UFLDL教程笔记及练习答案二(预处理:主成分分析和白化)
首先将本节主要内容记录下来。然后给出课后习题的答案。
笔记:
1:首先我想推导用SVD求解PCA的合理性。
PCA原理:如果样本数据X∈Rm×n。当中m是样本数量,n是样本的维数。PCA降维的目的就是为了使将数据样本由原来的n维减少到k维(k<n)。方法是找数据随之变化的主轴,在Andrew
Ng的网易公开课上我们知道主方向就是X的协方差所相应的最大特征值所相应的特征向量的方向(前提是这里X在维度上已经进行了均值归一化)。
在matlab中我们通常能够用princomp函数来求解,具体见:http://blog.csdn.net/lu597203933/article/details/41544547。这里我们解说怎样用svd来求解。 我们的目的就是要求协方差矩阵所相应的特征值和特征向量。
神秘值分解求解:
我们知道神秘值分解矩阵表示为:X =SVDT,当中S是X*XT的特征向量(Rm×m)。而V是对角矩阵(Rm×n),每个对象值称为X的神秘值,是X*XT或者XT*X的特征值的非负平方根;D是XT*X的特征向量(Rn×n)。当样本X在维度上进行了均值归一化,那么它的协方差就是:

因此D每一列都是协方差矩阵的的特征向量。因此Xpca=X*D就是PCA后的结果。
用上面对X进行神秘值分解求解协方差矩阵的特征向量(即数据随之变化的主方向),全然是依据矩阵的神秘值分解定义得来的。可是存在这一个这种问题。当样本个数m很大时。我们须要的存储空间是m×m+m×n+n×n将会很大。那么我们有没有简便的方法呢。我们按例如以下公式求解
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvTHU1OTcyMDM5MzM=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center" alt="">
这里的sigma为协防差矩阵(Rn×n)。是对称半正定矩阵,依照神秘值分解的定义这里的S是sigma*sigmaT的特征向量。V为其sigma的神秘值,D为sigmaT*sigma的特征向量,也就是S的转置。以下我们证明这里的S也是XT*X(X的协方差)的特征向量。V为协方差的特征值(有个倍数关系)。
由定义我们能够得知以下公式(大S和小s是区分开的;当中小d为协方差的特征向量,v为协方差特征值的非负平方根)

以下是推导过程:

我们能够看出小d就等于大S。也就是说sigma的神秘值分解得到的S就是我们要求的协方差(sigma)的特征向量。而m*V=vTv。得出sigma的神秘值正好是X的神秘值的平方(即为sigma的特征值)的倍数,这样也就能够通过前k个V个神秘值(即协方差的前k个特征值)所占的比重来决定k的大小。
因为sigma是Rn×n。与样本大小无关,因此我们通过对sigma进行神秘值分解间接得到协方差矩阵的特征向量和特征值所须要的存储空间为4*n*n。在样本数量非常大的时候,对空间要求将是大大的缩减。
因此我们通经常使用svd求解pca的代码例如以下:
avg = mean(X, 1);
X = X - repmat(avg, size(X,1),1);
sigma = X'*X./size(X,1);
[S,V,D]= svd(sigma);
Xpca = X*S;
结论:
[S,V,DT]= svd(sigma)得到的S是XTX(协方差)的特征向量。V是协方差的特征值矩阵,V也是X通过PCA后的数据的协方差矩阵,为对角矩阵。这样就表明去除了各个维度之间的相关性了。。
2:PCA白化和ZCA白化
在我们得到Xpca之后,它的协方差:

我们得出了PCA后数据的协方差就是原始数据协方差的特征值构成的矩阵V,故其为对角矩阵。除了对象元素,其他元素均为0,这说明其他维度之间没有相关性,即去除了数据之间的冗余。
PCA白化就是使PCA后数据(更准确的说是旋转之后的数据)的协方差变为单位矩阵,此时我们能够通过下面公式的得到。直接使用作为缩放因子来缩放每一个特征

考虑到特征值有可能为0,因此我们对其进行来正则化:

ZCA白化就是通过重构PCA白化后的原始数据,其协方差矩阵也是单位矩阵,非常多算法都是用白化作为预处理的步骤的,这样就去除了各个维度之间的相关性,得到对原始图像更低冗余的表示。

