python机器学习——正则化
我们在训练的时候经常会遇到这两种情况:
1、模型在训练集上误差很大。
2、模型在训练集上误差很小,表现不错,但是在测试集上的误差很大
我们先来分析一下这两个问题:
对于第一个问题,明显就是没有训练好,也就是模型没有很好拟合数据的能力,并没有学会如何拟合,可能是因为在训练时我们选择了较少的特征,或者是我们选择的模型太简单了,不能稍微复杂的拟合数据,我们可以通过尝试选取更多的特征、增加一些多项式特征或者直接选用非线性的较复杂的模型来训练。
对于第二个问题,可以说是第一个问题的另外一个极端,就是模型对训练集拟合的太好了,以至于把训练集数据中的那些无关紧要的特征或者噪音也学习到了,导致的结果就是当我们使用测试集来评估模型的泛化能力时,模型表现的很差。打个不恰当比方就是你平时把作业都背下来了,但是其实你并没有学会如何正确解题,所以遇到考试就考的很差。解决方法就是增加训练集的数据量或者减少特征数量来尝试解决。
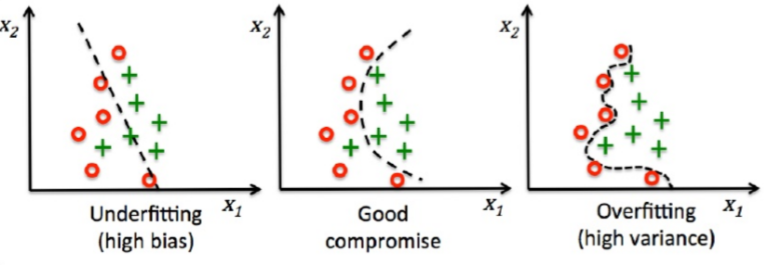
第一个问题我们叫做欠拟合(underfitting),第二个问题我们叫做过拟合(overfitting)
这两个问题还存在一种解决方法,就是我接下来要说的正则化。
我们之前说模型学习的过程也就是调整权重参数的过程,通过训练集中的数据来将模型的权重参数调整到一个使得损失函数最小的值。
对于一个分布较复杂的样本,如果训练得到的权重参数维度太少或者参数过小,也就是特征项很少,一些重要的特征没有起到作用,那么这条拟合曲线就会变得很简单,我们看上图的欠拟合图像,里面的拟合曲线是一条直线,这就是权重参数维度太少的结果。而如果权重参数维度过多或者参数过大,导致拟合曲线过于复杂,如上图的过拟合图像,拟合曲线可以完美的将两类不同的样本点区分开,但是我们也可以看出这条曲线很复杂,权重参数的项数一定很多。
现在进入正题,对于正则化,我们常见的形式是L2正则:
\[
\frac \lambda 2\lVert w \lVert^2 = \frac \lambda 2 \sum_{j=1}^m{w_j^2}
\]
这里的
\[
\lambda
\]
就是正则化系数。
我们将正则项直接添加到损失函数后即可使用,比如对于逻辑回归模型,带有L2正则项的损失函数为:
\[
J(w)=\sum_{i=1}^n\left[-y^{(i)}log(\phi(z^{(i)}))-(1-y^{(i)})log(1-\phi(z^{(i)}))\right] + \frac \lambda 2\lVert w \lVert^2
\]
我们通过控制正则化系数来控制权重参数的大小。一般正则化用于解决模型过拟合的问题,我们的训练目标是为了使损失函数最小,但是如果权重参数过大会导致过拟合,模型泛化能力下降,那么为了解决这个问题,将正则项加到损失函数后面,组成一个新的损失函数,为了最小化这个新的损失函数,我们在训练过程中不仅要使得误差小,还要保证正则项不能太大,于是如果我们选择一个较大的正则化系数,那么为了保证正则项不能太大,就会使得权重参数变小,这也就是我们的最终目的:在保证误差不大的情况下,使得权重参数也不能太大,缓解了过拟合问题。正则化系数越大,正则化越强,权重参数越小。
所以对于欠拟合的模型,我们也可以尝试减小正则化系数来增大权重参数,而对于过拟合模型,我们尝试增大正则化系数来减小权重参数。
python机器学习——正则化的更多相关文章
- Python机器学习中文版
Python机器学习简介 第一章 让计算机从数据中学习 将数据转化为知识 三类机器学习算法 第二章 训练机器学习分类算法 透过人工神经元一窥早期机器学习历史 使用Python实现感知机算法 基于Iri ...
