scrapy的使用-LinkExtractor
背景:
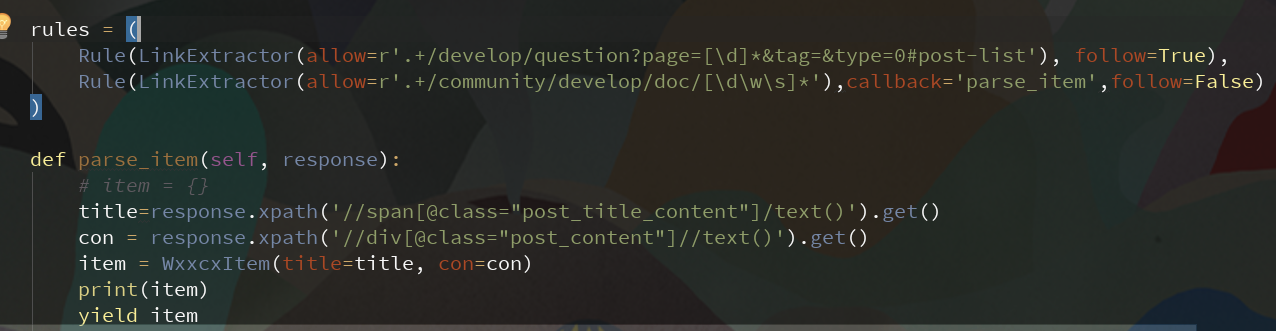
在爬取网站信息是需要获取特定标签下的某些内容,就需要获取这些标签下的链接,如果获取每一个,在通过这个获取它下面的信息,这样效率会很低,时间复杂度O(n^2),但如果先获取链接,再获取内容,则时间复杂度为O(n)+O(n),每次执行完深度为2,则时间复杂度为O(n).效率会明显提高,非常适合整站爬取。
allow() #allow(正则表达式(或的列表)) - 一个单一的正则表达式(或正则表达式列表),(绝对)urls必须匹配才能提取。如果没有给出(或为空),它将匹配所有链接。
deny() #deny(正则表达式或正则表达式列表) - 一个正则表达式(或正则表达式列表),(绝对)urls必须匹配才能排除(即不提取)。它优先于allow参数。如果没有给出(或为空),它不会排除任何链接。
allow_domains() #allow_domains(str或list) - 单个值或包含将被考虑用于提取链接的域的字符串列表
deny_domains() #deny_domains(str或list) - 单个值或包含不会被考虑用于提取链接的域的字符串列表
deny_extensions() #deny_extensions(list) - 包含在提取链接时应该忽略的扩展的单个值或字符串列表。如果没有给出,它将默认为IGNORED_EXTENSIONS在scrapy.linkextractors包中定义的 列表 。
restrict_xpaths() # restrict_xpaths(str或list) - 是一个XPath(或XPath的列表),它定义响应中应从中提取链接的区域。如果给出,只有那些XPath选择的文本将被扫描链接。参见下面的例子。
restrict_css() # restrict_css(str或list) - 一个CSS选择器(或选择器列表),用于定义响应中应提取链接的区域。有相同的行为restrict_xpaths。 标签(str或list) - 标签或在提取链接时要考虑的标签列表。默认为。('a', 'area')
attrs() # attrs(list) - 在查找要提取的链接时应该考虑的属性或属性列表(仅适用于参数中指定的那些标签tags )。默认为('href',)
canonicalize() # canonicalize(boolean) - 规范化每个提取的url(使用w3lib.url.canonicalize_url)。默认为True。
unique() # unique(boolean) - 是否应对提取的链接应用重复过滤。
process_value() # process_value(callable) -
接收从标签提取的每个值和扫描的属性并且可以修改值并返回新值的函数,或者返回None以完全忽略链接。如果没有给出,process_value默认为。lambda x: x

scrapy的使用-LinkExtractor的更多相关文章
- scrapy之使用LinkExtractor提取链接
一.概述: 在页面含有少量链接时,使用selector来提取信息就可以,但如果链接特别多时,就需要用LinkExtractor来提取. 二.LinkExtractor构造器的各个参数: 1.allow ...
- scrapy中使用LinkExtractor提取链接
le = LinkExtractor(restrict_css='ul.pager li.next') links = le.extract_links(response) 使用LinkExtra ...
- Scrapy爬取自己的博客内容
python中常用的写爬虫的库有urllib2.requests,对于大多数比较简单的场景或者以学习为目的,可以用这两个库实现.这里有一篇我之前写过的用urllib2+BeautifulSoup做的一 ...
- 爬虫的入门以及scrapy
一.简介 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟 ...
- 教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http://www.xiaohuar.com/,让你体验爬取校花的成就感. Scr ...
- 爬虫之scrapy框架
解析 Scrapy解释 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓 ...
- 爬虫--Scrapy
Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设 ...
- scrapy 爬取自己的博客
定义项目 # -*- coding: utf-8 -*- # items.py import scrapy class LianxiCnblogsItem(scrapy.Item): # define ...
- 爬虫入门scrapy
Python之路[第十九篇]:爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用 ...
随机推荐
- P1493 分梨子
P1493 分梨子 题目描述 Finley家的院子里有棵梨树,最近收获了许多梨子.于是,Finley决定挑出一些梨子,分给幼稚园的宝宝们.可是梨子大小味道都不太一样,一定要尽量挑选那些差不多的梨子分给 ...
- O(n)时间复杂度查找数组第二大元素
分析:要求O(n)时间复杂度,不能用排序.可以设置两个临时变量分别保存当前最大值以及当前第二大的值,然后遍历数组,不断更新最大值和第二大的数值. 代码: bool findSec(vector< ...
- (52) C# 串口通讯
一.串口通讯基本参数 1.波特率:每秒传输n个多少个二进制位. 例如 9600 b/s = 1200 B/s= 1.172KB/S 2.传输数据格式 数据格式由起始位(start bit).数据位 ...
- HCW 19 Team Round (ICPC format) H Houston, Are You There?(极角排序)
题目链接:http://codeforces.com/gym/102279/problem/H 大致题意: 你在一个定点,你有个长度为R的钩子,有n个东西在其他点处,问你能勾到的东西的数量是多少? 思 ...
- JDK8新特性之Optional
Optional是什么 java.util.Optional Jdk8提供Optional,一个可以包含null值的容器对象,可以用来代替xx != null的判断. Optional常用方法 of ...
- Neo4j:Index索引
Indexing in Neo4j: An Overview by Stefan Armbruster · Jan. 06, 14 · Java Zone Neo4j是一个图数据库,在做图的检索时,用 ...
- pytest--fixture之参数化
场景:测试用例执行时,有的用例需要登陆才能执行,有些用例 不需要登陆.setup和teardown无法满足.fixture可以.默认 scope(范围)function • 步骤: 1. 导入pyte ...
- Install .NET Core Runtime on Linux Ubuntu 16.04 x64
原文链接https://www.microsoft.com/net/download/linux-package-manager/ubuntu16-04/runtime-current nstall ...
- OAuth2.0实例说明
OAuth2.0 详细实列+Word文档清晰说明 实例下载地址:https://files.cnblogs.com/files/liyanbofly/OAuth2.0%E5%AE%9E%E4%BE%8 ...
- Linux 父子进程实现复制文件内容到另一个文件内
1. 子进程先拷贝前一半 ,父进程一直阻塞到子进程拷贝完再拷贝后一半 /* 子进程先拷贝前一半文件,父进程先阻塞等待子进程拷贝完前一半内容, * 然后父进程在拷贝,后一半内容 * */ #includ ...