Line Search and Quasi-Newton Methods 线性搜索与拟牛顿法
Gradient Descent
机器学习中很多模型的参数估计都要用到优化算法,梯度下降是其中最简单也用得最多的优化算法之一。梯度下降(Gradient Descent)[3]也被称之为最快梯度(Steepest Descent),可用于寻找函数的局部最小值。梯度下降的思路为,函数值在梯度反方向下降是最快的,只要沿着函数的梯度反方向移动足够小的距离到一个新的点,那么函数值必定是非递增的,如图1所示。
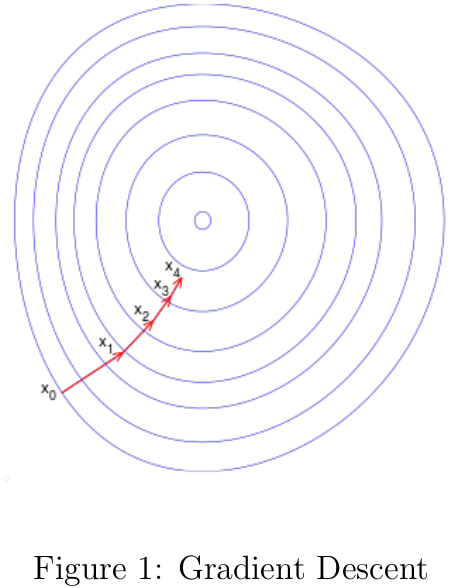
梯度下降思想的数学表述如下:
其中f(x)f(x)为存在下界的可导函数。根据该思路,如果我们从x0x0为出发点,每次沿着当前函数梯度反方向移动一定距离αkαk,得到序列x0,x1,⋯,xnx0,x1,⋯,xn:
对应的各点函数值序列之间的关系为:
很显然,当nn达到一定值时,函数f(x)f(x)是会收敛到局部最小值的。算法1简单描述了一般化的梯度优化方法。 在算法1中,我们需要选择一个搜索方向dkdk满足以下关系:
在算法1中,我们需要选择一个搜索方向dkdk满足以下关系:
当dk=−∇f(x)dk=−∇f(x)时f(x)f(x)下降最快,但是只要满足∇f(xk)Tdk<0∇f(xk)Tdk<0的dkdk都可以作为搜素方向。一般搜索方向表述为如下形式:
其中BkBk为正定矩阵。当Bk=IBk=I时对应最快梯度下降算法;当Bk=H(xk)−1Bk=H(xk)−1时对应牛顿法,如果H(xk)=∇2f(xk)H(xk)=∇2f(xk)为正定矩阵。 在迭代过程中用于更新xkxk的步长αkαk可以是常数也可以是变化的。如果αkαk足够小,收敛是可以得到保证的,但这意味这迭代次数nn要很大时函数才会收敛(图2(a));如果αkαk比较大,更新后的点很可能越过局部最优解(图2(b))。有什么方法可以帮助我们自动确定最优步长呢?下面要说的线性搜索就包含一组解决方案。
Line Search
在给定搜索方向dkdk的前提下,线性搜索要解决的问题如下:
如果h(α)h(α)是可微的凸函数,我们能通过解析解直接求得上式最优的步长;但非线性的优化问题需要通过迭代形式求得近似的最优步长。对于上式,局部或全局最优解对应的导数为h′(α)=∇f(xk+αdk)Tdk=0h′(α)=∇f(xk+αdk)Tdk=0。因为dkdk与f(xk)f(xk)在xkxk处的梯度方向夹角大于90度,因此h′(0)≤0h′(0)≤0,如果能找到α^α^使得h′(α^)>0h′(α^)>0,那么必定存在α⋆∈[0,α^)α⋆∈[0,α^)使得h′(α⋆)=0h′(α⋆)=0。有多种迭代算法可以求得α⋆α⋆的近似值,下面选择几种典型的介绍。
Bisection Search
二分线性搜索(Bisection Line Search)[2]可用于求解函数的根,其思想很简单,就是不断将现有区间划分为两半,选择必定含有使h′(α)=0h′(α)=0的半个区间作为下次迭代的区间,直到寻得h′(α⋆)≈0h′(α⋆)≈0为止,算法描述见2。 二分线性搜素可以确保h(α)h(α)是收敛的,只要h(α)h(α)在区间(0,α^)(0,α^)上是连续的且h′(0)h′(0)和h(α^)h(α^)异号。经历nn次迭代后,当前区间[αl,αh][αl,αh]的长度为:
二分线性搜素可以确保h(α)h(α)是收敛的,只要h(α)h(α)在区间(0,α^)(0,α^)上是连续的且h′(0)h′(0)和h(α^)h(α^)异号。经历nn次迭代后,当前区间[αl,αh][αl,αh]的长度为:
由迭代的终止条件之一αh−αl≥ϵαh−αl≥ϵ知迭代次数的上界为:
下面给出二分搜索的Python代码

1 def bisection(dfun,theta,args,d,low,high,maxiter=1e4):
2 """
3 #Functionality:find the root of the function(fun) in the interval [low,high]
4 #@Parameters
5 #dfun:compute the graident of function f(x)
6 #theta:Parameters of the model
7 #args:other variables needed to compute the value of dfun
8 #[low,high]:the interval which contains the root
9 #maxiter:the max number of iterations
10 """
11 eps=1e-6
12 val_low=np.sum(dfun(theta+low*d,args)*d.T)
13 val_high=np.sum(dfun(theta+high*d,args)*d.T)
14 if val_low*val_high>0:
15 raise Exception('Invalid interval!')