- Python机器学习中文版目录
建议Ctrl+D保存到收藏夹,方便随时查看 人工智能(AI)学习资料库 Python机器学习简介 第一章 让计算机从数据中学习 将数据转化为知识 三类机器学习算法 第二章 训练机器学习分类算法 透过人 ...
- Python机器学习笔记:sklearn库的学习
网上有很多关于sklearn的学习教程,大部分都是简单的讲清楚某一方面,其实最好的教程就是官方文档. 官方文档地址:https://scikit-learn.org/stable/ (可是官方文档非常 ...
- Python机器学习笔记:不得不了解的机器学习面试知识点(1)
机器学习岗位的面试中通常会对一些常见的机器学习算法和思想进行提问,在平时的学习过程中可能对算法的理论,注意点,区别会有一定的认识,但是这些知识可能不系统,在回答的时候未必能在短时间内答出自己的认识,因 ...
- Python机器学习笔记:不得不了解的机器学习知识点(2)
之前一篇笔记: Python机器学习笔记:不得不了解的机器学习知识点(1) 1,什么样的资料集不适合用深度学习? 数据集太小,数据样本不足时,深度学习相对其它机器学习算法,没有明显优势. 数据集没有局 ...
- Python机器学习基础教程-第2章-监督学习之线性模型
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- 机器学习-正则化(岭回归、lasso)和前向逐步回归
机器学习-正则化(岭回归.lasso)和前向逐步回归 本文代码均来自于<机器学习实战> 这三种要处理的是同样的问题,也就是数据的特征数量大于样本数量的情况.这个时候会出现矩阵不可逆的情况, ...
- 《Python机器学习及实践:从零开始通往Kaggle竞赛之路》
<Python 机器学习及实践–从零开始通往kaggle竞赛之路>很基础 主要介绍了Scikit-learn,顺带介绍了pandas.numpy.matplotlib.scipy. 本书代 ...
- python机器学习笔记:EM算法
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域的基础,比如隐式马尔科夫算法(HMM),LDA主题模型的变分推断算法等等.本文对于E ...
随机推荐
- java反射-- Field 用法实践
java 反射是一种常用的技术手段, 通过加载类的字节码的方式来获取相关类的一些信息 比如成员变量, 成员方法等. Field 是什么呢? field 是一个类, 位于java.lang.reflec ...
- spring boot学习笔记(1)
一.构建springboot项目 可以通过idea的springboot initialization来创建, idea的功能很强大,可以自己选择需要集成的插件. 完整的项目结构是这样的: DemoA ...
- ZooKeeper Java Example
A Simple Watch Client Requirements Program Design The Executor Class The DataMonitor Class Complete ...
- 快到极致的Android模拟器——Genymotion
转载声明:Ryan的博客文章欢迎您的转载,但在转载的同时,请注明文章的来源出处,不胜感激! :-)http://my.oschina.net/ryanhoo/blog/141824 还在用Androi ...
- SpringBoot + Apache Shiro权限管理
之前配置过Spring + SpringMVC + JPA + Shiro后台权限管理 + VUE前台登录页面的框架,手动配置各种.xml,比较繁琐,前几天写了个SpringBootShiro的Dem ...
- VMware Workstation CentOS7 Linux 学习之路(4)--守护服务(Supervisor)
目前存在三个问题 问题1:ASP.NET Core应用程序运行在shell之中,如果关闭shell则会发现ASP.NET Core应用被关闭,从而导致应用无法访问,这种情况当然是我们不想遇到的,而且生 ...
- python 线程池实用总结
线程池的两张方法 submit 和map from concurrent.futures import ThreadPoolExecutor import time # def sayhello(a) ...
- item方法
class Person: def __init__(self, name, age): self.name = name self.age = age def __getitem__(self, i ...
- 轻松理解 Kubernetes 的核心概念
Kubernetes 迅速成为云环境中软件部署和管理的新标准. 与强大的功能相对应的是陡峭的学习曲线. 本文将提供 Kubernetes 的简化视图,从高处观察其中的重要组件,以及他们的关联. 硬件 ...
- 将jar包安装到本地仓库
通过cmd切换到apache maven 的bin目录 mvn install:install-file -DgroupId=com.antgroup.zmxy -DartifactId=zmxy-s ...