机器学习(ML)十六之目标检测基础
目标检测和边界框
在图像分类任务里,我们假设图像里只有一个主体目标,并关注如何识别该目标的类别。然而,很多时候图像里有多个我们感兴趣的目标,我们不仅想知道它们的类别,还想得到它们在图像中的具体位置。在计算机视觉里,我们将这类任务称为目标检测(object detection)或物体检测。
目标检测在多个领域中被广泛使用。例如,在无人驾驶里,我们需要通过识别拍摄到的视频图像里的车辆、行人、道路和障碍的位置来规划行进线路。机器人也常通过该任务来检测感兴趣的目标。安防领域则需要检测异常目标,如歹徒或者炸弹。
边界框
在目标检测里,我们通常使用边界框(bounding box)来描述目标位置。边界框是一个矩形框,可以由矩形左上角的x和y轴坐标与右下角的x和y轴坐标确定。我们根据坐标信息来定义图中物体的边界框。图中的坐标原点在图像的左上角,原点往右和往下分别为x轴和y轴的正方向。
- 在目标检测里不仅需要找出图像里面所有感兴趣的目标,而且要知道它们的位置。位置一般由矩形边界框来表示。
锚框
目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边缘从而更准确地预测目标的真实边界框(ground-truth bounding box)。不同的模型使用的区域采样方法可能不同。这里我们介绍其中的一种方法:它以每个像素为中心生成多个大小和宽高比(aspect ratio)不同的边界框。这些边界框被称为锚框(anchor box)。我们将在后面基于锚框实践目标检测。
生成多个锚框

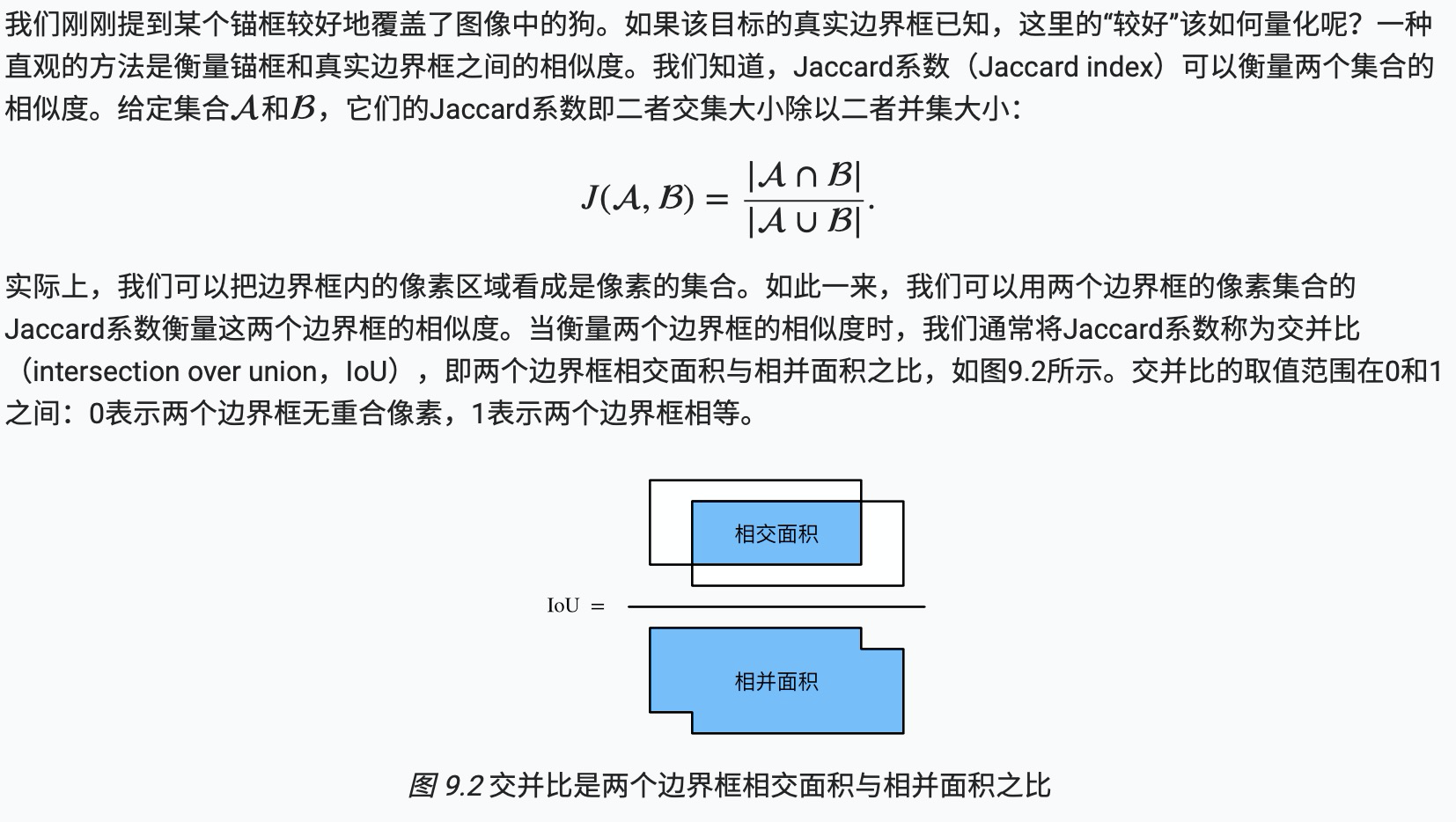
交并比
标注训练集的锚框

输出预测边界框
在模型预测阶段,我们先为图像生成多个锚框,并为这些锚框一一预测类别和偏移量。随后,我们根据锚框及其预测偏移量得到预测边界框。当锚框数量较多时,同一个目标上可能会输出较多相似的预测边界框。为了使结果更加简洁,我们可以移除相似的预测边界框。常用的方法叫作非极大值抑制(non-maximum suppression,NMS)。
