阿里巴巴大数据产品最新特性介绍--机器学习PAI
以下内容根据演讲视频以及PPT整理而成。
本次分享主要围绕以下五个方面:
- PAI产品简介
- 自定义算法上传
- 数加智能生态市场
- AutoML2.0自动调参
- AutoLearning自动学习
一、PAI产品简介与功能发展
1. PAI-Studio
在PAI的架构图中,最下层的是PAI的计算框架和数据资源。PAI可支持MaxCompute、OSS、HDFS和NAS等多种数据资源。在数据资源和多种计算框架基础之上,诞生出了PAI的最早形态:PAI-Studio——可视化建模实验平台,Studio中包括了两百多种算法,覆盖了数据预处理,特征工程,模型训练,评估预测等全链路的实验流程操作。用户可在PAI-Studio中以拖拽的方式构建实验,而无需复杂的操作。此外,PAI内置了鲲鹏计算框架,可支持百亿特征,百亿样本的超大规模矩阵训练。在最初建立过程中,PAI-Studio的定位目标为中级的算法工程师,即一个不需要很高的技术门槛就可以上手使用的算法平台。有了可视化建模Studio,PAI就可以拥有为用户提供业务支持,如构建推荐系统、金融风控、疾病预测或新闻分类等的能力。

2. PAI-EAS
然而,从Studio中算法和实验的构建,到真正成为用户可用的模型服务,其中间还存在一个gap,即如何将模型部署为在线服务。用户一般需要耗费较大的精力在此之上。为了解决这个问题,PAI平台随后推出了PAI-EAS模型在线服务功能,为用户提供EAS在线服务的一键部署功能,大大简化操作,连接模型构建与生产服务。除了一键部署,PAI-EAS模型在线服务功能还支持版本控制、蓝绿部署和弹性扩缩容等特性功能。通过PAI-EAS模型在线服务,用户可以方便的进行构建实验,并将模型进行在线部署,最后应用到实际业务当中。
3. PAI-DSW
