mysql索引原理及创建与查询
索引介绍
一:为什么要有索引
索引是用来优化查询效率(速度)的
没有索引的话,对于大数据的表,就只能每次都遍历一遍,数据量越大,耗时越多
有索引的话,可以提升好几个数量级的速度
一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句的优化显然是重中之重。说起加速查询,就不得不提到索引了。
二:什么是索引
索引在mysql中叫做key(键)
是存储引擎用于快速找到记录的一种数据结构
索引可以理解为字典中的目录部分
是以类似二叉树的形式组织的,一般2-4层
三:索引误区
索引多:提升了查询速度,但是磁盘IO会爆掉
索引少:影响查询速度,提升了应用性能
因此要具体分析
索引原理
一 索引原理
通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件
索引的排列是从左到右越来越大的
二 磁盘IO与预读
磁盘读取数据靠的是机械运动
读数据时间=寻道时间+旋转延迟+传输时间=9ms
寻到时间:5ms
旋转延迟:4ms
传输时间:从内存到磁盘或从磁盘到内存,忽略不计
所以要尽量减少磁盘IO
预读:
考虑到磁盘IO是非常高昂的操作,计算机操作系统做了一些优化,当一次IO时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,因为局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。每一次IO读取的数据我们称之为一页(page)。具体一页有多大数据跟操作系统有关,一般为4k或8k,也就是我们读取一页内的数据时候,实际上才发生了一次IO,这个理论对于索引的数据结构设计非常有帮助。
索引的数据结构
这种数据组织结构就是索引
b+树:
这种数据结构能够,每次查找数据时把磁盘IO次数控制在一个很小的数量级
b+树的查找IO;
如果是百万量级的数据:没有索引要有百万次的IO
有了索引只需要3次IO即可,由此可见索引的优势
创建索引注意事项:
1.索引字段要尽量的小
io次数取决于b+树的高度,索引字段越小,每个磁盘块的数据项就能存越多,高度就越低。
2.索引的最左匹配特性
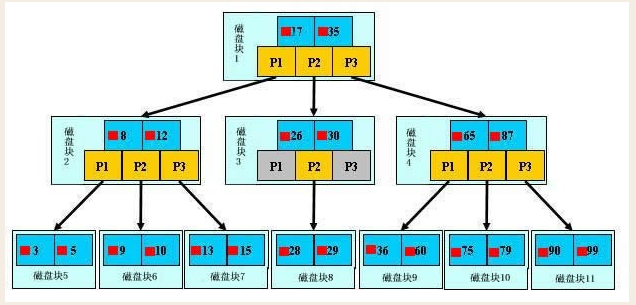
聚集索引与辅助索引
聚集索引与辅助索引相同的是:不管是聚集索引还是辅助索引,其内部都是B+树的形式,即高度是平衡的,叶子结点存放着所有的数据。
聚集索引与辅助索引不同的是:叶子结点存放的是否是一整行的信息
由于实际的数据页只能按照一棵B+树进行排序,因此每张表只能拥有一个聚集索引
聚集索引能够在B+树索引的叶子节点上直接找到数据
辅助索引的叶子节点不包含行记录的全部数据。
叶子节点除了包含键值以外,每个叶子节点中的索引行中还包含一个书签该书签用来告诉InnoDB存储引擎去哪里可以找到与索引相对应的行数据
primary key:聚集索引
其他 key:辅助索引
索引功能
普通索引INDEX:加速查找
唯一索引:
-主键索引PRIMARY KEY:加速查找+约束(不为空、不能重复)
-唯一索引UNIQUE:加速查找+约束(不能重复)
联合索引:
-PRIMARY KEY(id,name):联合主键索引
-UNIQUE(id,name):联合唯一索引
-INDEX(id,name):联合普通索引
创建和删除索引的语法
#方法一:创建表时
CREATE TABLE 表名 (
字段名1 数据类型 [完整性约束条件…],
字段名2 数据类型 [完整性约束条件…],
[UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY
[索引名] (字段名[(长度)] [ASC |DESC])
);
#方法二:CREATE在已存在的表上创建索引
CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名
ON 表名 (字段名[(长度)] [ASC |DESC]) ;
#方法三:ALTER TABLE在已存在的表上创建索引
ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX
索引名 (字段名[(长度)] [ASC |DESC]) ;
#删除索引:DROP INDEX 索引名 ON 表名字;
#方式一
create table t1(
id int,
name char,
age int,
sex enum('male','female'),
unique key uni_id(id),
index ix_name(name) #index没有key
);
#方式二
create index ix_age on t1(age);
#方式三
alter table t1 add index ix_sex(sex);
mysql索引原理及创建与查询的更多相关文章
- MySQL索引原理及慢查询优化
原文:http://tech.meituan.com/mysql-index.html 一个慢查询引发的思考 select count(*) from task where status=2 and ...