我们来描述一下非极大值抑制的工作原理。对于一个预测边界框B,模型会计算各个类别的预测概率。设其中最大的预测概率为p,该概率所对应的类别即B的预测类别。我们也将p称为预测边界框B的置信度。在同一图像上,我们将预测类别非背景的预测边界框按置信度从高到低排序,得到列表L。从L中选取置信度最高的预测边界框B1作为基准,将所有与B1的交并比大于某阈值的非基准预测边界框从L中移除。这里的阈值是预先设定的超参数。此时,L保留了置信度最高的预测边界框并移除了与其相似的其他预测边界框。 接下来,从L中选取置信度第二高的预测边界框B2作为基准,将所有与B2的交并比大于某阈值的非基准预测边界框从L中移除。重复这一过程,直到L中所有的预测边界框都曾作为基准。此时LL中任意一对预测边界框的交并比都小于阈值。最终,输出列表L中的所有预测边界框。
实践中,我们可以在执行非极大值抑制前将置信度较低的预测边界框移除,从而减小非极大值抑制的计算量。我们还可以筛选非极大值抑制的输出,例如,只保留其中置信度较高的结果作为最终输出。
- 以每个像素为中心,生成多个大小和宽高比不同的锚框。
- 交并比是两个边界框相交面积与相并面积之比。
- 在训练集中,为每个锚框标注两类标签:一是锚框所含目标的类别;二是真实边界框相对锚框的偏移量。
- 预测时,可以使用非极大值抑制来移除相似的预测边界框,从而令结果简洁。
机器学习(ML)十六之目标检测基础的更多相关文章
- [系统安全] 十六.PE文件逆向基础知识(PE解析、PE编辑工具和PE修改)
[系统安全] 十六.PE文件逆向基础知识(PE解析.PE编辑工具和PE修改) 文章来源:https://masterxsec.github.io/2017/05/02/PE%E6%96%87%E4%B ...