在PAI之后的发展过程中,出现了新的需求,即有的工程师希望在整个实验构建过程中有更大的自主发挥空间。为此,PAI推出了PAI-DSW版块,其特点是使用notebook进行建模,PAI-DSW内置了Jupyter的开发环境,继承了深度优化的TensorFlow,并且可以可视化编辑神经网络。由需求的初衷不难发现,PAI-Studio和PAI-DSW最大不同点就在于它为拥有更多算法背景技术的工程师提供更大的发挥空间,因此适合于高级的算法工程师。
4. PAI-AutoLearning
在解决了高级、中级算法工程师的需求之后, PAI又进一步推出了专门为初级算法工程师量身设计的全新PAI-AutoLearning功能(详细功能特性会在下文介绍)。继而,拥有不同的算法能力的工程师都可以通过PAI找到适合自己使用的产品类别。
5. 智能生态市场
通过以上PAI的功能版块,用户可以根据自身特点迅速找到适合自己的板块,并快速部署服务到业务中去,但这些都是需要用户自身来开发完成。随着AI行业应用的不断发展,如何让借助他方的能力、智慧,来快速解决自己的业务需求,又成为了一个新的问题解决思路。为此,PAI推出了——智能生态市场功能版块。用户可以在智能生态市场中寻找自己业务问题的解决方案(如模型、算法或者应用等),快速获取能力,避免了不必要的开发人力资源的耗费。反之,拥有对应技术的开发人员或公司,又可以在智能生态市场中一展才能,售卖发布商品,并获取相应回报及品牌。
二、自定义算法上传
自定义算法上传是PAI-Studio内的一个功能。机器学习在实际的应用过程当中,有千万种与行业结合的可能性和应用场景,用户会有一些个性化的需求。尽管PAI-Studio为用户提供了两百多种算法组件,但依然不能满足每一个用户的每一个需求。通过自定义算法上传功能,用户可以开发自己的算法组件,方便后续使用。
- 自定义算法上传特性