- (转)MySQL索引原理及慢查询优化
转自美团技术博客,原文地址:http://tech.meituan.com/mysql-index.html 建索引的一些原则: 1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到 ...
- MySQL索引原理及慢查询优化 转载
原文地址: http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能 ...
- MySQL索引原理及慢查询优化(转)
add by zhj:这是美团点评技术团队的一篇文章,讲的挺不错的. 原文:http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰 ...
- 【转载】MySQL索引原理及慢查询优化
原文链接:美团点评技术团队:http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型 ...
- 干货:MySQL 索引原理及慢查询优化
MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能出色,但所谓"好马配好鞍",如何能够更好的使用它,已经成为开发工程师的必修 ...
- MySQL索引原理及慢查询优化(转自:美团tech)
背景 MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能出色,但所谓“好马配好鞍”,如何能够更好的使用它,已经成为开发工程师的必修课,我们经常会 ...
- MySQL索引原理及慢查询优化-来自美团网的技术blog(写的深入浅出)
MySQL索引原理及慢查询优化 转:http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首 ...
- [转]MySQL索引原理及慢查询优化
MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能出色,但所谓“好马配好鞍”,如何能够更好的使用它,已经成为开发工程师的必修课,我们经常会从职位 ...
随机推荐
- 正则表达式、Calendar类、SimpleDateFormat类、Date类、BigDecimal类、BigInteger类、System类、Random类、Math类(Java基础知识十四)
1.正则表达式的概述和简单使用 * A:正则表达式(一个字符串,是规则) * 是指一个用来描述或者匹配一系列符合某个语法规则的字符串的单个字符串.其实就是一种规则.有自己特殊的应用. * B: ...
- Java中的Lock
同步机制是Java并发编程中最重要的机制之一,锁是用来控制多个线程访问共享资源的方式,一般来说,一个锁能防止多个线程同时访问共享资源(但是也有例外,比如读写锁).Java中可以使用synchroniz ...
- iOS NSInteger/NSUInteger与int/unsigned int、long/unsigned long之间的区别!
在iOS开发中经常使用NSInteger和NSUInteger,而在其他的类似于C++的语言中,我们经常使用的是int.unsigned int.我们知道iOS也可以使用g++编译器,那么它们之间是否 ...
- BZOJ_4698_Sdoi2008 Sandy的卡片_后缀数组+单调队列+双指针
BZOJ_4698_Sdoi2008 Sandy的卡片_后缀数组 Description Sandy和Sue的热衷于收集干脆面中的卡片.然而,Sue收集卡片是因为卡片上漂亮的人物形象,而Sandy则是 ...
- 空间数据索引RTree完全解析及Java实现
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/MongChia1993/article/details/69941783 第一部分 空间数据的背景介 ...
- 杂项-公司:Aspose
ylbtech-杂项-公司:Aspose Aspose 于2002年3月在澳大利亚悉尼创建,旗下产品覆盖文档.图表.PDF.条码.OCR.CAD.HTML.电子邮件等各个文档管理领域,为全球.NET ...
- 从零开始构建一个Reactor模式的网络库(一) 线程同步Mutex和Condition
最近在学习陈硕大神的muduo库,感觉写的很专业,以及有一些比较“高级”的技巧和设计方式,自己写会比较困难. 于是打算自己写一个简化版本的Reactor模式网络库,就取名叫mini吧,同样只基于Lin ...
- 019--python内置函数
一.内置高阶函数 map函数:接收两个数据 函数和序列,map()将函数调用'映射'到序列身上,并返回一个含有所有返回值的一个列表 num1 = [1,2,3,4,5] num2 = [5,4,3,2 ...
- vim中编辑了代码 但是提示can not write的解决办法和代码对齐办法
方式1: 1 :w /tmp/xxxx(如果是c文件就.c拉) 保存在/tmp下面 2 从tmp中复制到有权限的目录下面 cp /tmp xxxx ./(当前目录) 方式2::w !sudo tee ...
- bzoj 1396: 识别子串【SAM+线段树】
建个SAM,符合要求的串显然是|right|==1的节点多代表的串,设si[i]为right集合大小,p[i]为right最大的r点,这些都可以建出SAM后再parent树上求得 然后对弈si[i]= ...