python机器学习——正则化
我们在训练的时候经常会遇到这两种情况:
1、模型在训练集上误差很大。
2、模型在训练集上误差很小,表现不错,但是在测试集上的误差很大
我们先来分析一下这两个问题:
对于第一个问题,明显就是没有训练好,也就是模型没有很好拟合数据的能力,并没有学会如何拟合,可能是因为在训练时我们选择了较少的特征,或者是我们选择的模型太简单了,不能稍微复杂的拟合数据,我们可以通过尝试选取更多的特征、增加一些多项式特征或者直接选用非线性的较复杂的模型来训练。
对于第二个问题,可以说是第一个问题的另外一个极端,就是模型对训练集拟合的太好了,以至于把训练集数据中的那些无关紧要的特征或者噪音也学习到了,导致的结果就是当我们使用测试集来评估模型的泛化能力时,模型表现的很差。打个不恰当比方就是你平时把作业都背下来了,但是其实你并没有学会如何正确解题,所以遇到考试就考的很差。解决方法就是增加训练集的数据量或者减少特征数量来尝试解决。
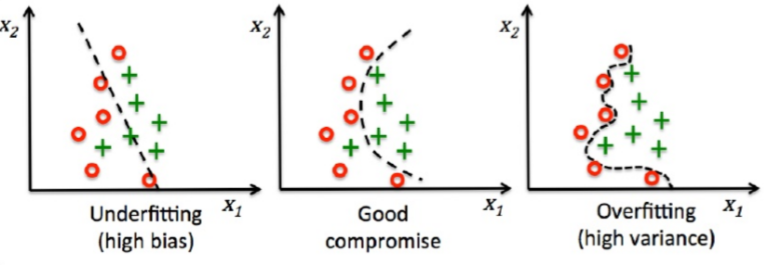
第一个问题我们叫做欠拟合(underfitting),第二个问题我们叫做过拟合(overfitting)
这两个问题还存在一种解决方法,就是我接下来要说的正则化。
我们之前说模型学习的过程也就是调整权重参数的过程,通过训练集中的数据来将模型的权重参数调整到一个使得损失函数最小的值。
对于一个分布较复杂的样本,如果训练得到的权重参数维度太少或者参数过小,也就是特征项很少,一些重要的特征没有起到作用,那么这条拟合曲线就会变得很简单,我们看上图的欠拟合图像,里面的拟合曲线是一条直线,这就是权重参数维度太少的结果。而如果权重参数维度过多或者参数过大,导致拟合曲线过于复杂,如上图的过拟合图像,拟合曲线可以完美的将两类不同的样本点区分开,但是我们也可以看出这条曲线很复杂,权重参数的项数一定很多。
现在进入正题,对于正则化,我们常见的形式是L2正则:
\[
\frac \lambda 2\lVert w \lVert^2 = \frac \lambda 2 \sum_{j=1}^m{w_j^2}
\]
这里的
\[
\lambda
\]
就是正则化系数。
我们将正则项直接添加到损失函数后即可使用,比如对于逻辑回归模型,带有L2正则项的损失函数为:
\[
J(w)=\sum_{i=1}^n\left[-y^{(i)}log(\phi(z^{(i)}))-(1-y^{(i)})log(1-\phi(z^{(i)}))\right] + \frac \lambda 2\lVert w \lVert^2
\]
我们通过控制正则化系数来控制权重参数的大小。一般正则化用于解决模型过拟合的问题,我们的训练目标是为了使损失函数最小,但是如果权重参数过大会导致过拟合,模型泛化能力下降,那么为了解决这个问题,将正则项加到损失函数后面,组成一个新的损失函数,为了最小化这个新的损失函数,我们在训练过程中不仅要使得误差小,还要保证正则项不能太大,于是如果我们选择一个较大的正则化系数,那么为了保证正则项不能太大,就会使得权重参数变小,这也就是我们的最终目的:在保证误差不大的情况下,使得权重参数也不能太大,缓解了过拟合问题。正则化系数越大,正则化越强,权重参数越小。
所以对于欠拟合的模型,我们也可以尝试减小正则化系数来增大权重参数,而对于过拟合模型,我们尝试增大正则化系数来减小权重参数。
python机器学习——正则化的更多相关文章
- Python机器学习中文版
Python机器学习简介 第一章 让计算机从数据中学习 将数据转化为知识 三类机器学习算法 第二章 训练机器学习分类算法 透过人工神经元一窥早期机器学习历史 使用Python实现感知机算法 基于Iri ...
- Python机器学习中文版目录
建议Ctrl+D保存到收藏夹,方便随时查看 人工智能(AI)学习资料库 Python机器学习简介 第一章 让计算机从数据中学习 将数据转化为知识 三类机器学习算法 第二章 训练机器学习分类算法 透过人 ...
