nodejs爬虫第一篇---> request、cheerio实现小爬虫
目标
- 抓取猫眼正在热映的电影页面的数据,使用的第三方模块 request、cheerio。
说明
- 有时候我们需要做一些项目或者demo,我们需要一些数据,我们就可以利用爬虫,爬取一些我们想要的数据。个人感觉挺有趣。需要安装 node。
request
- request是一个第三方的模块,封装了 http 模块,使我们发送 get、post等 请求更简洁。有几个重要的参数:
- url:请求的地址
- method:请求的方式
- function:回调函数,该函数也有三个参数:1、err 错误对象,2、response 响应对象,3、body 响应数据
- 安装
npm install request --save
//引入模块
const request = require('request')
//小试牛刀:向百度首页发送了一个get请求
const url = 'https://www.baidu.com/'
request(url, function (err, response, body) {
console.log(body)
})
cheerio
- 会用 jQuery,那么使用 cheerio就不会难了,cheerio 包括了 jQuery 核心的子集。cheerio 从jQuery库中去除了所有 DOM不一致性和浏览器尴尬的部分,几乎能够解析任何的 HTML 和 XML document,通过load方法传递 HTML document或者标签字符串的形式来加载返回 相应的对象,该对象可以对 HTML document或者标签进行操作。
- 安装
npm install request --save
const request = require('request')
const cheerio = require('cheerio')
//传递 HTML document
const url = 'https://www.baidu.com/'
request(url, function (err, response, body) {
//此时body即为 HTML documen
const $ = cheerio.load(body)
})
//传递标签字符串
const $ = cheerio.load('<div class="text">...</div>')
抓取数据
- 获取HTML document对象
const request = require('request')
const cheerio = require('cheerio')
function getMovies(url) {
return new Promise((resolve, reject) => {
request(url, function (err, response, body) {
//获取HTML document对象 即body参数
const $ = cheerio.load(body)
})
})
}
- 猫眼热映电影页面图片
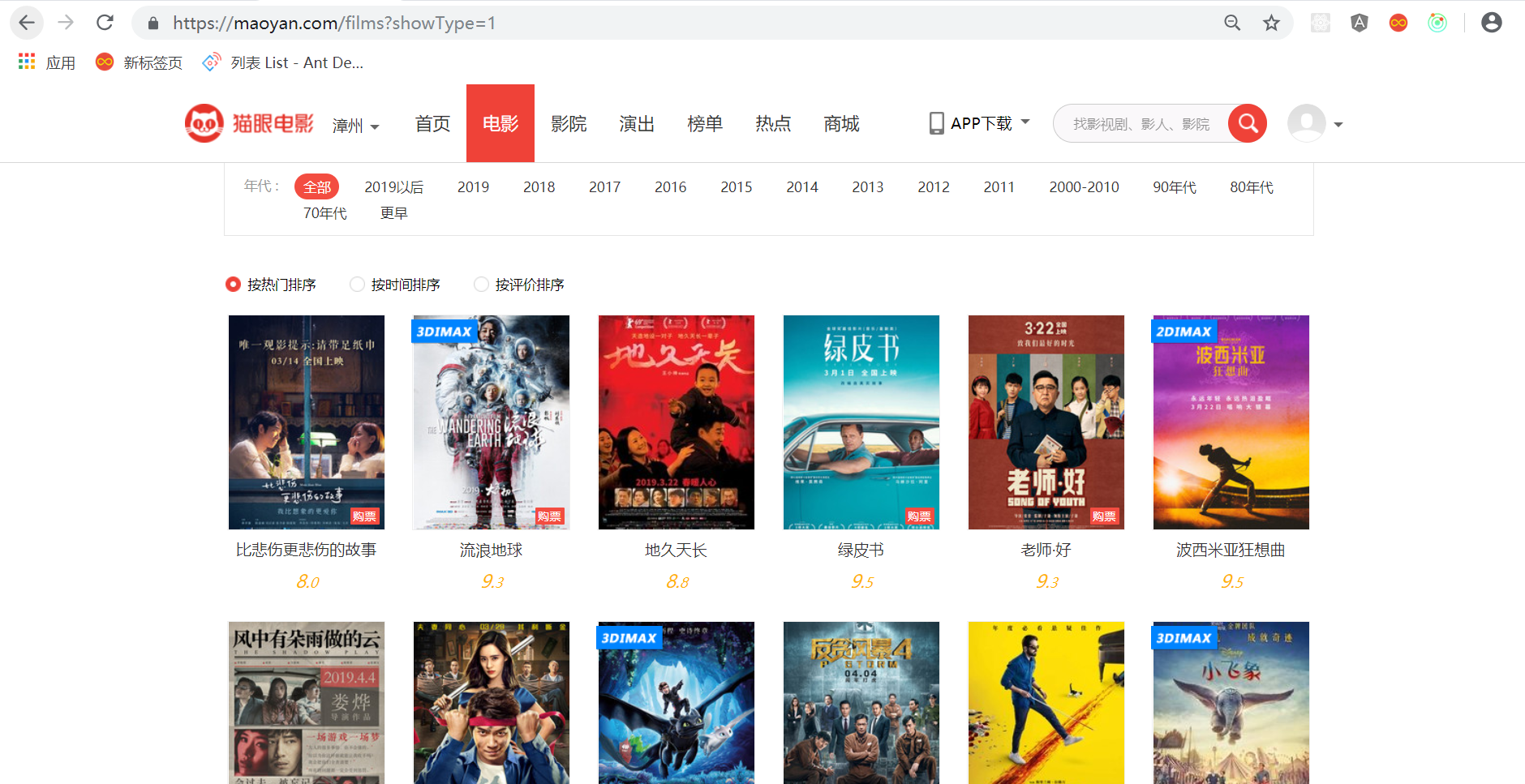
- HTML结构分析
- 通过分析 HTML的结构,可知道这些值可以通过下面的代码获取到
var item = $('.movie-list dd')
