Spark-SQL连接Hive
第一步:修个Hive的配置文件hive-site.xml
添加如下属性,取消本地元数据服务:
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
修改Hive元数据服务地址和端口:
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.10.10:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
然后把配置文件hive-site.xml拷贝到Spark的conf目录下
第二步:对于Hive元数据库使用Mysql的把mysql-connector-java-5.1.41-bin.jar拷贝到Spark的jar目录下
到这里已经能够在Scala终端下查询Hive数据库了
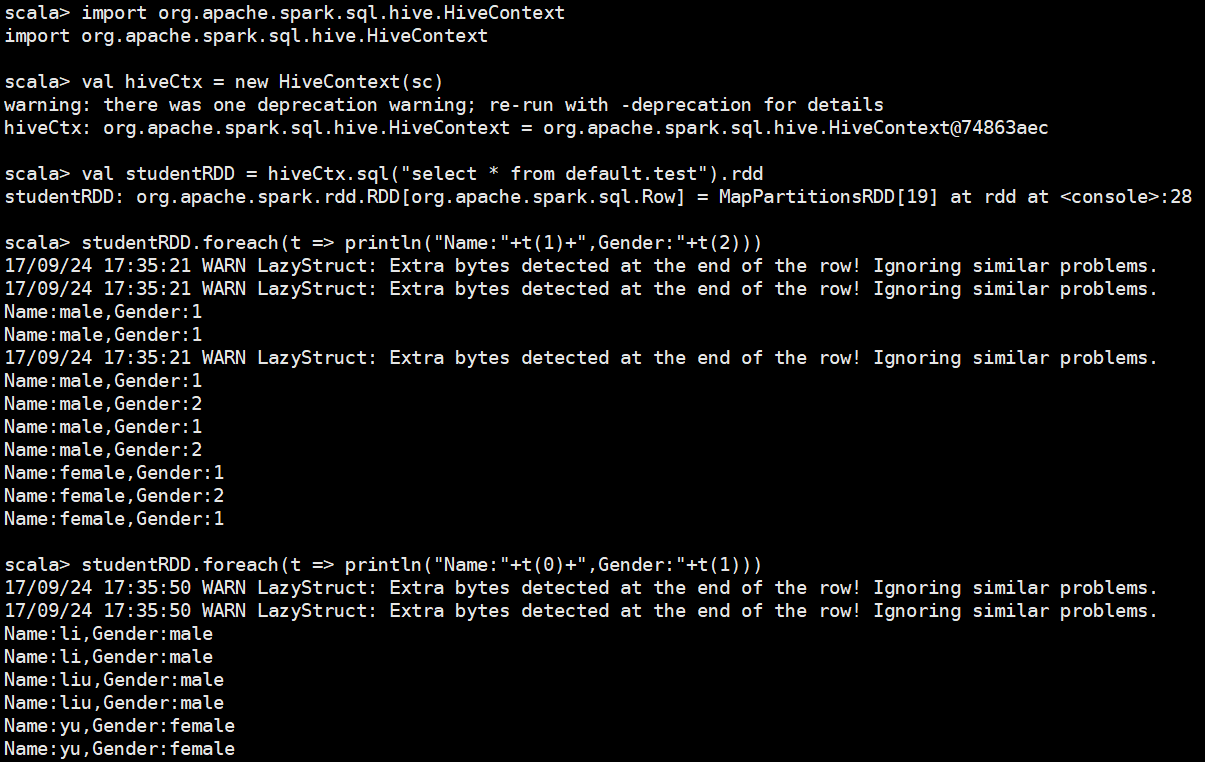
但是某人一开始的要求是用Spark-SQL查询Hive呀
于是启动Spark-SQL,启了一天了都是报下面的错误
Exception in thread "main" java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.<init>(RetryingMetaStoreClient.java:)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:)
at org.apache.hadoop.hive.ql.metadata.Hive.createMetaStoreClient(Hive.java:)
at org.apache.hadoop.hive.ql.metadata.Hive.getMSC(Hive.java:)
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:)
... more
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:)
at java.lang.reflect.Constructor.newInstance(Constructor.java:)
at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:)
... more
Caused by: MetaException(message:Version information not found in metastore. )
at org.apache.hadoop.hive.metastore.ObjectStore.checkSchema(ObjectStore.java:)
at org.apache.hadoop.hive.metastore.ObjectStore.verifySchema(ObjectStore.java:)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.hadoop.hive.metastore.RawStoreProxy.invoke(RawStoreProxy.java:)
at com.sun.proxy.$Proxy6.verifySchema(Unknown Source)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.getMS(HiveMetaStore.java:)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.createDefaultDB(HiveMetaStore.java:)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.init(HiveMetaStore.java:)
at org.apache.hadoop.hive.metastore.RetryingHMSHandler.<init>(RetryingHMSHandler.java:)
at org.apache.hadoop.hive.metastore.RetryingHMSHandler.getProxy(RetryingHMSHandler.java:)
at org.apache.hadoop.hive.metastore.HiveMetaStore.newRetryingHMSHandler(HiveMetaStore.java:)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.<init>(HiveMetaStoreClient.java:)
at org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient.<init>(SessionHiveMetaStoreClient.java:)
... more
一开始我查这个bug都是用第一行的报错信息查,都没成功,后面搜了下最后一个报错信息
message:Version information not found in metastore
终于找到问题解决方法了,把hive-site.xml中的hive.metastore.schema.verification的值改为false
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in is compatible with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
</property>
原因应该是Hive的jar包和存储元数据信息版本不一致,这里设置不验证就可以了。
参考博客:http://www.cnblogs.com/rocky-AGE-24/p/7345417.html
http://blog.csdn.net/jyl1798/article/details/41087533
http://dblab.xmu.edu.cn/blog/1086-2/
http://blog.csdn.net/youngqj/article/details/19987727
Spark-SQL连接Hive的更多相关文章
- Spark SQL with Hive
前一篇文章是Spark SQL的入门篇Spark SQL初探,介绍了一些基础知识和API,可是离我们的日常使用还似乎差了一步之遥. 终结Shark的利用有2个: 1.和Spark程序的集成有诸多限制 ...