自定义算法上传包含三个特性。首先,自定义算法上传功能兼容Spark生态,支持Spark和PYSpark框架,在这个框架下用户可以任意开发自己所需要的算法。其次,自定义算法上传功能支持便捷发布。为了避免在自定义算法发布过程中,花费的精力大于最终带来的效率收益,PAI在自定义算法上传功能设计的过程当中,着重强调便捷发布,提供分钟级的算法发布体验。自定义算法上传第三个特性是可视化配置。从上传算法包,到真实的拖拉拽PAI-Studio中可使用组件,其中还包含一个步骤,既配置组件的算法参数以及相关配置。PAI为用户提供了可视化的在线操作配置的方式。

三、数加智能生态市场
1.智能生态市场角色
智能生态市场是大数据和AI领域的一个淘宝平台,其最大的作用是连接了开发方和业务方。在此之前,开发方有自己的能力和技术,业务方有需求和想要解决的问题。但两方一直没有办法很好的连接在一起,通过数加智能生态市场平台,将开发方的技术和业务方的需求进行对接,两方都可以通过平台获取利益。首先,开发方可以打通产品快速发布售卖,收获品牌效益,同时掌握市场动态需求。另外,业务方可以通过智能市场更便捷的获取适合自己的业务解决方案。同时降低探索新业务的成本,还可以扩展基础事业,快速实现公司技术的优化。
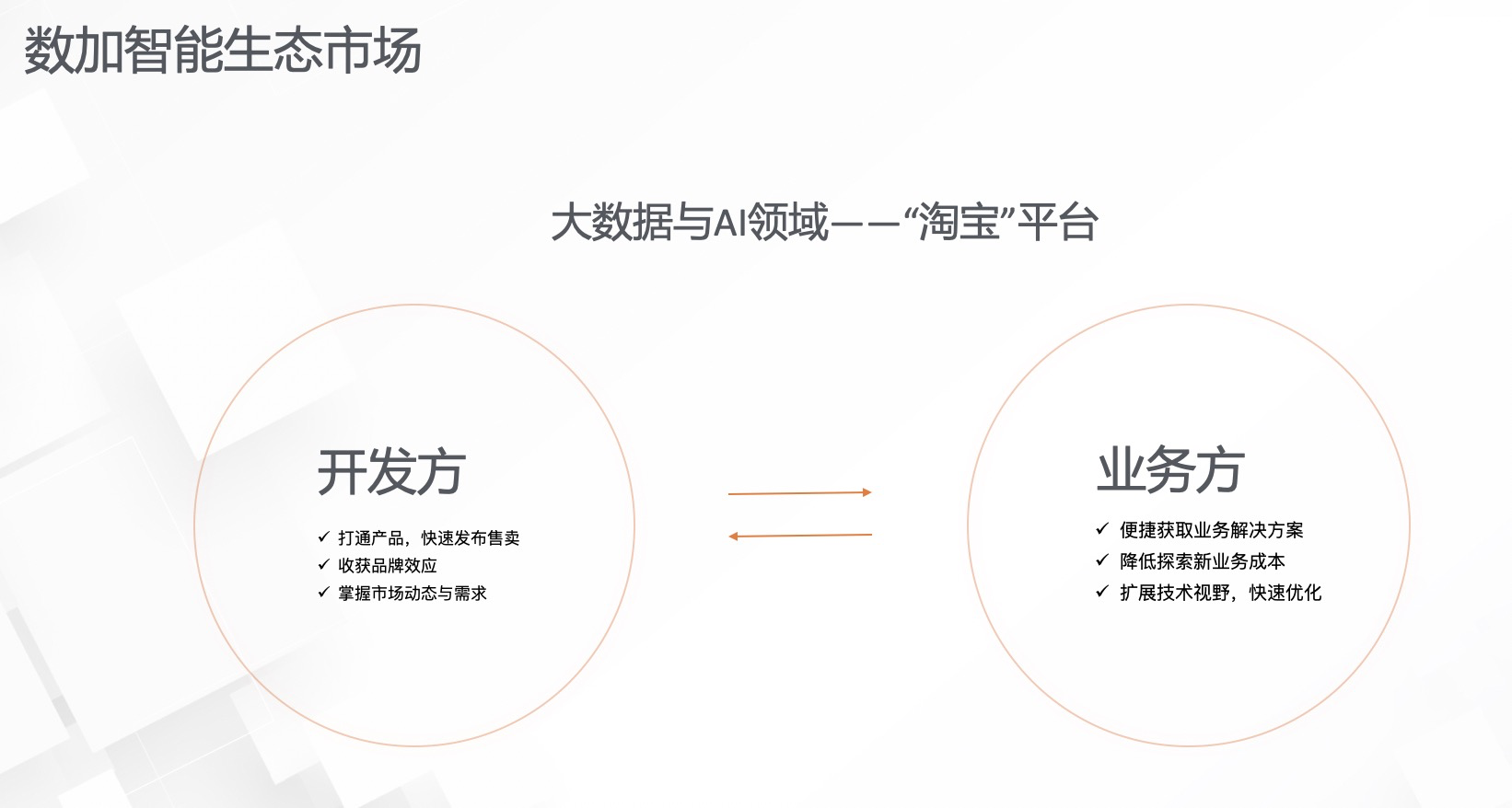
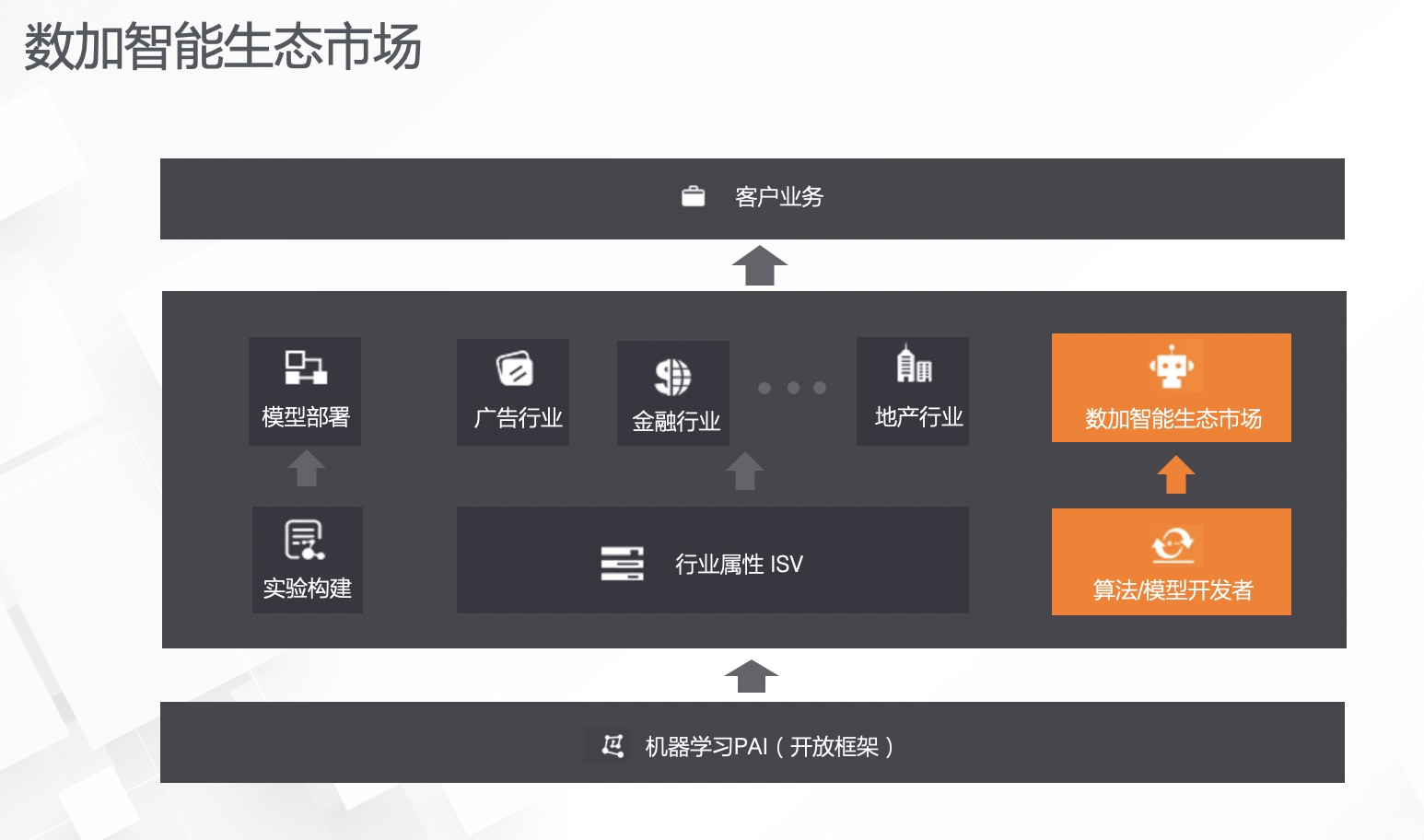
如下图,在智能生态市场链路出现以前,用户只有两种构建业务解决方案的途径,一个是通过自己使用机器学习PAI来开发,其中包括实验的构建、模型部署和应用等步骤;二是选择行业ISV,ISV通过在行业中的经验为客户构建出不同的,可部署在实际业务中的模型,解决客户的业务需求。但这两种方案的前者需要投入较大的人力成本,后者需要较大的财力成本。有了数加智能生态市场之后,用户可以选择第三条平衡人力和财力成本的新途径,通过向算法模型开发者购买最新的模型或者解决方案,解决自己的实际业务问题。这是加智能生态市场所建立的功能目标,以及它可以为客户和开发者带来的价值。
