Python标准库之shelve模块(序列化与反序列化)
shelve模块是一个简单的key,value将内存数据通过文件持久化的模块,可以持久化任何picklel可支持的Python数据格式。
序列化
序列化源代码:
import shelve
import os f = shelve.open("shelve_log") d = {'1':'a','2':'b'} def test():
return os.system("calc") f['dict'] = d
f['func'] = test
f.close()
运行后会在当前目录下生成后缀为bak、dat、dir文件。
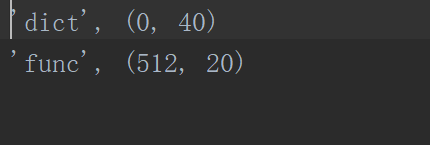
打开后三份文件都是一样的,内容如下:
反序列化
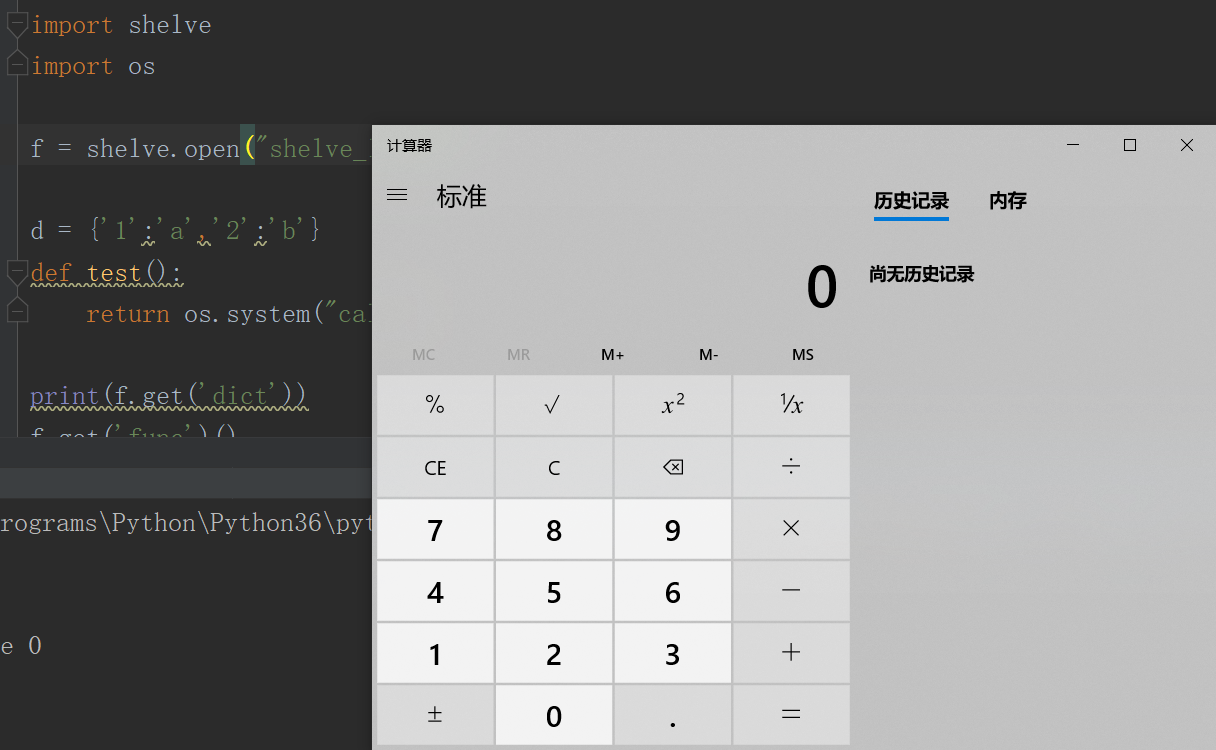
反序列化读取:
import shelve
import os f = shelve.open("shelve_log") d = {'1':'a','2':'b'} #这行不可少
def test(): #这行不可少
return os.system("calc") #这行不可少 print(f.get('dict'))
f.get('func')()
Python标准库之shelve模块(序列化与反序列化)的更多相关文章
- (转)python标准库中socket模块详解
python标准库中socket模块详解 socket模块简介 原文:http://www.lybbn.cn/data/datas.php?yw=71 网络上的两个程序通过一个双向的通信连接实现数据的 ...