item.map(function (i, val) {
var movieObj = {}
//电影链接
movieObj.movieLink = $(val).find('.movie-poster').children('a').attr('href')
//电影图片
movieObj.moviePoster = $(val).find('.movie-item').children('img').last().attr('data-src')
//电影 名字
movieObj.movieTitle = $(val).find('.movie-item-title').children('a').text()
//电影评分
movieObj.movieDetail = $(val).find('.channel-detail-orange').text()
})

完整代码
const request = require('request')
const cheerio = require('cheerio')
function getMovies(url) {
var movieArr = []
return new Promise((resolve, reject) => {
request(url, function (err, response, body) {
var item = $('.movie-list dd')
item.map(function (i, val) {
var movieObj = {}
//电影链接
movieObj.movieLink = $(val).find('.movie-poster').children('a').attr('href')
//电影图片
movieObj.moviePoster = $(val).find('.movie-item').children('img').last().attr('data-src')
//电影 名字
movieObj.movieTitle = $(val).find('.movie-item-title').children('a').text()
//电影评分
movieObj.movieDetail = $(val).find('.channel-detail-orange').text()
//把抓取到的内容 放到数组里面去
movieArr.push(movieObj)
})
//说明 数据获取完毕
if (movieArr.length >0){
resolve(movieArr)
}
})
})
}
//获取正在热映电影数据
getMovies('https://maoyan.com/films?showType=1')
.then((data) => {
console.log(data)
})
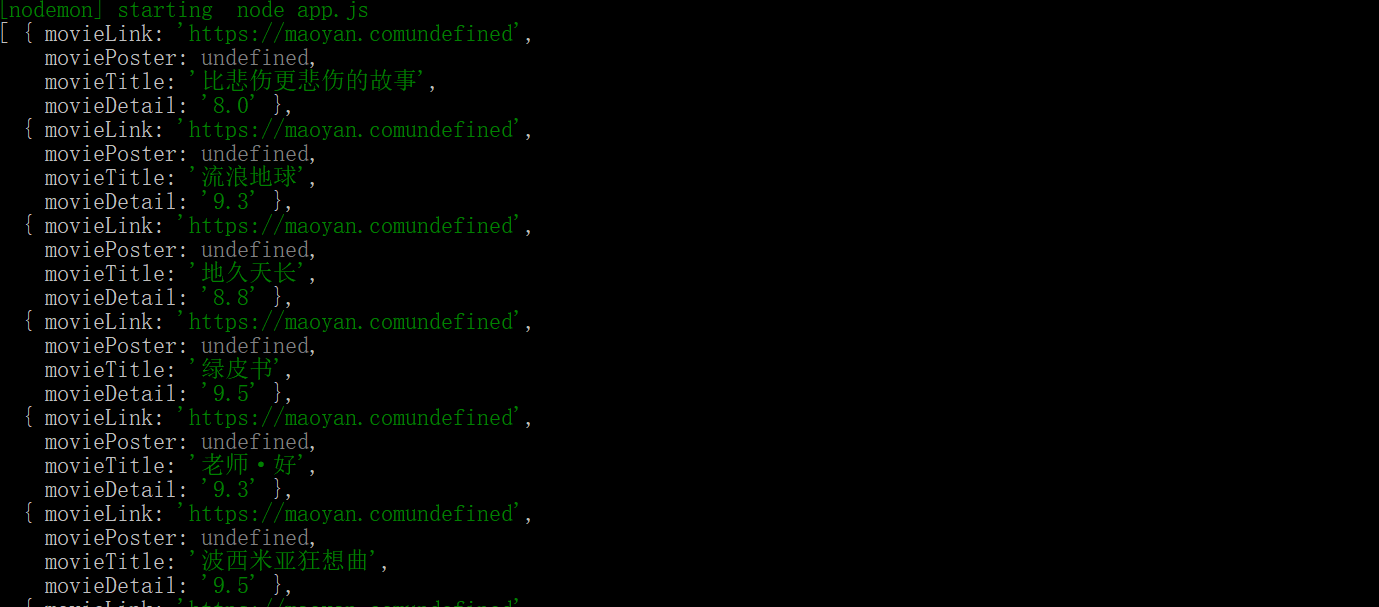
抓取结果(部分)
nodejs爬虫第一篇---> request、cheerio实现小爬虫的更多相关文章
- 爬虫第一篇基本库的使用——urllib
在Python2中有urllib2和urllib3两个库来实现请求的发送,在Pyhon3中则统一为urllib. urilib包含以下4个模块 request:最基本的请求模块,可以用来实现请求的发送 ...