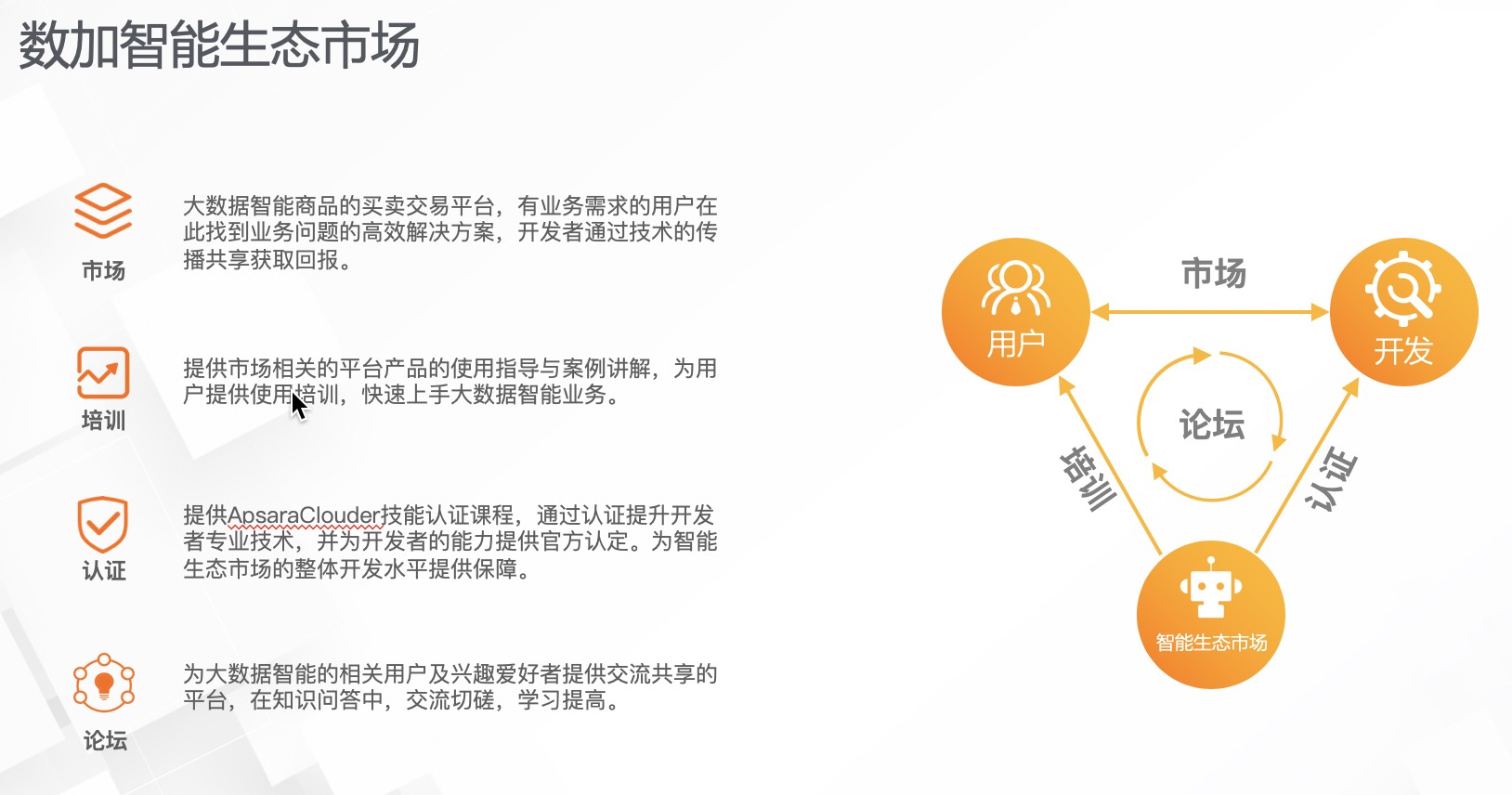
2. 数加智能生态市场的子版块
数加智能生态市场包括四大板块。首先,在市场板块中用户可以进行大数据智能商品的买卖交易。既有业务需求的用户可以找到业务问题的高效解决方案,开发者可以通过技术的传播和共享,获取回报和品牌效益。第二个板块是培训板块,培训板块可以提供市场相关平台的使用指导和案例讲解,为用户提供实用的培训,快速上手大数据的智能业务,实现快速入门。第三个板块是认证板块,主要面向开发者同学。在认证板块中开发者同学可以获取Apsara Clouder技能的认证证书,通过认证提升开发的专业技能,并获得官方资格的评定。第四个板块是论坛版块,大数据智能用户以及相关兴趣爱好者都可以在论坛相互交流,获取最新的前沿技术和知识。
通过以上四个板块,构建了一个有机生态圈。智能生态市场为用户提供培训,为开发的同学提供认证。用户和开发同学之间通过市场建立互相买卖的交易关系,并且获取各自的需求。同时三者之间可以构成一个论坛的有机生态。
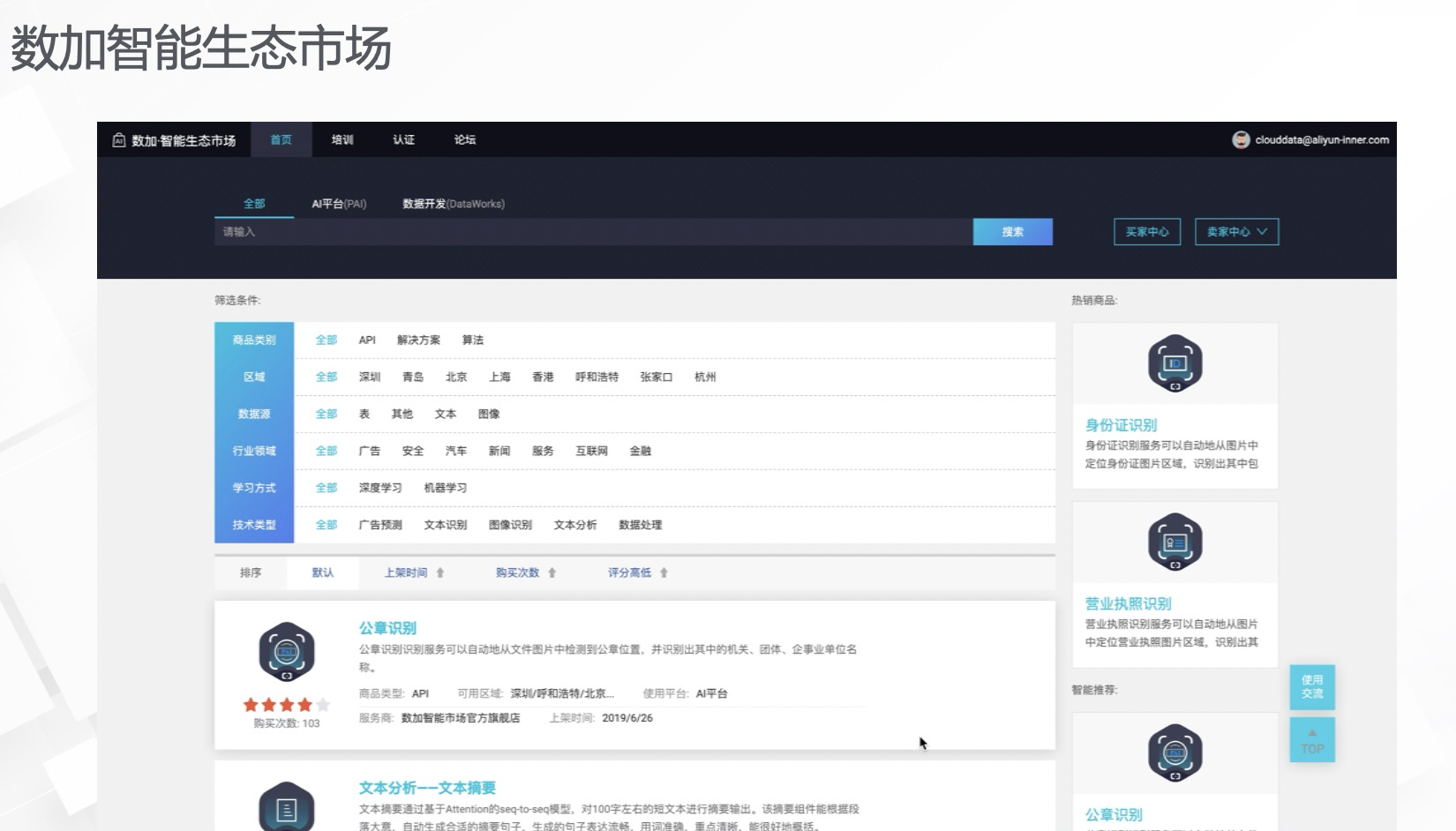
3. 商品发布流程简介
下图是数加智能生态市场主界面。开发者通过主界面进行卖家入驻,填写个人信息,提交审核。通过审核之后,卖家拥有了在市场上售卖商品的资格。卖家可以进行商品发布,首先选择商品的种类,如发布解决方案商品,输入商品名称,商品介绍以及来源渠道。在来源渠道里中填写商品的跳转链接,由于解决方案商品属于比较开放式的商品的类型,开发者可以发布自己相关的名片,方便更进一步的沟通和联系。此外,还可以在数加智能生态市场中发布算法商品。算法商品和自定义算法上传功能是相通的。