16 iter_num=1
17 while iter_num<maxiter:
18 mid=(low+high)/2
19 val_mid=np.sum(dfun(theta+mid*d,args)*d.T)
20 if abs(val_mid)<eps or abs(high-low)<eps:
21 return mid
22 elif val_mid*val_low>0:
23 low=mid
24 else:
25 high=mid
26 iter_num+=1
Backtracking
回溯线性搜索(Backing Line Search)[1]基于Armijo准则计算搜素方向上的最大步长,其基本思想是沿着搜索方向移动一个较大的步长估计值,然后以迭代形式不断缩减步长,直到该步长使得函数值f(xk+αdk)f(xk+αdk)相对与当前函数值f(xk)f(xk)的减小程度大于期望值(满足Armijo准则)为止。Armijo准则(见图3)的数学描述如下:
其中f:Rn→Rf:Rn→R,c1∈(0,1)c1∈(0,1),αα为步长,dk∈Rndk∈Rn为满足f′(xk)Tdk<0f′(xk)Tdk<0的搜索方向。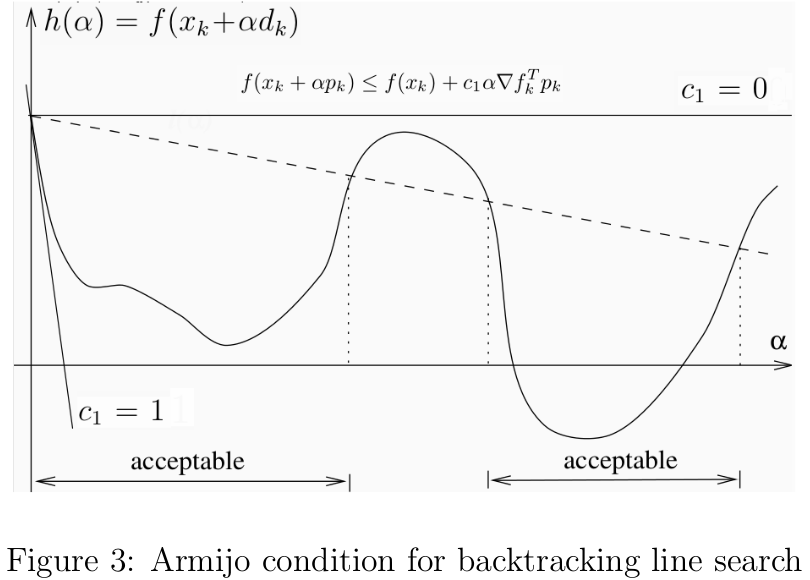 但是仅凭Armijo准则不足以求得较好的步长,根据前面的梯度下降的知识可知,只要αα足够小就能满足Armijo准则。因此常用的策略就是从较大的步长开始,然后以τ∈(0,1)τ∈(0,1)的速度缩短步长,直到满足Armijo准则为止,这样选出来的步长不至于太小,对应的算法描述见3。前面介绍的二分线性搜索的目标是求得满足h′(α)≈0h′(α)≈0的最优步长近似值,而回溯线性搜索放松了对步长的约束,只要步长能使函数值有足够大的变化即可。前者可以少计算几次搜索方向,但在计算最优步长上花费了不少代价;后者退而求其次,找到一个差不多的步长即可,那么代价就是要多计算几次搜索方向。
但是仅凭Armijo准则不足以求得较好的步长,根据前面的梯度下降的知识可知,只要αα足够小就能满足Armijo准则。因此常用的策略就是从较大的步长开始,然后以τ∈(0,1)τ∈(0,1)的速度缩短步长,直到满足Armijo准则为止,这样选出来的步长不至于太小,对应的算法描述见3。前面介绍的二分线性搜索的目标是求得满足h′(α)≈0h′(α)≈0的最优步长近似值,而回溯线性搜索放松了对步长的约束,只要步长能使函数值有足够大的变化即可。前者可以少计算几次搜索方向,但在计算最优步长上花费了不少代价;后者退而求其次,找到一个差不多的步长即可,那么代价就是要多计算几次搜索方向。 接下来,我们要证明回溯线性搜索在Armijo准则下的收敛性问题[6]。因为h′(0)=f′(xk)Tdk<0h′(0)=f′(xk)Tdk<0,且0<c1<10<c1<1,则有
接下来,我们要证明回溯线性搜索在Armijo准则下的收敛性问题[6]。因为h′(0)=f′(xk)Tdk<0h′(0)=f′(xk)Tdk<0,且0<c1<10<c1<1,则有
根据导数的基本定义,结合上式,有如下关系:
因此,存在一个步长α^>0α^>0,对任意的α∈(0,α^)α∈(0,α^),下式均成立
即∀α∈(0,α^),f(xk+αdk)<f(xk)+cαf′(xk)Tdk∀α∈(0,α^),f(xk+αdk)<f(xk)+cαf′(xk)Tdk。 下面给出基于Armijo准则的线性搜索Python代码:
1 def ArmijoBacktrack(fun,dfun,theta,args,d,stepsize=1,tau=0.5,c1=1e-3):
2 """
3 #Functionality:find an acceptable stepsize via backtrack under Armijo rule
4 #@Parameters
5 #fun:compute the value of objective function
6 #dfun:compute the gradient of objective function
7 #theta:a vector of parameters of the model
8 #stepsize:initial step size
9 #c1:sufficient decrease Parameters
10 #tau:rate of shrink of stepsize
11 """
12 slope=np.sum(dfun(theta,args)*d.T)
13 obj_old=costFunction(theta,args)
14 theta_new=theta+stepsize*d
15 obj_new=costFunction(theta_new,args)
16 while obj_new>obj_old+c1*stepsize*slope:
17 stepsize*=tau
18 theta_new=theta+stepsize*d
19 obj_new=costFunction(theta_new,args)
20 return stepsize
Interpolation
基于Armijo准则的回溯线性搜索的收敛速度无法得到保证,特别是要回退很多次后才能落入满足Armijo准则的区间。如果我们根据已有的函数值和导数信息,采用多项式插值法(Interpolation)[12,6,5,9]拟合函数,然后根据该多项式函数估计函数的极值点,这样选择合适步长的效率会高很多。 假设我们只有xkxk处的函数值f(xk)f(xk)及其倒数f′(xk)f′(xk),且第一次尝试的步长为α0α0。如果α0α0不满足条件,那么我们根据这些信息可以构造一个二次近似函数hq(α)hq(α)
注意,该二次函数满足hq(0)=h(0)hq(0)=h(0),h′q(0)=h′(0)hq′(0)=h′(0)和hq(α0)=h(α0)hq(α0)=h(α0),如图4(a)所示。接下来,根据hq(α)hq(α)的最小值估计下一个步长:
如果α1α1仍然不满足条件,我们可以继续重复上述过程,直到得到的步长满足条件为止。假设我们在整个线性搜索过程中都用二次插值函数,那么最好有c1∈(0,0.5]c1∈(0,0.5],为什么呢?简单证明一下:如果α0α0不满足Armijo准则,那么必定存在比α0α0小的步长满足该准则,所以利用二次插值函数估算的步长α1<α0α1<α0才合理。结合α0α0不满足Armijo准则和α1<α0α1<α0,可知c1≤0.5c1≤0.5。 如果我们已经尝试了多个步长,却每次只用上一次步长的相关信息构造二次函数,未免是对计算资源的浪费,其实我们可以利用多个步长的信息构造信息量更大更准确的插值函数的。在计算导数的代价大于计算函数值的代价时,应尽量避免计算h′(α)h′(α),下面给出一个三次插值函数hc(α)hc(α),如图4(b)所示
其中