3:对图像数据应用PCA算法
这个在UFLDL教程有一小节,意思就是比方从图像中得到一个patch(14*14),是一个196维的向量,我们须要做的是将这196维向量的均值归一化为0(无需做方差归一化)。可是注意这里和上面是有差别的,上面是对每个维度进行均值归一化。而这里是对每个样本进行均值归一化(我也不太理解为什么这样处理~~),教程给出的理由是“对每个像素单独预计均值和方差意义不大。由于(理论上)图像任一部分的统计性质都应该和其他部分同样”这样就能保证全部的特征的均值在0附近。“依据应用。在大多数情况下,我们并不关注所输入图像的总体明亮程度。比方在对象识别任务中。图像的总体明亮程度并不会影响图像中存在的是什么物体。
更为正式地说,我们对图像块的平均亮度值不感兴趣,所以能够减去这个值来进行均值规整化”。
这样处理之后再对数据进行上述描写叙述的由svd求PCA后的数据及白化。
在进行 PCA/ZCA 白化时,首先使特征零均值化是非常有必要的。这保证了 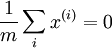 。
。
特别地。这一步须要在计算协方差矩阵前完毕。(唯一例外的情况是已经进行了逐样本均值消减,而且数据在各维度上或像素上是平稳的。)
练习答案:
须要注意的是下面联系的X是n×m维的。1 exercise:pca in 2D是对数据的维度进行均值归一化。。而2: Exercise:PCA and Whitening是对每个样本进行均值归一化(对图像的应用)
1: Exercise:PCA in 2D
(1)% Step 1a: Implement PCA to obtain U
u = zeros(size(x, 1)); % You need to compute this
avg = mean(x,2); %按行求取均值
x = x - repmat(avg, 1,size(x,2)); %% size(x,2) = 45
sigma = x * x'/ size(x,2);
[u, s, v] = svd(sigma);
(2)Step 1b: Compute xRot, the projection on to the eigenbasis
xRot = u'* x;
(3)%% Step 2: Reduce the number ofdimensions from 2 to 1.
k = 1; % Use k = 1 and project the data onto the first eigenbasis
xHat = zeros(size(x)); % You need to compute this
x_ap = u(:,1:k)'*x;
xHat(1:k,:) = x_ap;
xHat = u*xHat;
(4)%% Step 3: PCA Whitening
xPCAWhite = diag(1./sqrt(diag(s) + epsilon)) * u' * x;
(5) %% Step 3: ZCA Whitening
xZCAWhite = u*diag(1./sqrt(diag(s) + epsilon)) * u' * x;
2: Exercise:PCA and Whitening
(1)% Step 0b: Zero-mean the data (byrow)
avg = mean(x, 1);
x = x - repmat(avg, size(x,1), 1);
(2)% Step 1a: Implement PCA to obtainxRot
xRot = zeros(size(x)); % You need to compute this
sigma = x*x'./size(x, 2);
[U,S,V] = svd(sigma);
xRot = U'*x;
(3)Step 1b: Check your implementationof PCA
covar = zeros(size(x, 1)); % You need to compute this
covar = xRot*xRot'/size(xRot,2);
(4)Step 2: Find k, the number of components to retain
k = 0; % Set k accordingly
sum_k = 0;
sum = trace(S);
for k = 1:size(S,1)
sum_k = sum_k + S(k,k);
if(sum_k/sum >= 0.99)
break;
end
end
(5)%% Step 3: Implement PCA with dimension reduction
xHat = zeros(size(x)); % You need to compute this %%%%% 还原近似数据
xTilde = U(:,1:k)' * x;
xHat(1:k,:)=xTilde;
xHat=U*xHat;
(6)%% Step 4a: Implement PCA withwhitening and regularisation
xPCAWhite = diag(1./sqrt(diag(S) + epsilon)) * U' * x;
(7) % Step 4b: Check yourimplementation of PCA whitening
covar = xPCAWhite * xPCAWhite'./size(xPCAWhite, 2);
(8)Step 5: Implement ZCA whitening
xZCAWhite = U * diag(1./sqrt(diag(S) + epsilon)) * U' * x;
UFLDL教程笔记及练习答案二(预处理:主成分分析和白化)的更多相关文章
- UFLDL教程笔记及练习答案三(Softmax回归与自我学习***)