自定义算法上传配置完之后有一个发布按钮,点击发布按钮就可以发布到数加智能生态市场。商品通过审核之后,可以点击上架操作,上架操作完成之后页面中生成一个商品的智能客服机器人,其中已经预置了商品的基本问答,在客户想要来了解商品信息时,可以通过智能客服机器人进行初步的商品信息获取,若智能客服机器人无法提供足够的信息量,还可以通过预留的钉钉号进行进一步的沟通联系。
四、AutoML2.0自动调参
1.AutoML2.0特性
AutoML自动调参功能是PAI-Studio中的核心功能。PAI-Studio可以进行可视化的建模操作,但模型构建好之后,如何进行参数调整,并达到最好的实验效果,是用户经常面临的问题。AutoML即以此为目的,解决实验的调参问题。AutoML2.0自动调参功能包含三大特性。首先是一键自动调参数,包括自动调整参数、模型评估和模型传导。此外,AutoML2.0支持七种调参算法,如GritSearch、Random Search、PBT、Gause、Evolutionary等常见的调参算法。实践证明,AutoML2.0可以帮助用户节省90%的工作量,大幅降低了用户在建立机器学习模型过程中所花费的时间以及人力成本。

2.自动调参实践示例
在这里,我们选择GBDT回归模型来进行调参,在自动调参的界面配置中选择数据的拆分比例,一部分数据用于训练模型,其余数据用于模型的评估。AutoML2.0现在可支持的七种调参方式,包括Gause、PBT、SAMPLE、随机搜索、方格搜索、自定义搜索以及Evolutionary优化调参方式。这七种调参方式已经涵盖了目前主流的调参方式。这里我们选择Evolutionary 优化调参方式,下面需要配置Evolutionary 优化调参方式所需要配置的搜索的样本数目,探索次数,收敛系数,定义参数范围。配置结束后,便会自动生成模型,示例中一共生成了11个模型,那如何从11个模型中选择最好的模型?自动调参页面中为用户提供了选择的标准,MAE,既通过MAE对生成的模型的质量高低进行排序,用户可以保存前几名模型,进行进一步的操作。
