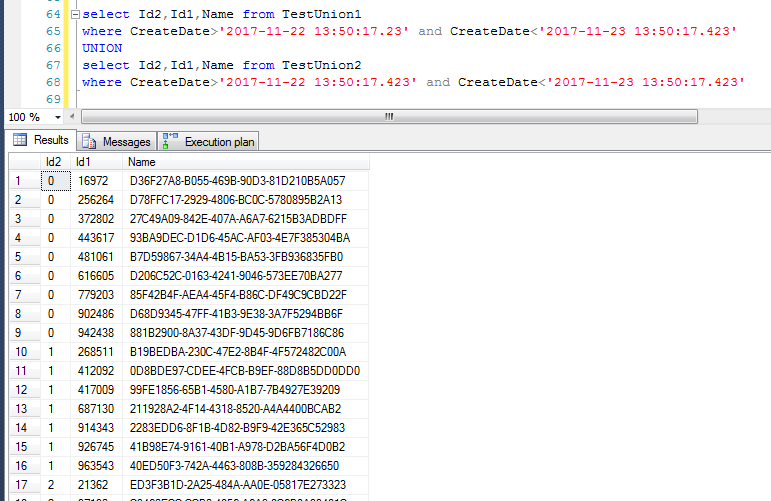
换一种查询字段的顺序方式,看一下结果,仍旧是按照查序列的第一个字段排序的
UNION运算符在去重的时候,
如果查询字段的第一个字段是聚集索引,那么会用merge join的方式合并+去重。
如果查询字段的第一个字段不是非聚集索引,那么首先会将两个(或者多个)结果集进行普通的合并,最后通过Sort Distinct的方式去重。
且UNION运算之后的默认排序方式,受查询字段前后的方式影响。
总结:
UNION和UNION ALL的作用是不一样的,放在一起比性能没有任何意义,真不想趟这趟浑水。
合并结果集,需要去重就用UNION,不需要去重就用UNION ALL,如果两个结果集中没有重复的结果集,就用UNION ALL,
这纯粹是需求驱动的,而不是UNION和UNION ALL的性能问题。
多撤一句:
曾经大晚上接到一个面试电话,没有任何开场白,第一句话是“我们电话面试一下可以吗”,答曰可以,第二句话就是“UNION和UNION ALL的区别是什么,有没有性能差异”。
真的不希望再去对UNION和UNION ALL的性能上做讨论。
SqlServer中的UNION操作符在合并数据时去重的原理以及UNION运算符查询结果默认排序的问题的更多相关文章
- SQLSERVER中的非工作时间不得插入数据的触发器的实现
create trigger trigger_nameon table_namefor insert,update,deleteasif (datepart(yy,getdate())%4=0 or ...
- sqlserver 中,如何将getdate()时间的时分秒固定为00:00:00或者忽略不要
在使用getdate()时,时间会实时刷新,那么我们就要再查询的时候就需要精确到毫秒后三位,非常难受,那么为了解决这个问题我们可以通过以下几种方法进行固定或者去掉毫秒 1.将毫秒固定为00:00:00 ...
- Ms SQLServer中的Union和Union All的使用方法和区别
Ms SQLServer中的Union和Union All的使用方法和区别 SQL UNION 操作符 UNION 操作符用于合并两个或多个 SELECT 语句的结果集. 请注意,UNION 内部的 ...
- [转]在SqlServer 中解析JSON数据
在Sqlserver中可以直接处理Xml格式的数据,但因为项目需要所以要保存JSON格式的数据到Sqlserver中在博客:Consuming JSON Strings in SQL Server ...
- SQL 语句中的union操作符
前端时间,用到了union操作符,周末有时间总结下,w3c手册内容如下: SQL UNION操作符 UNION操作符用于合并两个或多个select语句的结果集. 注意:UNION内部select语句必 ...
- SQL UNION操作符使用
SQL UNION 操作符 SQL UNION 操作符合并两个或多个 SELECT 语句的结果. SQL UNION 操作符 UNION 操作符用于合并两个或多个 SELECT 语句的结果集. 请注意 ...
- SQL UNION 操作符
转由http://www.w3school.com.cn/sql/sql_union.asp 这个网址的数据库知识,个人推荐,因为有实例,理解更透彻一些.非广告啊,个人感觉好啊 SQL UNION 操 ...
- SQLSERVER:大容量导入数据时保留标识值 (SQL Server)
从MSDN上看到实现大容量导入数据时保留标识值得方法包含三种: MSDN链接地址为:https://msdn.microsoft.com/zh-cn/library/ms178129.aspx 感觉M ...
- QStandardItemModel的data线程安全(在插入数据时,临时禁止sizeHint去读model中的data)
版权声明:本文为博主原创文章,欢迎转载,转载请注明出处 https://blog.csdn.net/MatchYang/article/details/52988257 在直接使用QStandardI ...
随机推荐
- Python 进程池的同步方法和异步方法
import time from multiprocessing import Process,Pool def f1(n): time.sleep(0.5) # print(n) return n* ...
- 1.2 pip降级selenium3.0
1.2 pip降级selenium3.0 selenium版本安装后启动Firefox出现异常:'geckodriver' executable needs to be in PATHselenium ...
- Win10+Ubuntu双系统删除Ubuntu方法
前情提要 Win10下试了许多种方法,什么MbrFix.EasyBCD.亦或是Boot Option.都不行.前两者不行,操作之后重启无法直接进入Windows,后者也不行,找不到所谓的Delete ...
- License控制解决方案
当我们写完一个软件以后一般都会牵扯到软件控制,那么控制版本的原理是什么呢?其实就是在程序中添加了一段经过自己编写算法(这个算法可以是简单的公式运算,也可以是复杂的结合硬件的绑定方式),将形成的序列号注 ...
- 导入maven项目导入依赖不会报错,但使用的jar会标红
方法1: 1.通过编译找到报错的jar; 2.在 repository找到此jar,一般未下载完大小为1k我的是这样(); 3.删除未下载完全的jar,在项目上执行maven reimport会重新下 ...
- hsdfz -- 6.16 -- day1
恩这回不写游记了 按照老师要求记录今天的心里路程:这题似乎可做期望得分150->日部分分似乎不是很显然->a题似乎是结论题,大力猜一波结论->过不了样例,先看b题->b题动态树 ...
- 第三章 JQuery: HelloWorld--常见方法--css--选择器--筛选器--属性--效果--事件--数组操作--字符串操作--对象转换
1.jQuery简介 为了简化JavaScript 的开发, 一些JavsScript 库诞生了. JavaScript库封装了很多预定义的对象和实用函数.能帮助使用者建立有高难度交互的页面, 并且兼 ...
- windos下安装django
一:pip install Django 安装完以后,运行python manager.py runserver 0.0.0.0:8000报错: 1):没有安装Mysql-python ...
- 1.1.15 word调整文字与下划线之间的间距
先请按CTRL+U快捷键,或点击“下划线”按钮,然后输入一个空格,再输入文字“下划线间距”,在文字的尾部再添加一个空格.选中文字内容(注意不要选中首尾的空格),单击菜单“格式”→“字体”,在“字体”设 ...
- C语言数组指针
C语言中的数组指针与指针数组: ·数组指针一.区分 首先我们需要了解什么是数组指针以及什么是指针数组,如下: int *p[5];int (*p)[5];数组指针的意思即为通过指针引用数组,p先和*结 ...