- Python标准库之Sys模块使用详解
sys 模块提供了许多函数和变量来处理 Python 运行时环境的不同部分. 处理命令行参数 在解释器启动后, argv 列表包含了传递给脚本的所有参数, 列表的第一个元素为脚本自身的名称. 使用sy ...
- Python标准库之subprocess模块
运行python的时候,我们都是在创建并运行一个进程.像Linux进程那样,一个进程可以fork一个子进程,并让这个子进程exec另外一个程序.在Python中,我们通过标准库中的subprocess ...
- Python标准库之核心模块学习记录
内建函数和异常 包括__builtin__模块和exceptions模块 操作系统接口模块 包括提供文件和进程处理功能的os模块,提供平台独立的文件名处理(分拆目录名,文件名,后缀等)的os.path ...
- Python标准库之logging模块
很多程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能有错误.警告等信息输出,python的logging模块提供了标准的日志接口,你可以通过它存储各种格式的日志,loggin ...
- Python标准库之os模块
1.删除和重命名文件 import os import string def replace(file, search_for, replace_with): # replace strings in ...
- python标准库之random模块
Python中的random模块用于生成随机数. 下面具体介绍random模块的功能: 1.random.random() #用于生成一个0到1的 随机浮点数:0<= n < 1.0 1 ...
- python - 标准库:subprocess模块
subprocess的目的就是启动一个新的进程并且与之通信. subprocess模块中只定义了一个类: Popen. subprocess.Popen(args, bufsize=0, execut ...
- Python标准库之hashlib模块与hmac模块
hashlib模块用于加密相关的操作.在Python 3.x里代替了md5模块和sha模块,主要提供 SHA1.SHA224.SHA256.SHA384.SHA512 .MD5 算法.如果包含中文字符 ...
随机推荐
- <Wonder Woman> 摘抄
<Wonder Woman> My father told me once, he said,“ If you see something wrong happening in the w ...
- 4~20MA 转 电压输出
ICL7660 50mA LM2662/LM2663 200mA
- java使用原生MySQL实现数据的增删改查以及数据库连接池技术
一.工具类及配置文件准备工作 1.1 引入jar包 使用原生MySQL,只需要用到MySQL连接的jar包,maven引用方式如下: <dependency> <groupId> ...
- stm32f103vct6外扩sram芯片
STM32F103是一款高性价比.多功能的单片机,配备常用的32位单片机片外资源,基于ARM Cortex-M3的32位处理器芯片,片内具有256KB FLASH,48KB RAM ( 片上集成12B ...
- 安装ubuntu到移动硬盘(UEFI+GPT),实现在别的电脑也可以使用(详细教程)
前置说明:博主小白,第一次安装ubuntu,参考了网上很多人的教程,发博记录一下自己的安装过程.由于有些地方博主理解较浅或者因为机器硬件等各方面原因,本教程适用有限,仅供参考. 1.准备工作 win系 ...
- Vue如何动态配置img标签的图片源src
(一)首先通过绑定数据给src提供图片地址 <template> <div> <img :src=image_path /> </div> </t ...
- 【新人赛】阿里云恶意程序检测 -- 实践记录11.10 - XGBoost学习 / 代码阅读、调参经验总结
XGBoost学习: 集成学习将多个弱学习器结合起来,优势互补,可以达到强学习器的效果.要想得到最好的集成效果,这些弱学习器应当"好而不同". 根据个体学习器的生成方法,集成学习方 ...
- Centos 7 安装配置git
Centos 7 安装配置git 1.安装git yum install git 2.验证git git -version 3.配置基本信息
- QFile文件读写
参考代码 .h文件 #ifndef MYWIDGET_H #define MYWIDGET_H #include <QWidget> #include <QFile> #inc ...
- [译]C# 7系列,Part 10: Span<T> and universal memory management Span<T>和统一内存管理
原文:https://blogs.msdn.microsoft.com/mazhou/2018/03/25/c-7-series-part-10-spant-and-universal-memory- ...