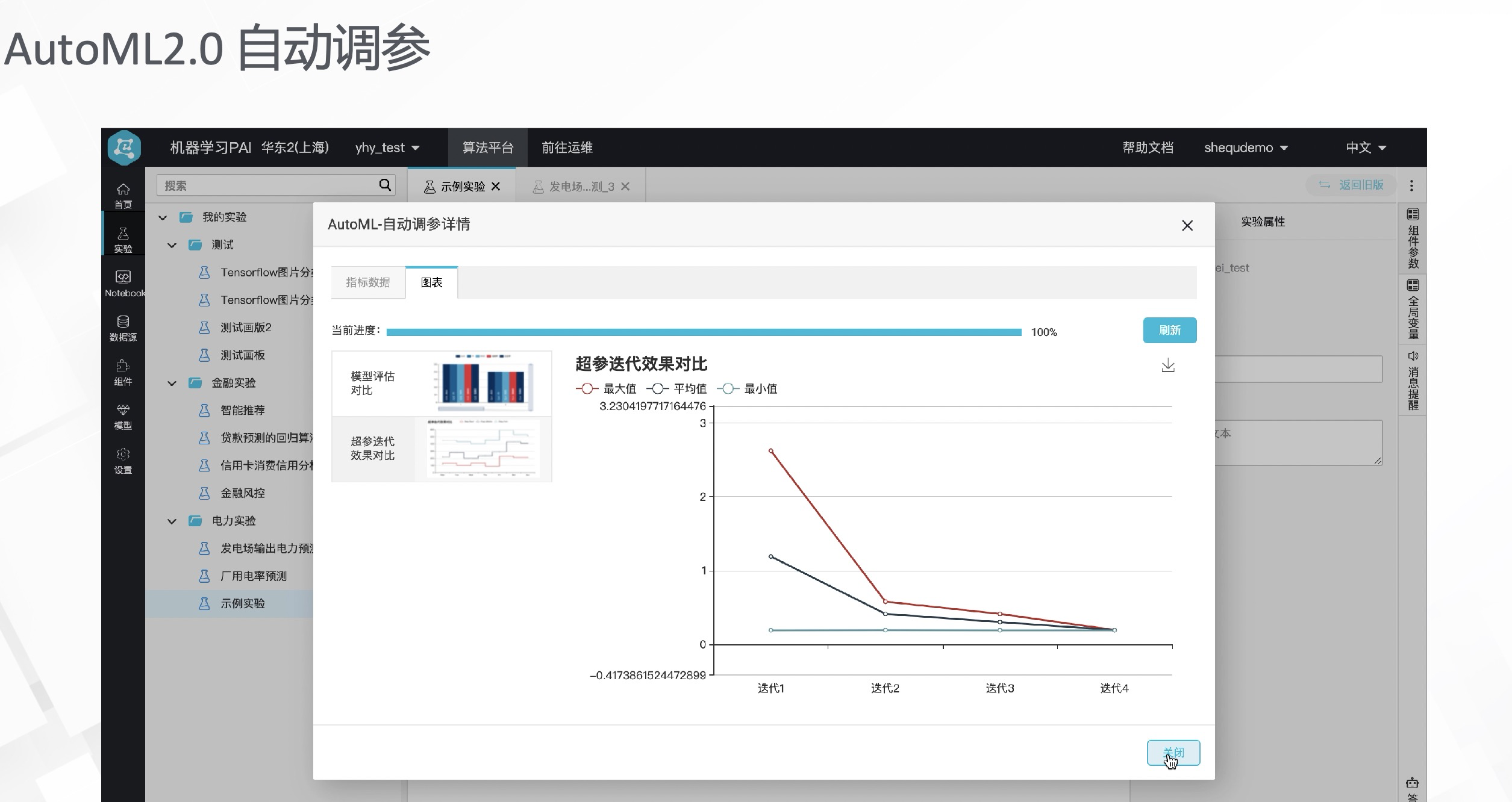
如下图,在自动调参详情页可以看到多次迭代之后,对模型效果的改善是非常直观的。随着迭代次数的逐步增加,模型的效果越来越好。纵坐标是MAE值,MAE值越低,代表模型的误差越低。随着迭代次数上升,模型的质量也越来越高,这证明了AutoML调参功能的有效性。
五、AutoLearning自动学习
1.AutoLearning特性
PAI-AutoLearning自动学习功能是PAI最新推出的功能之一。在AutoLearning自动学习功能出现之前,PAI中的PAI-Studio,PAI-DSW分别为中级算法工程师和高级算法工程师对应解决了他们的实验构建需求。而PAI-AutoLearning则通过提供小白级、零门槛的一个工具,解决了初级或入门级算法工程师的实验构建需求,使更多的人参与到机器学习,使用机器学习为自己的业务带来价值。AutoLearning自动学习功能有以下亮点。首先是零门槛使用,即功能开箱即用,对于小白同学特别友好。其次是最低基于5张图片就可进行一次学习。通过强大的迁移学习框架,PAI-AutoLearning可实现少量数据的有效学习,学习训练的结果依然非常出色。第三个亮点是AutoLearning实现了一站式解决方案。一站式包括从数据标注、模型训练、模型部署的整个过程,帮助小白用户也可以快速地入门机器学习的实际应用。

2. AutoLearning自动学习使用实例
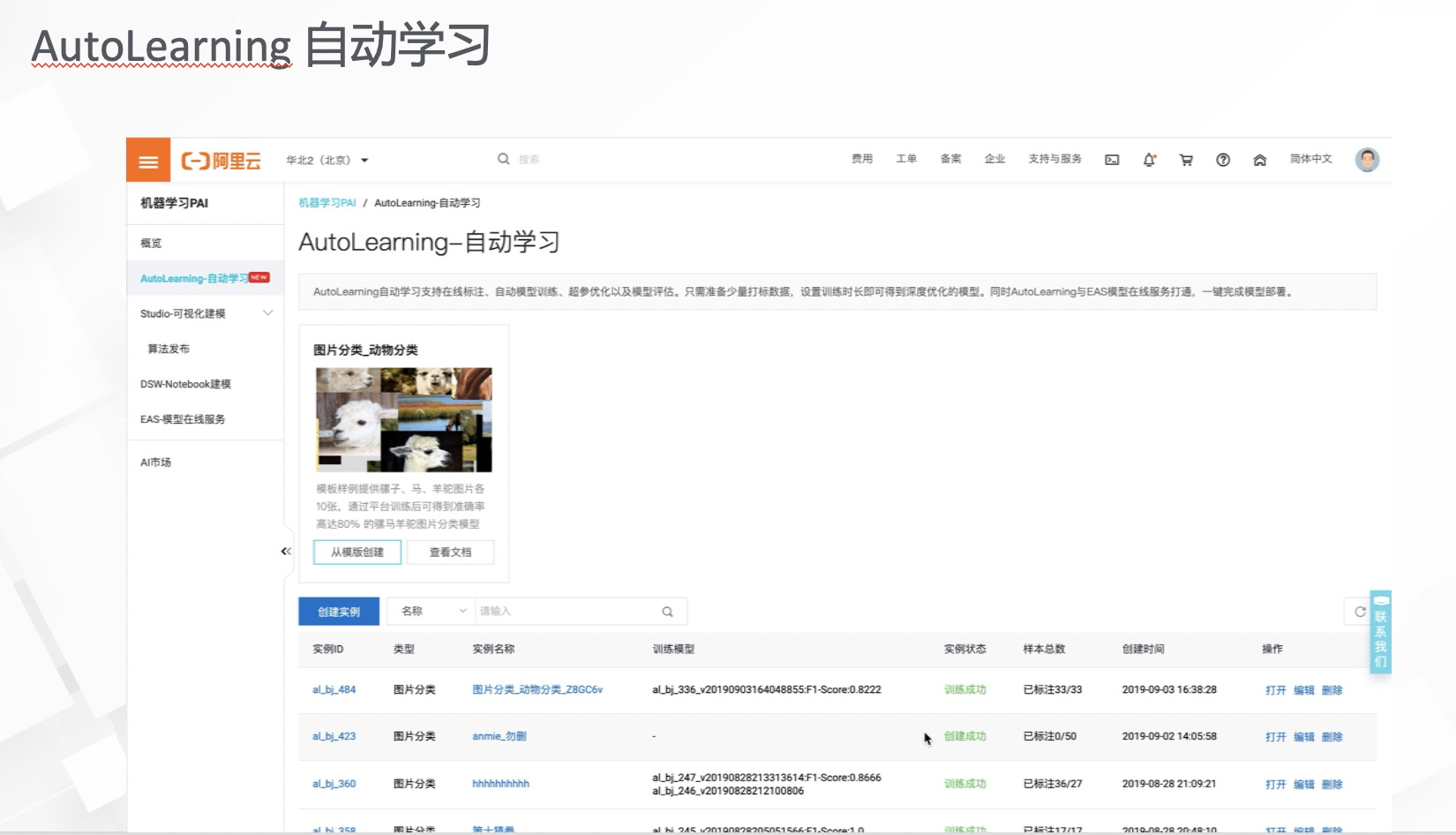