对hc(α)hc(α)求导,可得极值点αi+1∈[0,αi]αi+1∈[0,αi]的形式如下:
利用以上的三次插值函数求解下一个步长的过程不断重复,直到步长满足条件为止。如果出现a=0a=0的情况,三次插值函数退化为二次插值函数,在实现该算法时需要注意这点。在此过程中,如果αiαi太小或αi−1αi−1与αiαi太接近,需要重置αi=αi−1/2αi=αi−1/2,该保护措施(safeguards)保证下一次的步长不至于太小[6,5]。为什么会有这个作用呢?1)因为αi+1∈[0,αi]αi+1∈[0,αi],所以当αiαi很小时αi+1αi+1也很小;2)当αi−1αi−1与αiαi太靠近时有a≈b≈∞a≈b≈∞,根据αi+1αi+1的表达式可知αi+1≈0αi+1≈0。 但是,在很多情况下,计算函数值后只需付出较小的代价就能顺带计算出导数值或其近似值,这使得我们可以用更精确的三次Hermite多项式[6]进行插值,如图4(c)所示
其中,三次Hermite多项式满足H3(αi−1)=h(αi−1)H3(αi−1)=h(αi−1),H3(αi)=h(αi)H3(αi)=h(αi),H′3(αi−1)=h′(αi−1)H3′(αi−1)=h′(αi−1)和H′3(αi)=h′(αi)H3′(αi)=h′(αi)。H(α)H(α)的最小值只可能在两侧的端点或者极值点处,令H′3(α)=0H3′(α)=0可得下一个步长:
其中
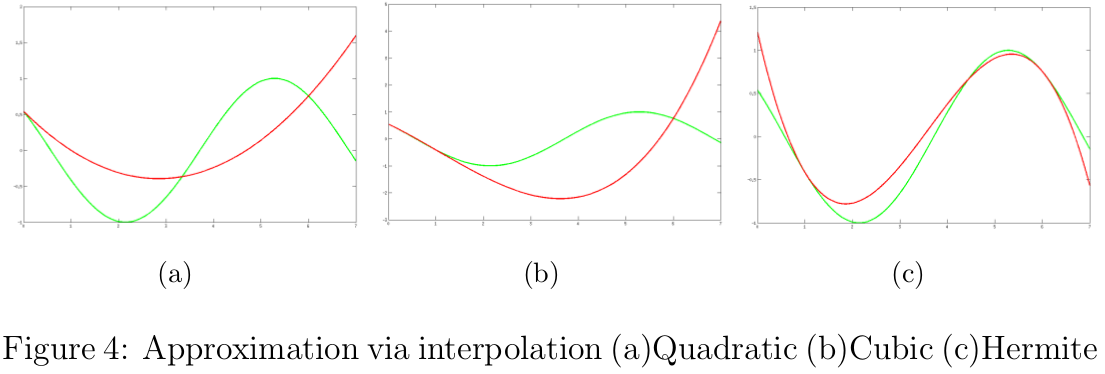 下面给出二次插值及三次插值的Python代码:
下面给出二次插值及三次插值的Python代码:
1 def quadraticInterpolation(a,h,h0,g0):
2 """
3 #Functionality:Approximate h(a) with a quadratic function and return its stationary point
4 #@Parameters
5 #a:current stepsize
6 #h:a function value about stepsize,h(a)=f(x_k+a*d)
7 #h:h(0)=f(x_k)
8 #g0:h'(0)=f'(0)
9 """
10 numerator=g0*a**2
11 denominator=2*(g0*a+h0-h)
12 if abs(denominator)<1e-12:#indicates that a is almost 0
13 return a
14 return numerator/denominator
def cubicInterpolation(a0,h0,a1,h1,h,g):
"""
#Functionality:Approximate h(x) with a cubic function and return its stationary point
#This version of cubic interpolation computes h'(x) as few as possible,suitable for the case in which computing derivative is more expensive than computing function values
#@Parameters
#a0 and a1 are stepsize it previous two iterations
#h0:h(a0)
#h1:h(a1)
#h:h(0)=f(x)
#g:h'(0)
"""
mat=matlib.matrix([[a0**2,-a1**2],[-a0**3,a1**3]])
vec=matlib.matrix([[h1-h-g*a1],[h0-h-g*a0]])
ab=mat*vec/(a0**2*a1**2*(a1-a0))
a=ab[0,0]
b=ab[1,0]
if abs(a)<1e-12:#a=0 and cubic function is a quadratic one
return -g/(2*b)
return (-b+np.sqrt(b**2-3*a*g))/(3*a)
def cubicInterpolationHermite(a0,h0,g0,a1,h1,g1):
"""
#Functionality:Approximate h(a) with a cubic Hermite polynomial function and return its stationary point
#This version of cubic interpolation computes h(a) as few as possible,suitable for the case in which computing derivative is easier than computing function values
#@Parameters
#a0 and a1 are stepsize it previous two iterations
#h0:h(a0)
#g0:h'(a0)
#h1:h(a1)
#g1:h'(a1)
"""
d1=g0+g1-3*(h1-h0)/(a1-a0)
d2=np.sign(a1-a0)*np.sqrt(d1**2-g0*g1)
res=a1-(a1-a0)*(g1+d2-d2)/(g1-g0+2*d2)
return res
基于Armijo准则的线性搜索的算法描述如下[4] 对应的Armijo线性搜索的Python代码如下:
对应的Armijo线性搜索的Python代码如下:
1 def ArmijoLineSearch(fun,dfun,theta,args,d,a0=1,c1=1e-3,a_min=1e-7,max_iter=1e5):
2 """
3 #Functionality:Line search under Armijo condition with quadratic and cubic interpolation
4 #@Parameters
5 #fun:objective Function
6 #dfun:compute the gradient of fun
7 #theta:a vector of parameters of the model
8 #args:other variables needed for fun and func
9 #d:search direction
10 #a0:initial stepsize
11 #c1:constant used in Armijo condition
12 #a_min:minimun of stepsize
13 #max_iter:maximum of the number of iterations
14 """