:softmax回归 当p(y|x,theta)满足多项式分布,通过GLM对其进行建模就能得到htheta(x)关于theta的函数,将其称为softmax回归. 教程中已经给了cost及gradie ...
- UFLDL教程笔记及练习答案五(自编码线性解码器与处理大型图像**卷积与池化)
自己主动编码线性解码器 自己主动编码线性解码器主要是考虑到稀疏自己主动编码器最后一层输出假设用sigmoid函数.因为稀疏自己主动编码器学习是的输出等于输入.simoid函数的值域在[0,1]之间,这 ...
- UFLDL 教程三总结与答案
主成分分析(PCA)是一种能够极大提升无监督特征学习速度的数据降维算法.更重要的是,理解PCA算法,对实现白化算法有很大的帮助,很多算法都先用白化算法作预处理步骤.这里以处理自然图像为例作解释. 1. ...
- UFLDL 教程学习笔记(四)主成分分析
UFLDL(Unsupervised Feature Learning and Deep Learning)Tutorial 是由 Stanford 大学的 Andrew Ng 教授及其团队编写的一套 ...
- Deep Learning 12_深度学习UFLDL教程:Sparse Coding_exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程.Deep learning:二十六(Sparse coding简单理解).Deep learning:二十七(Sparse coding中关于矩阵的范数求导).Deep ...
- Deep Learning 11_深度学习UFLDL教程:数据预处理(斯坦福大学深度学习教程)
理论知识:UFLDL数据预处理和http://www.cnblogs.com/tornadomeet/archive/2013/04/20/3033149.html 数据预处理是深度学习中非常重要的一 ...
- CG基础教程-陈惟老师十二讲笔记
转自 麽洋TinyOcean:http://www.douban.com/people/Tinyocean/notes?start=50&type=note 因为看了陈惟十二讲视频没有课件,边 ...
- UFLDL教程练习(exercise)答案(2)
主成分分析与白化,这部分很简单,当然,其实是用Matlab比较简单,要是自己写SVD分解算法,足够研究好几个月的了.下面是我自己实现的练习答案,不保证完全正确,不过结果和网站上面给出的基本一致. 1. ...
- Deep Learning 10_深度学习UFLDL教程:Convolution and Pooling_exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程和http://www.cnblogs.com/tornadomeet/archive/2013/04/09/3009830.html 实验环境:win7, matlab ...
随机推荐
- EasyUI - Tree 树组件
效果: 数据库设计: 使用的数据: 其中的字段,是跟据要生成的树节点的属性定义的. text:代表要显示的字段名称. state:是否是目录节点. iconCls:节点的图标是什么. url:跳转的链 ...
- 基于visual Studio2013解决C语言竞赛题之1080填运算符
题目 解决代码及点评 /************************************************************************/ /* ...
- 后台调用外部程序的完美实现(使用CreateDesktop建立隐藏桌面)
最近在做的一个软件,其中有一部分功能需要调用其它的软件来完成,而那个软件只有可执行文件,根本没有源代码,幸好,我要做的事不难,只需要在我的程序启动后,将那个软件打开,在需要的时候,对其中的一个文本矿设 ...
- mysql 分区和集群
集群和分区:http://han-zw.iteye.com/blog/1662941http://www.php-note.com/article/detail/794 分区:http://lober ...
- hdu 4090 GemAnd Prince
题目大意: 别人说是消消看,至于你玩没玩过.反正我是没玩过的. 就是选择一个钻石,可以消除与它相连的所有钻石.并获得 消除数量*消除数量 的分 思路: 直接暴搜,然后用一个cnt数组表示每一种钻石剩 ...
- KNN算法理解
一.算法概述 1.kNN算法又称为k近邻分类(k-nearest neighbor classification)算法. 最简单平庸的分类器或许是那种死记硬背式的分类器,记住全部的训练数据,对于新的数 ...
- hdu 1387 Team Queue (链表)
题目大意: 不同的人在不同的队伍里,插入链表的时候假设这个链表里有他的队友,就把它放到最后一个队友的最后.假设没有队友,就把它放到整个链表的最后面. 出链表的时候把第一个人拿出来. 思路分析: 要模拟 ...
- XML wsdl soap xslt xsl ide
XML wsdl soap xslt xsl ide 作者Attilax , EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http://blog.csdn. ...
- 一个解析RTSP 的URL函数
写了一个解析URL的函数,可以提取URL中的IP 和 port. 如:url = "rtsp://192.168.1.43:2554/realmp3.mp3"; url = &qu ...
- Windows DIB文件操作具体解释-5.DIB和调色板
Windows调色板是256色显卡时期的产物,如今显卡最少也是16bit的了.所以调色板基本上是用不到了的. 可是以下几种情况还是须要去使用和了解调色板: 1.在新显卡上保证256色兼容模式的正常执行 ...