在AutoLearning自动学习功能板块,点击从模板创建。模板创建是适用于新手快速入门的一个功能体验,用户可以迅速的体验到整个自动学习的功能特性。页面中预置好了实验中需要的训练数据,如图片分类实验,数据集中包含不同的动物种类,通过训练可以生成准确识别动物种类的深度学习的模型。
首先,在深度学习训练之前需要对深度学习算法提供有效的数据。有效数据需要对数据进行标注。因此,第一步是对数据的打标,AutoLearning自动学习板块内置集成数据标注功能,帮助用户快速的进入数据打标。第一步是在图片中添加标签,动物种类包括羊驼、马和骡子,快速勾选同一类的动物,将其标记为羊驼,马或骡子。在开始训练页面中输入训练时长,训练时长是决定最终模型训练效果的一个关键的因素,训练的时间则越长模型效果越好。Auto Learning板块特色是可以在短时间内快速训练出较为精准的模型,只需十分钟就可以训练出一个训练分类效果不错的模型。相比于传统深度学习模型训练这点的改进非常明显。
此外,开始训练页面中另外一个选项是增量训练。增量训练表示是否在原有的训练模型基础上继续进行进一步的训练。在模型训练及评估界面,可以看到训练好的模型结果,模型指标包括准确率、精准率,召回率值,表示模型对当前的训练结果的有效性程度。用户可以点击上传新的图片,检验模型预测性能。那么验证好的模型该如何运用到实际生产当中去呢,Auto Learn ing自动学习功能已一站式业务构建流程,用户在此界面可直接点击前往EAS部署就可以将模型部署为服务,应用到实际的生产中进行产出。
本文作者:弗洛仑
本文为云栖社区原创内容,未经允许不得转载。
阿里巴巴大数据产品最新特性介绍--机器学习PAI的更多相关文章
- MaxCompute 最新特性介绍 | 2019大数据技术公开课第三季
摘要:距离上一次MaxCompute新功能的线上发布已经过去了大约一个季度的时间,而在这一段时间里,MaxCompute不断地在增加新的功能和特性,比如参数化视图.UDF支持动态参数.支持分区裁剪.生 ...