15 eps=1e-6
16 c1=min(c1,0.5)#c1 should<=0.5
17 a_pre=h_pre=g_pre=0
18 a_cur=a0
19 f_val=fun(theta,args) #h(0)=f(0)
20 g_val=np.sum(dfun(theta,args)*d.T) #h'(0)=f'(x)^Td
21 h_cur=g_cur=0
22 k=0
23 while a_cur>a_min and k<max_iter:
24 h_cur=fun(theta+a_cur*d,args)
25 g_cur=np.sum(dfun(theta+a_cur*d,args)*d.T)
26 if h_cur<=f_val+c1*a_cur*g_val: #meet Armijo condition
27 return a_cur
28 if not k: #k=0,use quadratic interpolation
29 a_new=quadraticInterpolation(a_cur,h_cur,f_val,g_val)
30 else: #k>0,use cubic Hermite interpolation
31 a_new=cubicInterpolationHermite(a_pre,h_pre,g_pre,a_cur,h_cur,g_cur)
32 if abs(a_new-a_cur)<eps or abs(a_new)<eps: #safeguard procedure
33 a_new=a_cur/2
34 a_pre=a_cur
35 a_cur=a_new
36 h_pre=h_cur
37 g_pre=g_cur
38 k+=1
39 return a_min #failed search
Wolfe Search
前面说到单凭Armijo准则(不考虑回溯策略)选出的步长可能太小,为了排除这些微小的步长,我们加上曲率的约束条件(如图5所示)
其中c2∈(c1,1)c2∈(c1,1),c1c1为Armijo准则中的常量。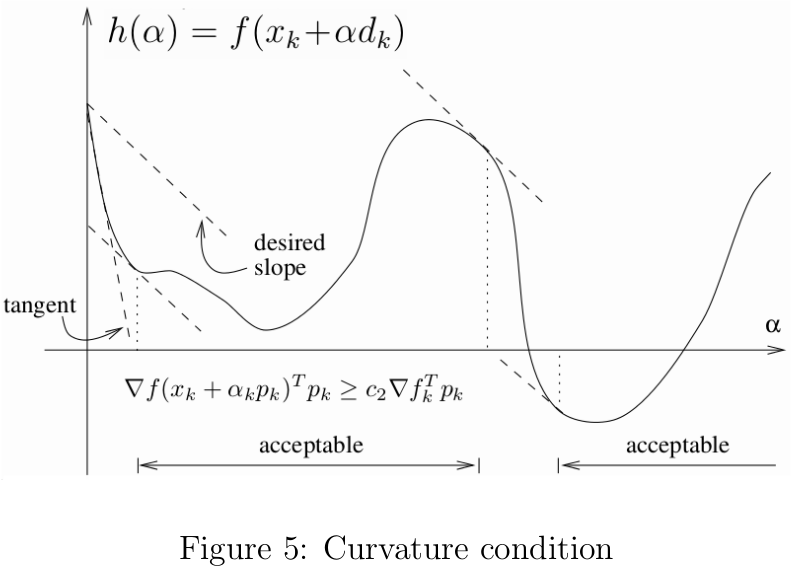 当h′(α)h′(α)为很小的负数甚至为正数时,说明从xkxk沿着dkdk移动αα后的函数梯度方向与搜索方向的夹角接近90度,继续向前移动已经不能很明显减小函数值了,此时可以停止沿着dkdk继续搜索;反之,说明继续减小函数值的空间还是很大的,可以继续向前搜索。Armijo准则与曲率约束两者合起来称为Wolfe准则[5]:
当h′(α)h′(α)为很小的负数甚至为正数时,说明从xkxk沿着dkdk移动αα后的函数梯度方向与搜索方向的夹角接近90度,继续向前移动已经不能很明显减小函数值了,此时可以停止沿着dkdk继续搜索;反之,说明继续减小函数值的空间还是很大的,可以继续向前搜索。Armijo准则与曲率约束两者合起来称为Wolfe准则[5]:
其中0<c1<c2<10<c1<c2<1。如图6所示,满足Wolfe准则的步长也许离h(α)h(α)的极值点较远。我们可以修改曲率约束条件使得步长落到h(α)h(α)的极值点的一个较宽的领域中,强Wolfe准则对步长αα的约束如下:
强Wolfe准则不允许h′(α)h′(α)为太大的正数,可以排除远离极值点的区间。 那么到底是否存在满足强Wolfe准则的步长呢?假设h(α)=f(xk+αdk)h(α)=f(xk+αdk)连续可微,在整个α>0α>0的定义域上存在下界。因为0<c1<10<c1<1,所以l(α)=f(xk)+αc1f′(xk)Tdkl(α)=f(xk)+αc1f′(xk)Tdk必然与h(α)h(α)至少有一个交点。假设α′α′为最小的交点对应的步长,则有
那么到底是否存在满足强Wolfe准则的步长呢?假设h(α)=f(xk+αdk)h(α)=f(xk+αdk)连续可微,在整个α>0α>0的定义域上存在下界。因为0<c1<10<c1<1,所以l(α)=f(xk)+αc1f′(xk)Tdkl(α)=f(xk)+αc1f′(xk)Tdk必然与h(α)h(α)至少有一个交点。假设α′α′为最小的交点对应的步长,则有
那么对于满足α∈(0,α′)α∈(0,α′)的步长必然都满足Armijo准则。根据零值定理,存在α′′∈(0,α′)α″∈(0,α′)满足
结合上面两个关系式,由0<c1<c20<c1<c2和f′(xk)Tdk<0f′(xk)Tdk<0,可得
由此可知,α′′α″满足强Wolfe准则。如果h(α)h(α)是一个较为平滑的函数,那么包含α′′α″的较小领域都会满足强Wolfe准则。 如果在线性搜索过程中利用强Wolfe准则,可以更精确得找到更靠近极值点的步长,在目前线性搜索中用得很多。基于强Wolfe准则的线性搜索包含两个阶段:第一个阶段从初始步长开始,不断增大步长,直到找到一个满足强Wolfe准则的步长或包含该步长的区间为止;第二个阶段是在已知包含满足强Wolfe准则步长区间的基础上,不断缩减区间,直到找到满足强Wolfe准则的步长为止。基于强Wolfe准则的线性搜索算法描述如下5
在算法5中,αnewαnew的更新是因为在区间(αpre,αcur)(αpre,αcur)内没有满足Wolfe准则的步长,所以要选取一个大于αcurαcur的步长αnewαnew。在算法中,我们是用二次插值函数计算αnewαnew的,所以要求0<c1<0.50<c1<0.5。当然,也可以用其他方法,比如让αcurαcur乘以一个大于1的常数,只要能较快找到一个包含满足Wolfe的区间即可。所以,该算法每次尝试的步长αcurαcur的逐渐递增的;一旦找到了包含满足Wolfe准则的步长的区间,立即调用zoomzoom函数不断缩短区间,并返回满足Wolfe的步长。根据算法逻辑,我们可以推断出αpreαpre满足Armijo准则,但违背曲率约束,而且导数为负数。由上述三个条件,可知αpreαpre必定位于满足Wolfe准则的区间的左侧的呈下降趋势的曲线上,只要αcurαcur位于该区间的右侧即可。那么怎样判断区间(αpre,αcur)(αpre,αcur)是否包含满足Wolfe准则的步长呢?下面给出三种αcurαcur位于该区间的右侧的充分条件:
- αcurαcur不满足Armijo准则;
- h(αcur)≥h(αpre)h(αcur)≥h(αpre);
- h′(αcur)≥0h′(αcur)≥0
这一点结合图7就很容易理解了,我在图中分别用红色和绿色点标注了αpreαpre和αcurαcur可能的位置,蓝色带数字的圆圈注明了αcurαcur满足哪些条件。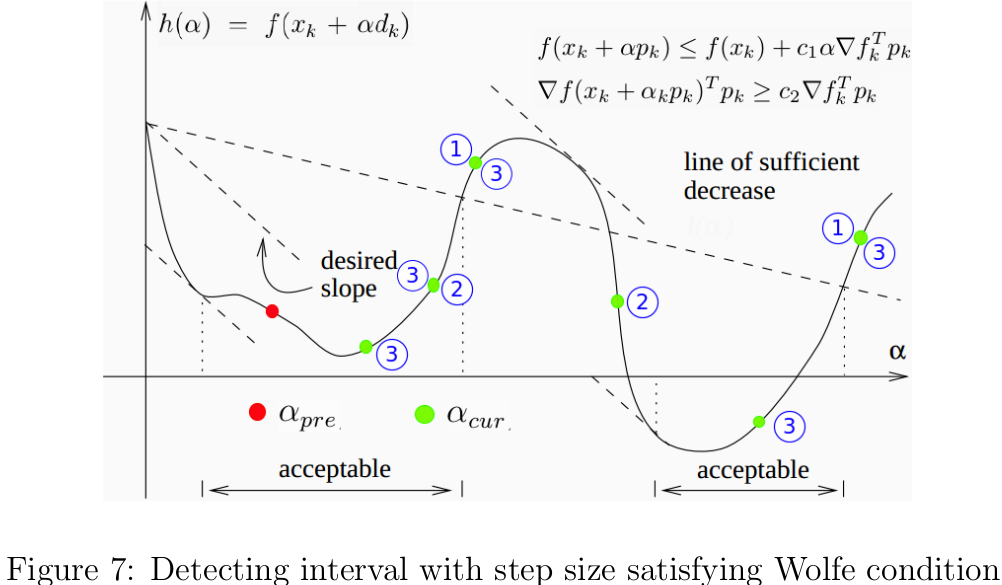 基于Wolfe准则的线性搜索Python代码如下:
基于Wolfe准则的线性搜索Python代码如下:
1 def WolfeLineSearch(fun,dfun,theta,args,d,a0=1,c1=1e-4,c2=0.9,a_min=1e-7,max_iter=1e5):