- 爬虫第一篇:爬虫详解之urllib.request模块
我将urllib.request 的GET请求和POST请求两种方法做了总结 GET请求 GET请求爬取: import urllib.request import urllib.parse head ...
- 我的第一篇博客--SQL小语句
开通了博客,拥有了属于自己的小小天地.先写一篇今儿刚学到的 1 remove mirroring relationship alter database datab_name set partner ...
- 放养的小爬虫--豆瓣电影入门级爬虫(mongodb使用教程~)
放养的小爬虫--豆瓣电影入门级爬虫(mongodb使用教程~) 笔者声明:只用于学习交流,不用于其他途径.源代码已上传github.githu地址:https://github.com/Erma-Wa ...
- 放养的小爬虫--京东定向爬虫(AJAX获取价格数据)
放养的小爬虫--京东定向爬虫(AJAX获取价格数据) 笔者声明:只用于学习交流,不用于其他途径.源代码已上传github.githu地址:https://github.com/Erma-Wang/Sp ...
- 网络爬虫urllib:request之urlopen
网络爬虫urllib:request之urlopen 网络爬虫简介 定义:按照一定规则,自动抓取万维网信息的程序或脚本. 两大特征: 能按程序员要求下载数据或者内容 能自动在网络上流窜(从一个网页跳转 ...
- python爬虫第一天
python爬虫第一天 太久没折腾爬虫 又要重头开始了....感谢虫师大牛的文章. 接下来的是我的随笔 0x01 获取整个页面 我要爬的是百度贴吧的图,当然也是跟着虫师大牛的思路. 代码如下: #co ...
- nodejs爬虫笔记(一)---request与cheerio等模块的应用
目标:爬取慕课网里面一个教程的视频信息,并将其存入mysql数据库.以http://www.imooc.com/learn/857为例. 一.工具 1.安装nodejs:(操作系统环境:WiN 7 6 ...
- nodejs .http模块, cheerio模块 实现 小爬虫.
代码: var http = require("http"); var cheerio = require("cheerio"); var url = 'htt ...
随机推荐
- DOCKER学习_001:Docker简介
一 Docker简介 1.1 docker由来 Docker的英文翻译是“码头工人”,即搬运工,它搬运的东西就是我们常说的集装箱Container,Container里面装的是任意类型的App.我们的 ...
- SpringCloud + Consul服务注册中心 + gateway网关
1 启动Consul 2 创建springcloud-consul项目及三个子模块 2.1 数据模块consul-producer 2.2 数据消费模块consul-consumer 2.3 ga ...
- $Noip2018/Luogu5022$ 旅行
$Luogu$ $Description$ 一个$n$个点,$m$条边的图.$m=n-1$或$m=n$.任意选取一点作为起始点,可以去往一个没去过的点,或者回到第一次到达这个点时来自的点.要求遍历整个 ...
- Java高级特性——流
以上就是这段时间学习完流的知识以后我的总结,.mmap文件可以去我的github上获取:https://github.com/xiaozhengyu/StudyNotes.git
- 【转】Beyond compare4密钥
转:https://blog.csdn.net/lemontree1945/article/details/92963423 w4G-in5u3SH75RoB3VZIX8htiZgw4ELilwvPc ...
- Fabric1.4:Go 链码开发与编写
1 链码结构 1.1 链码接口 链码启动必须通过调用 shim 包中的 Start 函数,传递一个类型为 Chaincode 的参数,该参数是一个接口类型,有两个重要的函数 Init 与 Invoke ...
- arthas 使用指导
arthas 阿尔萨斯 这种命令行的东西首先得知道 如何使用帮助,帮助文档最先开始用的,应该是可以在网上找到的官方文档 文档一:https://alibaba.github.io/arthas/ind ...
- spring-boot内嵌三大容器https设置
spring-boot内嵌三大容器https设置 spring-boot默认的内嵌容器为tomcat,除了tomcat之前还可以设置jetty和undertow. 1.设置https spring-b ...
- 递推 dp
工大要建新教学楼了,一座很高很高的楼,它有n层.学校为了减少排电梯的队伍,建造了好多好多电梯,共有m个.为了让电梯有序,学校给每个电梯设定了独特的可停楼层,如 x1 x2 y1 y2 表示,x1楼层到 ...
- python 文件监听
对文件进行监听.过滤 def tail(filename): f = open(file=filename, mode='r', encoding='utf-8') # 打开文件不能用with,因为监 ...