- 大数据和Hadoop平台介绍
大数据和Hadoop平台介绍 定义 大数据是指其大小和复杂性无法通过现有常用的工具软件,以合理的成本,在可接受的时限内对其进行捕获.管理和处理的数据集.这些困难包括数据的收入.存储.搜索.共享.分析和 ...
- 阿里大数据产品Dataphin上线公共云,将助力更多企业构建数据中台
日前,由阿里数据打造的智能数据构建与管理Dataphin,重磅上线阿里云-公共云,开启智能研发版本的公共云公测!在此之前,Dataphin以独立部署方式输出并服务线下客户,已助力多家大型客户高效自动化 ...
- 学习Hadoop+Spark大数据巨量分析与机器学习整合开发-windows利用虚拟机实现模拟多节点集群构建
记录学习<Hadoop+Spark大数据巨量分析与机器学习整合开发>这本书. 第五章 Hadoop Multi Node Cluster windows利用虚拟机实现模拟多节点集群构建 5 ...
- 【转】大数据以及Hadoop相关概念介绍
原博文出自于: http://www.cnblogs.com/xdp-gacl/p/4230220.html 感谢! 一.大数据的基本概念 1.1.什么是大数据 大数据指的就是要处理的数据是TB级别以 ...
- 大数据以及Hadoop相关概念介绍
一.大数据的基本概念 1.1.什么是大数据 大数据指的就是要处理的数据是TB级别以上的数据.大数据是以TB级别起步的.在计算机当中,存放到硬盘上面的文件都会占用一定的存储空间,例如: 文件占用的存储空 ...
- Hadoop学习总结(1)——大数据以及Hadoop相关概念介绍
一.大数据的基本概念 1.1.什么是大数据 大数据指的就是要处理的数据是TB级别以上的数据.大数据是以TB级别起步的.在计算机当中,存放到硬盘上面的文件都会占用一定的存储空间,例如: 文件占用的存储空 ...
- Windows Azure上的大数据服务: HDInsight的介绍
这个视频介绍了目前非常流行的大数据处理框架Hadoop的Windows Azure上的实现:HDInsight,以及利用MapReduce来对大数据进行分析,利用Hive进行查询,利用客户端Power ...
- 【大数据技术】HBase介绍
1.HBase简介1.1 Hbase是什么HBase是一种构建在HDFS之上的分布式.面向列.多版本.非关系型的数据库,是Google Bigtable 的开源实现. 在需要实时读写.随机访问超大规模 ...
随机推荐
- c实现swap函数陷阱
swap函数陷阱 使用c实现一个交换两个数的函数,代码很简单: void swap(int *a, int *b) { *a ^= *b; *b ^= *a; *a ^= *b; } 只有3行代码,且 ...
- Day15:Python 【模块】及__name__:
什么是模块: 在Python中,随着这代码的撰写,代码越来越长,所以产生了,模块这个概念,模块是什么?模块就是一个.py文件,在撰写代码时,我们把不同的功能的代码封装到一个.py文件里,用得时候导入 ...
- Xpath-Assertion断言
- web项目中使用的协议
DNS协议 1.DNS协议的作用是将域名解析为IP,网络上的每个站点的位置是用IP来确定的,访问一个网站首先就要知道它的IP,不过数据组成的IP记起来不方便,所以就使用域名来代替IP,由于IP和域名的 ...
- js 阻止事件
event.stopPropagation();//阻止事件冒泡 ,可阻止父类事件的发生 event.preventDefault();//阻止默认行为 如A标签
- ubuntu 权限不够,解决办法,无法获得锁 /var/lib/dpkg/lock - open (11: 资源暂时不可用)
终端执行 sudo passwd root输入root 新密码执行命令 nano /usr/share/lightdm/lightdm.conf.d/50-ubuntu.conf末行添加 gr ...
- 关于jquery ajax项目总结
$.ajax({ url:"../action/BorrowAction.php?action=oready", async:true,//异步请求 ...
- Neo4j 因果集群搭建及neo4j-java-driver连接
搭建Neo4j因果集群 1.下载企业版,当前是3,5,9版本 https://neo4j.com/download-center/#enterprise 2.配置,三个核心集群为例 配置文件,conf ...
- Linux命令速查手册(第2版)学习
第1章.需要了解的命令行相关事项 表1-1 如何在文件名字符中使用特殊字符 字符 建议 / 绝不使用.不能转义 \ 必须转义.避免使用 _ 绝不能作为文件或目录名的第一个字符 [] 必须转义.避免使用 ...
- hdu多校第二场 1005 (hdu6595) Everything Is Generated In Equal Probability
题意: 给定一个N,随机从[1,N]里产生一个n,然后随机产生一个n个数的全排列,求出n的逆序数对的数量,加到cnt里,然后随机地取出这个全排列中的一个非连续子序列(注意这个子序列可以是原序列),再求 ...