- Hive on Spark和Spark sql on Hive,你能分的清楚么
摘要:结构上Hive On Spark和SparkSQL都是一个翻译层,把一个SQL翻译成分布式可执行的Spark程序. 本文分享自华为云社区<Hive on Spark和Spark sql o ...
- spark2.3.0 配置spark sql 操作hive
spark可以通过读取hive的元数据来兼容hive,读取hive的表数据,然后在spark引擎中进行sql统计分析,从而,通过spark sql与hive结合实现数据分析将成为一种最佳实践.配置步骤 ...
- spark sql数据源--hive
使用的是idea编辑器 spark sql从hive中读取数据的步骤:1.引入hive的jar包 2.将hive-site.xml放到resource下 3.spark sql声明对hive的支持 案 ...
- Spark SQL读取hive数据时报找不到mysql驱动
Exception: Caused by: org.datanucleus.exceptions.NucleusException: Attempt to invoke the "BoneC ...
- Spark SQL与Hive on Spark的比较
简要介绍了SparkSQL与Hive on Spark的区别与联系 一.关于Spark 简介 在Hadoop的整个生态系统中,Spark和MapReduce在同一个层级,即主要解决分布式计算框架的问题 ...
- Spark SQL 操作Hive 数据
Spark 2.0以前版本:val sparkConf = new SparkConf().setAppName("soyo") val spark = new SparkC ...
- spark sql 查询hive表并写入到PG中
import java.sql.DriverManager import java.util.Properties import com.zhaopin.tools.{DateUtils, TextU ...
- spark sql 访问hive数据时找不mysql的解决方法
我尝试着在classpath中加n入mysql的驱动仍不行 解决方法:在启动的时候加入参数--driver-class中加入mysql 驱动 [hadoop@master spark-1.0.1-bi ...
- Hive、Spark SQL、Impala比较
Hive.Spark SQL.Impala比较 Hive.Spark SQL和Impala三种分布式SQL查询引擎都是SQL-on-Hadoop解决方案,但又各有特点.前面已经讨论了Hi ...
随机推荐
- pyspark 连 MongoDB复制集
解决问题思路: 核心:0-理解pyspark的执行与java jar的关系: 1-看控制台,看日志: 2-jar缺不缺,版本号,放哪里. [root@hadoop1 mylocalRepository ...
- fminunc
options = optimset('GradObj', 'on', 'MaxIter', 400); % Run fminunc to obtain the optimal theta% This ...
- 织梦dedecms中修改标题与简略标题长度的方法
本文介绍了dedecms中修改标题与简略标题长度的方法,进入dedecms后台,系统——系统基本参数——其他选项——文档标题最大长度——在这修改为200或更大. 一.修改标题 进入dedecms后台, ...
- Web前端性能优化经验分享
最近一直有给新同学做前端方面的培训,也有去参与公司前端的招聘,所以把自己资料库里面很多高效且有用的知识做了些 规整分类,然后再分享一篇关于前端优化方面的总结.而且春节一过就又是招聘的高峰期了,在校的. ...
- LoadRunner使用动态链接库技术
什么是动态库? 动态库一般又叫动态链接库英文为DLL,是Dynamic Link Library 的缩写形式,DLL是一个包含可由多个程序同时使用的代码和数据的库,DLL不是可执行文件.动态链接提供了 ...
- HTTPS站点搭建教程:Win7/Windows Server 2008R2
本文将由笔者为各位读者介绍在win7/windows server 2008R2环境下使用SSL加密协议建立WWW站点的全过程:https SSL证书安装的搭建以及本地测试环境. 要想成功架设SSL安 ...
- hdu-3592 World Exhibition(差分约束)
题目链接: World Exhibition Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/ ...
- VM 下安装ghost版系统
一.首先分区,并激活主分区 二.设置cd-rom的接口为IDE(这项看情况来设置,如果提示 "units specified don't exist, SHSUCDX can't insta ...
- iOS成员变量、实例变量、属性变量三者的联系与区别
一.类Class中的属性property 在ios第一版中: 我们为输出口同时声明了属性和底层实例变量,那时,属性是oc语言的一个新的机制,并且要求你必须声明与之对应的实例变量,例如: 注意:(这个是 ...
- IOS中的沙盒机制
IOS中的沙盒机制(SandBox)是一种安全体系,它规定了应用程序只能在为该应用创建的文件夹内读取文件,不可以访问其他地方的内容.所有的非代码文件都保存在这个地方,比如图片.声音.属性列表和文本文件 ...