2 """
3 #Functionality:find a stepsize meeting Wolfe condition
4 #@Parameters
5 #fun:objective Function
6 #dfun:compute the gradient of fun
7 #theta:a vector of parameters of the model
8 #args:other variables needed for fun and func
9 #d:search direction
10 #a0:intial stepsize
11 #c1:constant used in Armijo condition
12 #c2:constant used in curvature condition
13 #a_min:minimun of stepsize
14 #max_iter:maximum of the number of iterations
15 """
16 eps=1e-16
17 c1=min(c1,0.5)
18 a_pre=0
19 a_cur=a0
20 f_val=fun(theta,args) #h(0)=f(x)
21 g_val=np.sum(dfun(theta,args)*d.T)
22 h_pre=f_val #h'(0)=f'(x)^Td
23 k=0
24 while k<max_iter and abs(a_cur-a_pre)>=eps:
25 h_cur=fun(theta+a_cur*d,args) #f(x+ad)
26 if h_cur>f_val+c1*a_cur*g_val or h_cur>=h_pre and k>0:
27 return zoom(fun,dfun,theta,args,d,a_pre,a_cur,c1,c2)
28 g_cur=np.sum(dfun(theta+a_cur*d,args)*d.T)
29 if abs(g_cur)<=-c2*g_val:#satisfy Wolfe condition
30 return a_cur
31 if g_cur>=0:
32 return zoom(fun,dfun,theta,args,d,a_pre,a_cur,c1,c2)
33 a_new=quadraticInterpolation(a_cur,h_cur,f_val,g_val)
34 a_pre=a_cur
35 a_cur=a_new
36 h_pre=h_cur
37 k+=1
38 return a_min
zoom函数的算法描述见6。zoom函数中需要传入搜寻区间[αlow,αhigh][αlow,αhigh],其中αlow<αhighαlow<αhigh。本文中的zoom函数与文献[5]中的内容略有差异,但是本文的zoom函数思路更简单和清晰。由算法5中分析得到的调用zoom函数的条件,知道αlowαlow必须满足Armijo准则,且位于所有满足Wolfe准则的步长的左侧。我们先取[αlow,αhigh][αlow,αhigh]区间的中值作为下一个测试的步长αnewαnew,如果恰好满足Wolfe准则,则直接返回。如果αnewαnew违反Armijo准则或大于h(αlow)h(αlow),显然区间[αlow,αnew][αlow,αnew]包含满足Wolfe准则的步长,因此用αnewαnew替换αhighαhigh以缩短区间长度;否则,αnewαnew必然也满足Armijo准则,如果h′(αnew)>0h′(αnew)>0,则αnewαnew与αhighαhigh都在满足Wolfe准则的区间右侧,用αnewαnew替代αhighαhigh,反之则用αnewαnew替代αlowαlow。上述的迭代过程不断缩短步长,知道求得满足Wolfe准则的步长为止。如果在有限迭代次数内搜索失败,则返回必然满足Armijo准则的步长αlowαlow。

zoom函数对应的Python代码如下:
1 def zoom(fun,dfun,theta,args,d,a_low,a_high,c1=1e-3,c2=0.9,max_iter=1e4):
2 """
3 #Functionality:enlarge the interval to find a stepsize meeting Wolfe condition
4 #@Parameters
5 #fun:objective Function
6 #dfun:compute the gradient of fun
7 #theta:a vector of parameters of the model
8 #args:other variables needed for fun and func
9 #d:search direction
10 #[a_low,a_high]:interval containing a stepsize satisfying Wolfe condition
11 #c1:constant used in Armijo condition
12 #c2:constant used in curvature condition
13 #max_iter:maximum of the number of iterations
14 """
15 if a_low>a_high:
16 print('low:%f,high:%f'%(a_low,a_high))
17 raise Exception('Invalid interval of stepsize in zoom procedure')
18 eps=1e-16
19 h=fun(theta,args) #h(0)=f(x)
20 g=np.sum(dfun(theta,args)*d.T) #h'(0)=f'(x)^Td
21 k=0
22 h_low=fun(theta+a_low*d,args)
23 h_high=fun(theta+a_high*d,args)
24 if h_low>h+c1*a_low*g:
25 raise Exception('Left endpoint violates Armijo condition in zoom procedure')
26 while k<max_iter and abs(a_high-a_low)>=eps:
27 a_new=(a_low+a_high)/2
28 h_new=fun(theta+a_new*d,args)
29 if h_new>h+c1*a_new*g or h_new>h_low:
30 a_high=a_new
31 h_high=h_new
32 else:
33 g_new=np.sum(dfun(theta+a_new*d,args)*d.T)
34 if abs(g_new)<=-c2*g: #satisfy Wolfe condition
35 return a_new
36 if g_new*(a_high-a_low)>=0:
37 a_high=a_new
38 h_high=h_new
39 else:
40 a_low=a_new
41 h_low=h_new
42 k+=1
43 return a_low #a_low definitely satisfy Armijo condition
Newton's Method
牛顿法(Newton's method)[8]以迭代方式求解函数的根,其基本思想是从一个初始点出发,不断在当前点xkxk处用切线近似函数f(x)f(x),并求得该切线与xx轴的交点作为下一次的迭代初始点xk+1xk+1,直到找到f(x)=0f(x)=0的近似解为止。Newton法可用于二次可微函数f(x)f(x)的最优化问题。 在xkxk处用二阶泰勒展开来对f(xk)f(xk)其进行逼近。
现在,我们的目标是在xkxk附近求得使f(x)f(x)取得极小值的△x△x。将上式对△x△x求导可得函数f′(x)f′(x)在xk+1=xk+△xxk+1=xk+△x处的线性近似如下:
其中Bk=∇2f(xk)Bk=∇2f(xk)为f(x)f(x)在xkxk处对应的Hessian矩阵。由于函数的极值点一般都对应f′(x)=0f′(x)=0,令f′(xk+1)=0f′(xk+1)=0并化简可得迭代公式为:
牛顿迭代法收敛速度很快,对于二次函数可以一次性找到最优解。但用于求解优化问题时,需要付出很大的代价求得函数的一阶导数、二阶导数及其逆矩阵。此外,有的函数还存在不可导、Hessian矩阵不可逆、迭代点之间存在循环(即xk+t=xkxk+t=xk)等情形,这些都成为了牛顿法的应用障碍。牛顿迭代法用于求解极值点f′(x)=0f′(x)=0的步骤见算法7。当然,也可用牛顿法求最优步长,只需将算法7中的函数f(x)f(x)替换为关于步长的函数h(α)h(α)即可。
Quasi-Newton Method
拟牛顿(Quasi-Newton)[11]算法可用于求解函数的局部最优解,也就是那些导数为0的驻点。牛顿法用于解决优化问题时,事先假设原函数可用二次函数近似,然后用一阶和二阶导数寻找局部最优解。而在拟牛顿算法中,不需要准确计算Hessian矩阵,取而代之的是运用下面的拟牛顿条件分析连续两个梯度向量得到的近似值矩阵BkBk:
拟牛顿算法的算法流程见8,其基本思想是利用矩阵BkBk计算牛顿方向的近似值dkdk。各种拟牛顿算法的主要差异在于近似Hessian矩阵的更新策略,表1列出了部分主流的拟牛顿算法的迭代更新规则,其中sk=xk+1−xk=−αkB−1kf′(xk)sk=xk+1−xk=−αkBk−1f′(xk),yk=f′(xk+1)−f′(xk)yk=f′(xk+1)−f′(xk)。
 拟牛顿算法中最常用的是BFGS,其针对有限内存的机器的算法变种L-BFGS[4]在机器学习领域又备受青睐。BFGS需要存储n×nn×n的矩阵HkHk用于近似Hessian矩阵的逆矩阵;而L-BFGS仅需要存储过去mm(mm一般小于10)对nn维的更新数据(x,f′(xi))(x,f′(xi))即可。L-BFGS的空间复杂度为线性,特别适用于变量非常多的优化问题。BFGS的算法描述很容易写出来,如下:
拟牛顿算法中最常用的是BFGS,其针对有限内存的机器的算法变种L-BFGS[4]在机器学习领域又备受青睐。BFGS需要存储n×nn×n的矩阵HkHk用于近似Hessian矩阵的逆矩阵;而L-BFGS仅需要存储过去mm(mm一般小于10)对nn维的更新数据(x,f′(xi))(x,f′(xi))即可。L-BFGS的空间复杂度为线性,特别适用于变量非常多的优化问题。BFGS的算法描述很容易写出来,如下:
1 def BFGS(fun,dfun,theta,args,H=None,mode=0,eps=1e-12,max_iter=1e4):
2 """
3 #Functionality:find the minimum of objective function f(x)
4 #@Parameters
5 #fun:objective function f(x)
6 #dfun:compute the gradient of f(x)
7 #args:parameters needed by fun and dfun
8 #theta:start vector of parameters of the model
9 #H:initial inverse Hessian approximation
10 #mode:index of line search algorithm
11 """
12 x_pre=x_cur=theta
13 g=dfun(x_cur,args)
14 I=matlib.eye(theta.size)
15 if not H:#initialize H as an identity matrix
16 H=I
17 k=0
18 while k<max_iter and np.sum(np.abs(g))>eps:
19 d=-g*H
20 step=LineSearch(fun,dfun,x_pre,args,d,1,mode)
21 x_cur=x_pre+step*d
22 s=step*d
23 y=dfun(x_cur,args)-dfun(x_pre,args)
24 ys=np.sum(y*s.T)
25 if abs(ys)<eps:
26 return x_cur
27 change=(ys+np.sum(y*H*y.T))*(s.T*s)/(ys**2)-(H*y.T*s+s.T*y*H)/ys
28 H+=change
29 g=dfun(x_cur,args)
30 x_pre=x_cur
31 k+=1
32 return x_cur
下面我们分析如何构造下L-BFGS的算法[10,13]。假设我们现在处于优化过程的第k(k≥m)k(k≥m)次迭代,参数为xkxk,梯度gk=f′(xk)gk=f′(xk),已经保存的mm条更新数据为sk=xk+1−xksk=xk+1−xk及yk=gk+1−gkyk=gk+1−gk。我们最终需要计算的是搜索方向dk=−Hkgkdk=−Hkgk,于是令Vk=(I−ρkyksTk)Vk=(I−ρkykskT),ρk=1/(yTksk)ρk=1/(ykTsk),将表1中BFGS的HkHk的更新规则展开,我们可以得到下式:
上式非常有规律,这就为迭代求解奠定了很好的基础。我们令q0=gkq0=gk,则当1≤i≤m1≤i≤m时有
那么可以得到如下的迭代规则:
到目前为止,我们已经可以求解出HkgkHkgk所有项的右半部分,那左半部分如何处理?在这里采用不断提前最左端的公因式的方法完成迭代过程:
重复该过程,很快就可以发现规律:
其中Pm+1=Hk−mqmPm+1=Hk−mqm。 根据上述分析,我们可以得到L-BFGS的求解搜索方向的算法9。根据算法9的整个流程,可知通过两个循环mm次的迭代运算即可出计算当前的搜索方向,需要存储历史数据{sk−i,yk−i|i=1,⋯,m}{sk−i,yk−i|i=1,⋯,m}和临时数据{ak−i|i=1,⋯,m}{ak−i|i=1,⋯,m},所以算法的时间和空间复杂度均为O(mn)O(mn)。如果目前处于迭代的初期,已有的历史数据少于mm,那么就用这些已有的数据,在后续迭代过程中不断新增历史数据即可;若干当前的迭代次数不小于mm,那么在每次计算出搜索方向后,即可用sksk和ykyk替换sk−msk−m和yk−myk−m组成新的mm对历史更新数据。
在算法9中,需要给出矩阵Hk−mHk−m。在第一次迭代时,Hk−mHk−m被初始化为单位阵,在随后的迭代过程中Hk−m=γkIHk−m=γkI,其中
另外,在内存受限的系统中存储n×nn×n不是很现实的想法。用上述的方法,我们仅需存储一个标量γkγk即可,这是一个简单却又高效的做法[13]。 最后,附上L-BFGS的Python版本代码:
1 def LBFGS(fun,dfun,theta,args,mode=0,eps=1e-12,max_iter=1e4):
2 """
3 #Functionality:find the minimum of objective function f(x) with LBFGS
4 #@Parameters
5 #fun:objective function f(x)
6 #dfun:compute the gradient of f(x)
7 #args:parameters needed by fun and dfun
8 #theta:start vector of parameters of the model
9 #H:initial inverse Hessian approximation
10 #mode:index of line search algorithm
11 """
12 x_pre=x_cur=theta
13 s_arr=[]
14 y_arr=[]
15 Hscale=1
16 k=0
17 while k<max_iter:
18 g=dfun(x_cur,args)
19 d=LBFGSSearchDirection(y_arr,s_arr,Hscale,-g)
20 step=LineSearch(fun,dfun,x_pre,args,d,1,mode)
21 s=step*d
22 x_cur=x_pre+s
23 y=dfun(x_cur,args)-dfun(x_pre,args)
24 ys=np.sum(y*s.T)
25 if np.sum(np.abs(s))<eps:
26 return x_cur
27 x_pre=x_cur
28 k+=1
29 y_arr,s_arr,Hscale=LBFGSUpdate(y,s,y_arr,s_arr)
30 return x_cur
31
32
33 def LBFGSSearchDirection(y_arr,s_arr,Hscale,g):
34 """
35 #Functionality:estimate search direction using with LBFGS
36 #@Parameters
37 #y_arr:m*dim matrix,where y_arr[i,:]=f'(x_{i+1})-f'(x_i)
38 #s_arr:m*dim matrix,where s_arr[i,:]=x_{k+1}-x_k
39 #Hscale:a scale to initilize the inverse of Hessian matrix
40 #g:a row vector representing -f'(x_{k})
41 """
42 histNum=len(s_arr)#number of update data stored
43 if not histNum:
44 return g
45 dim=s_arr[0].size
46 a_arr=[0 for i in range(histNum)]
47 rho=[0 for i in range(histNum)]
48 q=g
49 for i in range(1,histNum+1):
50 s=s_arr[histNum-i]
51 y=y_arr[histNum-i]
52 rho[histNum-i]=1/np.sum(s*y.T)
53 a_arr[i-1]=rho[histNum-i]*np.sum(s*q.T)
54 q-=(a_arr[i-1]*y)
55 P=Hscale*q
56 for i in range(histNum,0,-1):
57 y=y_arr[histNum-i]
58 s=s_arr[histNum-i]
59 beta=rho[histNum-i]*np.sum(y*P.T)
60 P+=s*(a_arr[i-1]-beta)
61 return P
62
63
64 def LBFGSUpdate(y,s,oldy,olds,m=1e2):
65 """
66 #Functionality:refresh the historical update data
67 #@Parameters
68 #y:f'(x_{k+1})-f'(x_k)
69 #s:x_{k+1}-x_k
70 #oldy:[y0,y1,...],which is a list
71 #olds:[s0,s1,...],which is a list
72 #m:number of historical data to store(default:100)
73 """
74 eps=1e-12
75 Hscale=np.sum(y*s.T/y*y.T) #a scale to initialize H_{k-m}
76 if Hscale<eps:#skip update
77 return oldy,olds,Hscale
78
79 cur_m=len(oldy)
80 if cur_m>=m:
81 oldy.pop(0)
82 olds.pop(0)
83 oldy.append(copy.deepcopy(y))
84 olds.append(copy.deepcopy(s))
85 return oldy,olds,Hscale
References
[1] Backtracking line search. http://en.wikipedia.org/wiki/Backtracking_line_search.