- Python机器学习笔记:sklearn库的学习
网上有很多关于sklearn的学习教程,大部分都是简单的讲清楚某一方面,其实最好的教程就是官方文档. 官方文档地址:https://scikit-learn.org/stable/ (可是官方文档非常 ...
- Python机器学习笔记:不得不了解的机器学习面试知识点(1)
机器学习岗位的面试中通常会对一些常见的机器学习算法和思想进行提问,在平时的学习过程中可能对算法的理论,注意点,区别会有一定的认识,但是这些知识可能不系统,在回答的时候未必能在短时间内答出自己的认识,因 ...
- Python机器学习笔记:不得不了解的机器学习知识点(2)
之前一篇笔记: Python机器学习笔记:不得不了解的机器学习知识点(1) 1,什么样的资料集不适合用深度学习? 数据集太小,数据样本不足时,深度学习相对其它机器学习算法,没有明显优势. 数据集没有局 ...
- Python机器学习基础教程-第2章-监督学习之线性模型
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- 机器学习-正则化(岭回归、lasso)和前向逐步回归
机器学习-正则化(岭回归.lasso)和前向逐步回归 本文代码均来自于<机器学习实战> 这三种要处理的是同样的问题,也就是数据的特征数量大于样本数量的情况.这个时候会出现矩阵不可逆的情况, ...
- 《Python机器学习及实践:从零开始通往Kaggle竞赛之路》
<Python 机器学习及实践–从零开始通往kaggle竞赛之路>很基础 主要介绍了Scikit-learn,顺带介绍了pandas.numpy.matplotlib.scipy. 本书代 ...
- python机器学习笔记:EM算法
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域的基础,比如隐式马尔科夫算法(HMM),LDA主题模型的变分推断算法等等.本文对于E ...
随机推荐
- KMP 和 扩展KMP
KMP:在主串S中找子串T的位置KMP算法的时间复杂度O(|S|+|T|). #define maxn 1000 char s[maxn],t[maxn];//s为主串,t为子串 int net[ma ...
- 【Java基础总结】泛型
泛型实现了参数化类型的概念,使代码可以应用于多种类型. 1. 泛型类 声明的泛型类型静态方法不能使用 class Tools<T>{ private T t; public void se ...
- DevOps is Hard、DevSecOps is Even Harder . --- Enterprise Holdings
Enterprise Holdings. 的IT团队超过2000人,在2018年的演讲中介绍了Enterprise Holdings的DevOps是如何转型的.我们通过打造一个不只包涵了pipelin ...
- C++Primer第五版 6.1节练习
练习6.1:实参和形参的区别是什么? 通俗解释: 实参是形参的初始值.编译器能以任意可行的顺序对实参求值.实参的类型必须与对应的形参类型匹配. 详解1) 形参变量只有在函数被调用时才会分配内存,调用结 ...
- c++ 贪心讲解大礼包
贪心是什么? 它其实类似一种思想 就是总问题可以分成许多的子问题 子问题的最优解可以直接推出整个问题 它和动态规划有一定的不同之处 动态规划不能由子问题的最优解推出整个问题的最优解 所以你看都要有一个 ...
- cogs 2109. [NOIP 2015] 运输计划 提高组Day2T3 树链剖分求LCA 二分答案 差分
2109. [NOIP 2015] 运输计划 ★★★☆ 输入文件:transport.in 输出文件:transport.out 简单对比时间限制:3 s 内存限制:256 MB [题 ...
- AVR单片机教程——小结
本文隶属于AVR单片机教程系列. 第一期挺让我失望的,是我太菜,没有把想讲的都讲出来.经常写了很多,然后一点一点删掉,最后就没多少了. 而且感觉难度不合适,处于很尴尬的位置.讲得简单,难的丢给库, ...
- python 封装底层实现原理
事实上,python封装特性的实现纯属"投机取巧",之所以类对象无法直接调用私有方法和属性,是因为底层实现时,python偷偷改变了它们的名称. python在底层实现时,将它们的 ...
- 高通量计算框架HTCondor(一)——概述
目录 1. 正文 2. 目录 3. 参考 4. 相关 1. 正文 HTCondor是威斯康星大学麦迪逊分校构建的分布式计算软件和相关技术,用来处理高通量计算(High Throughput Compu ...
- Hystrix 监控数据聚合 Turbine【Finchley 版】
原文地址:https://windmt.com/2018/04/17/spring-cloud-6-turbine/ 上一篇我们介绍了使用 Hystrix Dashboard 来展示 Hystrix ...