Beanstalkd使用
Beanstalkd,一个高性能、轻量级的分布式内存队列系统,最初设计的目的是想通过后台异步执行耗时的任务来降低高容量Web应用系统的页面访问延迟,支持过有9.5 million用户的Facebook Causes应用。后来开源,现在有PostRank大规模部署和使用,每天处理百万级任务。Beanstalkd是典型的类Memcached设计,协议和使用方式都是同样的风格,所以使用过memcached的用户会觉得Beanstalkd似曾相识。
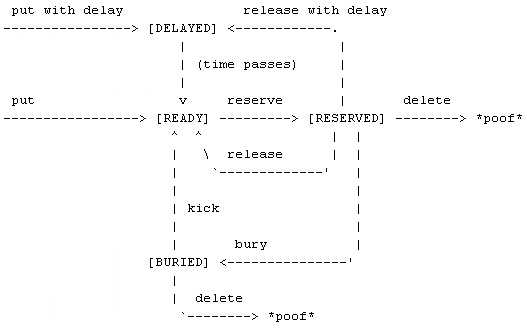
Beanstalkd中一个job的生命周期如图所示。一个job有READY, RESERVED, DELAYED, BURIED四种状态。当producer直接put一个job时,job就处于READY状态,等待consumer来处理,如果选择延迟put,job就先到DELAYED状态,等待时间过后才迁移到READY状态。consumer获取了当前READY的job后,该job的状态就迁移到RESERVED,这样其他的consumer就不能再操作该job。当consumer完成该job后,可以选择delete, release或者bury操作;delete之后,job从系统消亡,之后不能再获取;release操作可以重新把该job状态迁移回READY(也可以延迟该状态迁移操作),使其他的consumer可以继续获取和执行该job;有意思的是bury操作,可以把该job休眠,等到需要的时候,再将休眠的job kick回READY状态,也可以delete BURIED状态的job。正是有这些有趣的操作和状态,才可以基于此做出很多意思的应用,比如要实现一个循环队列,就可以将RESERVED状态的job休眠掉,等没有READY状态的job时再将BURIED状态的job一次性kick回READY状态。
特性:
为了防止某个consumer长时间占用任务但不能处理的情况,Beanstalkd为reserve操作设置了timeout时间,如果该consumer不能在指定时间内完成job,job将被迁移回READY状态,供其他consumer执行。
下载:
服务端:http://kr.github.io/beanstalkd/download.html
客户端:https://github.com/kr/beanstalkd/wiki/client-libraries
安装:
ubuntu
sudo apt-get install beanstalkd
centos
yum install beanstalkd
源码安装
|
1
2
3
4
5
|
tar -zxvf /usr/bin/beanstalkd/beanstalkd-1.9.tar.gzcd beanstalkdmake install PERFIX=/usr/bin/beanstalkd |
后台启动:
beanstalkd -l 地址 -p 端口号 -z 最大的任务大小(byte) -c &
如果是外部客户端连接,ip地址要写外网地址,这样才能连接上
启动选项
-b DIR wal directory
-f MS fsync at most once every MS milliseconds (use -f0 for "always fsync")
-F never fsync (default)
-l ADDR listen on address (default is 0.0.0.0)
-p PORT listen on port (default is 11300)
-u USER become user and group
-z BYTES set the maximum job size in bytes (default is 65535)
-s BYTES set the size of each wal file (default is 10485760)
(will be rounded up to a multiple of 512 bytes)
-c compact the binlog (default)
-n do not compact the binlog
-v show version information
-V increase verbosity
-h show this help
php客户端的使用:我使用的是这个简易的类 https://github.com/davidpersson/beanstalk
发送任务:
<?php
//发送任务 require_once 'src/Socket/Beanstalk.php'; //实例化beanstalk
$beanstalk = new Socket_Beanstalk(array(
'persistent' => false, //是否长连接
'host' => 'ip地址',
'port' => , //端口号默认11300
'timeout' => //连接超时时间
)); if (!$beanstalk->connect()) {
exit(current($beanstalk->errors()));
}
//选择使用的tube
$beanstalk->useTube('test');
//往tube中增加数据
$put = $beanstalk->put(
, // 任务的优先级.
, // 不等待直接放到ready队列中.
, // 处理任务的时间.
'hello, beanstalk' // 任务内容
); if (!$put) {
exit('commit job fail');
} $beanstalk->disconnect();
处理任务:
<?php
require_once 'src/Socket/Beanstalk.php';
//实例化beanstalk
$beanstalk = new Socket_Beanstalk(array(
'persistent' => false, //是否长连接
'host' => 'ip地址',
'port' => 11600, //端口号默认11300
'timeout' => 3 //连接超时时间
)); if (!$beanstalk->connect()) {
exit(current($beanstalk->errors()));
}
//查看beanstalkd状态
//var_dump($beanstalk->stats()); //查看有多少个tube
//var_dump($beanstalk->listTubes()); $beanstalk->useTube('test'); //设置要监听的tube
$beanstalk->watch('test'); //取消对默认tube的监听,可以省略
$beanstalk->ignore('default'); //查看监听的tube列表
//var_dump($beanstalk->listTubesWatched()); //查看test的tube当前的状态
//var_dump($beanstalk->statsTube('test')); while (true) {
//获取任务,此为阻塞获取,直到获取有用的任务为止
$job = $beanstalk->reserve(); //返回格式array('id' => 123, 'body' => 'hello, beanstalk') //处理任务
$result = doJob($job['body']); if ($result) {
//删除任务
$beanstalk->delete($job['id']);
} else {
//休眠任务
$beanstalk->bury($job['id']);
}
//跳出无限循环
if (file_exists('shutdown')) {
file_put_contents('shutdown', 'beanstalkd在'.date('Y-m-d H:i:s').'关闭');
break;
}
}
$beanstalk->disconnect();
除此之外:http://blog.csdn.net/black_ox/article/details/24792489
Beanstalkd使用的更多相关文章
- Beanstalkd一个高性能分布式内存队列系统
高性能离不开异步,异步离不开队列,内部是Producer-Consumer模型的原理. 设计中的核心概念: job:一个需要异步处理的任务,是beanstalkd中得基本单元,需要放在一个tube中: ...