[2] Bisection method. http://en.wikipedia.org/wiki/Bisection_method.
[3] Gradient descent. http://en.wikipedia.org/wiki/Gradient_descent.
[4] Limited-memory bfgs. http://en.wikipedia.org/wiki/Limited-memory_BFGS.
[5] Line search methods. http://pages.cs.wisc.edu/~ferris/cs730/chap3.pdf.
[6] Line search methods:step length selection. http://terminus.sdsu.edu/SDSU/Math693a_f2013/Lectures/06/lecture.pdf.
[7] Math 408a line search methods. https://www.math.washington.edu/~burke/crs/408/lectures/L7-line-search.pdf.
[8] Newton’s method. http://en.wikipedia.org/wiki/Newton%27s_method.
[9] Nonlinear programming algorithms. http://www.math.bme.hu/~bog/GlobOpt/Chapter5.pdf.
[10] Oerview of quasi-newton optimization methods. https://homes.cs.washington.edu/~galen/files/quasi-newton-notes.pdf.
[11] Quasi-newton method. http://en.wikipedia.org/wiki/Quasi-Newton_method.
[12] Unconstrained minimization. http://www.ing.unitn.it/~bertolaz/2-teaching/2011-2012/AA-2011-2012-OPTIM/lezioni/slides-mND.pdf.
[13] Dong C Liu and Jorge Nocedal. On the limited memory bfgs method for large scale optimization. Mathematical programming, 45(1-3):503–528,1989.
Line Search and Quasi-Newton Methods 线性搜索与拟牛顿法的更多相关文章
- Line Search and Quasi-Newton Methods
Gradient Descent 机器学习中很多模型的参数估计都要用到优化算法,梯度下降是其中最简单也用得最多的优化算法之一.梯度下降(Gradient Descent)[3]也被称之为最快梯度(St ...
- 线搜索(line search)方法
在机器学习中, 通常需要求某个函数的最值(比如最大似然中需要求的似然的最大值). 线搜索(line search)是求得一个函数\(f(x)\)的最值的两种常用迭代方法之一(另外一个是trust re ...
- Backtracking line search的理解
使用梯度下降方法求解凸优化问题的时候,会遇到一个问题,选择什么样的梯度下降步长才合适. 假设优化函数为,若每次梯度下降的步长都固定,则可能出现左图所示的情况,无法收敛.若每次步长都很小,则下降速度非常 ...
- 重新发现梯度下降法--backtracking line search
一直以为梯度下降很简单的,结果最近发现我写的一个梯度下降特别慢,后来终于找到原因:step size的选择很关键,有一种叫backtracking line search的梯度下降法就非常高效,该算法 ...
- 【原创】回溯线搜索 Backtracking line search
机器学习中很多数值优化算法都会用到线搜索(line search).线搜索的目的是在搜索方向上找到是目标函数\(f(x)\)最小的点.然而,精确找到最小点比较耗时,由于搜索方向本来就是近似,所以用较小 ...
- line search中的重要定理 - 梯度与方向的点积为零
转载请注明出处:http://www.codelast.com/ 对精确的line search(线搜索),有一个重要的定理: ∇f(xk+αkdk)Tdk=0 这个定理表明,当前点在dk方向上移动到 ...
- jrae源码解析(一)
jare用java实现了论文<Semi-Supervised Recursive Autoencoders for Predicting Sentiment Distributions>中 ...
- minimize.m:共轭梯度法更新BP算法权值
minimize.m:共轭梯度法更新BP算法权值 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ Carl Edward Rasmussen在高斯机器学 ...
- Newton方法
Newton方法主要解决无等式约束和等式约束的最优化方法. 1.函数进行二阶泰勒展开近似 Taylor近似函数求导等于0进而得到Newton步径.(搜索方向) 2.Newton减量(停止条件) 当1/ ...
随机推荐
- My97DatePicker控制开始时间和结束时间区间
开始时间: <input type="text" placeholder=" -请选择- " id="kssj" name=" ...
- char,wchar_t,WCHAR,TCHAR,ACHAR的区别----LPCTSTR
转自http://blog.chinaunix.net/uid-7608308-id-2048125.html 简介:这是DWORD及LPCTSTR类型的了解的详细页面,介绍了和类,有关的知识,加入收 ...
- android 后台代码设置动画
1.设置旋转动画 final RotateAnimation animation =new RotateAnimation(0f,360f,Animation.RELATIVE_TO_SELF, 0. ...
- 7、android的button如何平铺一张图片?
我想要实现的效果:,但是设计师给的是这样的:. 首先我想到的是这就像windows电脑设置壁纸有什么拉伸.自适应.平铺等类型,这个应该就是传说中的平铺吧. 那么我们知道,一个普通的button,设置他 ...
- HashMap优雅的初始化方式以及引申
小记 相信很多人和笔者一样,经常会做一些数组的初始化工作,也肯定会经常用到集合类.假如我现在要初始化一个String类型的数组,可以很方便的使用如下代码: String [] strs = {&quo ...
- loadrunner-增加检查点(web_reg_find)
接口性能测试地址: http://192.168.x.x:x/tionWeb/Ajax_GetStock.aspx?stockcode=600571 性能测试脚本: Action() { lr_sta ...
- MySQL用程序代码建表(1)
一.创建表格代码格式 create table <表名>( <列名> <数据类型及长度> [not null], <列名> <数据类型及长度> ...
- Matlab设置网格线密度(坐标精度)
1.不精确 set(gca,'XMinorTick','on') 这样的话知识x轴显示了细的密度,网格线并没有变. 2.精确 set(gca,'xtick',-1:0.1:1); set(gca,'y ...
- Basic knowledge of javaScript (keep for myself)
1. 函数表达式 JavaScript 函数可以通过一个表达式定义.eg. var x = function (a, b) {return a * b}; so: var x = function ( ...
- iOS开发之runtime的运用-获取当前网络状态
之前写过runtime的一些东西,这次通过runtime获取一些苹果官方不想让你拿到的东西,比如,状态栏内部的控件属性.本文将通过runtime带你一步步拿到状态栏中显示网络状态的控件,然后通过监测该 ...