- 第三十三节,目标检测之选择性搜索-Selective Search
在基于深度学习的目标检测算法的综述 那一节中我们提到基于区域提名的目标检测中广泛使用的选择性搜索算法.并且该算法后来被应用到了R-CNN,SPP-Net,Fast R-CNN中.因此我认为还是有研究的 ...
- 第三十节,目标检测算法之Fast R-CNN算法详解
Girshick, Ross. “Fast r-cnn.” Proceedings of the IEEE International Conference on Computer Vision. 2 ...
- PYG5.4第十六期第一轮基础六题
1. HYWZ-dts音效大师破解https://www.chinapyg.com/thread-135090-1-1.html(出处: 飘云阁(PYG官方论坛) ) 2. HYWZ-LopeEdit ...
- (六)目标检测算法之YOLO
系列文章链接: (一)目标检测概述 https://www.cnblogs.com/kongweisi/p/10894415.html (二)目标检测算法之R-CNN https://www.cnbl ...
- SIGAI机器学习第十六集 支持向量机3
讲授线性分类器,分类间隔,线性可分的支持向量机原问题与对偶问题,线性不可分的支持向量机原问题与对偶问题,核映射与核函数,多分类问题,libsvm的使用,实际应用 大纲: 多分类问题libsvm简介实验 ...
- Andrew Ng-ML-第十六章-异常检测
1.问题动机 图1.飞机发动机检测例子 对飞机引擎的例子,如果选取了两个特征x1热量产生度,x2震动强度.并得到如下的图,如果有一个新的引擎来检测其是否正常,x_test,那么此时如果点落在和其他点正 ...
- 机器学习(十六)— LDA和PCA降维
一.LDA算法 基本思想:LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的.这点和PCA不同.PCA是不考虑样本类别输出的无监督降维技术. 我们要将数据在低维度上进行投影,投 ...
- 十六、python面向对象基础篇
面向对象基础: 在了解面向对象之前,先了解下变成范式: 编程范式是一类典型的编程风格,是一种方法学 编程范式决定了程序员对程序执行的看法 oop中,程序是一系列对象的相互作用 python支持多种编程 ...
随机推荐
- Burp Suite Professional 针对APP抓包篡改数据提交【安全】
Burp Suite 是用于攻击web 应用程序的集成平台,包含了许多工具.Burp Suite为这些工具设计了许多接口,以加快攻击应用程序的过程.所有工具都共享一个请求,并能处理对应的HTTP 消息 ...
- 通过ssh-copy-id免密码连接Linux主机
Login Raspberry Pi without passcode via ssh-copy-id Generate public key $ ssh-keygen -t rsa Upload p ...
- VSCode C语言编程(二)新建项目及编译
添加工作区: 把文件夹在工作区删除: 把HelloWorld模板文件夹解压到工作目录 模板下载(代码解释请看模板里的注释) 添加项目文件夹: 编辑器打开的文件必须与main.c同目录 点击右边编译图标 ...
- linux - 服务器性能评估
影响Linux服务器性能的因素 cpu 内存 磁盘IO 网络IO 系统性能评估标准 影响性能因素 好 坏 糟糕 CPU user% + sys%< 70% user% + sys%= 85% u ...
- hdu 6182A Math Problem(快速幂)
You are given a positive integer n, please count how many positive integers k satisfy kk≤nkk≤n. Inp ...
- 原生js实现拖拽功能
1. 给个div,给定一些样式 <div class="drag" style="left:0;top:0;width:100px;height:100px&quo ...
- vue加载单文件使用vue-loader报错
报错信息如下:ERROR in ./src/login.vue Module Error (from ./node_modules/vue-loader/lib/index.js): vue-load ...
- Gin_渲染
1. 各种数据响应格式 package main import ( "github.com/gin-gonic/gin" "github.com/gin-gonic/gi ...
- shell循环结构解析:for/while/case
1.for循环结构 for var in item1 item2 ... itemN do command1 command2 ... commandN done 例如,顺序输出当前列表中的数字: # ...
- The view or its master was not found or no view engine supports the searched locations
Error like:The view 'LoginRegister' or its master was not found or no view engine supports the searc ...