- beanstalkd 消息队列
概况:Beanstalkd,一个高性能.轻量级的分布式内存队列系统,最初设计的目的是想通过后台异步执行耗时的任务来降低高容量Web应用系统的页面访问延迟,支持过有9.5 million用户的Faceb ...
- 轻量级队列beanstalkd
一.基本Beanstalkd,一个高性能.轻量级的分布式内存队列系统,最初设计的目的是想通过后台异步执行耗时的任务来降低高容量Web应用系统的页面访问延迟,支持过有9.5 million用户的Face ...
- centos 安装beanstalkd
You need to have the EPEL repo (http://www.servermom.org/2-cents-tip-how-to-enable-epel-repo-on-cent ...
- 【转】Beanstalkd 队列简易使用
Beanstalkd一个高性能分布式内存队列系统 之前在微博上调查过大家正在使用的分布式内存队列系统,反馈有Memcacheq,Fqueue, RabbitMQ, Beanstalkd以及link ...
- 高性能分布式内存队列系统beanstalkd(转)
beanstalkd一个高性能.轻量级的分布式内存队列系统,最初设计的目的是想通过后台异步执行耗时的任务来降低高容量Web应用系统的页面访问延迟,支持过有9.5 million用户的Facebook ...
- 使用Beanstalkd实现队列
Beanstalkd可以想象成缓存当中的memcahe或者redise,将我们的队列任务放到内存中进行管理. 运行环境是在linux中,反正我的windows中没运行成功.../(ㄒoㄒ)/~~ 首先 ...
- Beanstalkd(ubuntu安装)
安装Beanstalkd # apt-get install beanstalkd Unubtu 开启beanstalkd的持久化选项 #vim /etc/default/beanstalkd 把S ...
- Beanstalkd介绍
特征 优先级:任务 (job) 可以有 0~2^32 个优先级, 0 代表最高优先级,beanstalkd 采用最大最小堆 (Min-max heap) 处理任务优先级排序, 任何时刻调用 reser ...
- Beanstalkd
摘要by ck:beanstalkd 和 kafka的本质区别是什么? Beanstalkd,一个高性能.轻量级的分布式内存队列系统,最初设计的目的是想通过后台异步执行耗时的任务来降低高容量Web ...
随机推荐
- PAT1009
多项式乘法 和多项式加法类似,参考之前多项式加法的代码改改就出来了. 主要是注意一下.最大次数应该会有1000000,然后按照乘法规则来,分配率就没有问题 #include<cstdio> ...
- dedecms 的这个dede:arclist里怎么调用全局变量?
将{dede:global.cfg_templets_skin/} 写为 [field:global.cfg_templets_skin/] 即可.
- json python api
摘要:对于python来说,json并不是一种数据类型,可以把它视为函数.json.dumps把字典或列表变成json风格的str类型:json.loads把json风格的str类型变成原来的类型(列 ...
- GtkImageMenuItem
做了个工具条,每次点arrow出来的菜单都没图标,郁闷;查来查去,看源码,看css,最后知道GtkAction缺省就是对应GtkImageMenuItem,再一试,跟toolbar无关,换menu也不 ...
- PAT (Advanced Level) 1028. List Sorting (25)
时间卡的比较死,用string会超时. #include<cstdio> #include<cstring> #include<cmath> #include< ...
- CodeForces 590B Chip 'n Dale Rescue Rangers
这题可以o(1)推出公式,也可以二分答案+验证. #include<iostream> #include<cstring> #include<cmath> #inc ...
- 伸展二叉树树(C#)
参考过好几篇关于将伸展树的代码,发现看不懂.看图能看懂原理.就尝试自己实现了下. 自顶向上的算法. using System; using System.Collections.Generic; us ...
- 目前所有的ANN神经网络算法大全
http://blog.sina.com.cn/s/blog_98238f850102w7ik.html 目前所有的ANN神经网络算法大全 (2016-01-20 10:34:17) 转载▼ 标签: ...
- Is it possible to run native sql with entity framework?
For .NET Framework version 4 and above: use ObjectContext.ExecuteStoreCommand() if your query return ...
- away3d 汽车路线编辑器
2012年的时候,跟朋友去到一个公司,打算用away3d做一个赛车模拟养成游戏,后来由于种种原因,立项未成,由于朋友已经转行,自己也想对自己做过的事情有一些交代,所以将我负责的部分,赛道编辑器的源码公 ...