我是如何在实际项目中解决MySQL性能问题
可能是本性不愿随众的原因,我对于程序员面试中动辄就是考察并发上千万级别的QPS向来嗤之以鼻,好像国内的应用都是那么多用户量一样,其实并发达到千万,百万以上的应用能有几个?
绝大多数的程序员面临的只是解决百级、千计、万级的并发量,与其纯粹为了面试学一些空中楼阁,不如脚踏实地的学习如何解决眼前实际问题。
而对于我,最能激发我学习动力的不是什么造火箭面试,而是能够解决实际的问题。
哪怕看起来没那么高大上的场景,只要能解决产品给客户带来的痛点,就能给做技术的人带来很大的成就感!
言归正传,公司最近开发的一个用于学生在线考试的产品正好面临这样的问题。
技术框架
- 服务器:Windows Server 2008(64位虚拟机,内存16G)
- DB:MySQL 5.7.27
- 后端:Spring+Mybatis
- 教师端:VueJS
- 学生端(平板电脑):安卓原生 + VueJS
事件经过
- 9.17 模拟考试的学生数量大约500,前方反馈页面出现卡顿现象,有些学生的答题未提交上来
- 9.18 将widnows自带的性能监控开起来,主要监控CPU、内存、磁盘IO的情况,并将晚自习模拟考试的两个小时监控保存起来
- 9.19 经过分析监控日志,发现瓶颈在磁盘IO上,读取的压力很大,因为是机械键盘,所以联系学校可否将硬盘换为固态硬盘
(事后想这样虽然是也是一个解决途径,但不应该是程序员的第一选择,因为硬件的优化应该是软件优化做到极致之后的举措,而不是第一时间把问题抛给硬件,这是很不负责的态度)
还好学校没有答应,于是开始分析为何磁盘读取压力这么大,涉及到磁盘读写,最大可能应该是数据库的读写,也就是我们用的MySQL,那么为什么MySQL压力这么大呢?
于是分析学生参与考试的整个过程:1. 打开应用:学生使用平板电脑打开app,并进入考试列表页面(原生),这里后台读取操作是查询本课程目前的考试
2. 开始考试:当某一考试开始时间到达,考生可以点击开始答题按钮进入考试,此时,会将整个试卷的内容都拉取下来,并存储到安卓本地的DB中(这里读取的并发很大)
3. 做题:学生开始答题,当学生每点击下一题时,会将本题的答案保存到后台,成功后会跳转到下一题(写入的并发压力大)
4. 提交:学生答完所有题目后,会在最后一题点击提交按钮,保存最后一题,并自动计算得分所以读取的问题锁定在第2步,也就是拉取试卷的过程,那么首先考虑可否使用缓存,而不是每次都去DB存储读取,因为试卷一旦建立,数据是固定的,而不会去更新,契合缓存使用的场景。进一步思考为什么MySQL没用使用缓存呢,原谅我的无知,查阅了一下才知道,项目使用的MySQL5.7.27中默认参数如下
innodb_buffer_pool_size=8M
innodb_buffer_pool_instances=8
innodb_log_file_size=48M调整后参数如下(关于这几个参数,请参考后续的原理解析):
innodb_buffer_pool_size=5G
innodb_buffer_pool_instances=8
innodb_log_file_size=256M磁盘读的压力问题解决。
- 10.29 查看日志,发现主键重复问题(UUID),此问题是代码问题。
- 10.30 添加后台自动提交的功能(防止学生通过平板锁屏后的倒计时暂停作弊),发现DB连接无法获取的异常,将my.ini中max_connections由默认的156改为800解决
- 10.31 发现日志中偶尔存在死锁问题,系统抛出MySQLTransactionRollbackException,代码逻辑问题。
- 11.6 1200+人的考试,顺利完成,整个过程服务器压力不大,最后学校满意读很高。
- 12.19 期末考试第一场出现主键重复错误(MySQLIntegrityConstraintViolationException),调整写参数innodb_flush_log_at_trx_commit=0
- 12.20 一切正常(未出现重复主键错误,也就是说出现重复主键错误和写并发高有关,但为何并发写高时会出现此错误,需要查看随机数生成机理)
学习反思
虽然这里的解决方案都不是那么“高大上”的技术手段,但正是因为这样的契机,激发了我系统学习MySQL的兴趣
在试图解决以及避免考试中出现性能问题总,总结了几个比较重要的优化措施
- 充分利用缓存,特别是数据不频繁更新的数据,比如本项目中的试卷内容拉取,缓存中有几个比较重要的参数需要了解
缓存相关
1. innodb_buffer_pool_size = 下面两个参数乘积的整数倍,InnoDB引擎下可以缓存索引和数据块,如果是专用DB服务器,可以最大设置到OS内存的80%。5.7.5之后可以动态调整
此参数也不宜过大,因为过大会导致脏页太多,DB关闭时会比较慢,开启的预热也比较慢,所以上面的设置其实是有点大的
2. innodb_buffer_pool_chunk_size (5.7.5之后引入,默认128M)
3. innodb_buffer_pool_instances (默认8) 日志相关
1. innodb_log_buffer_size 当存在较大数据量的事务提交的时候,修改此参数会降低磁盘写
2. innodb_flush_logs_at_trx_commit (默认为1,对写性能要求高而对数据不是特别敏感时可以改为0或者2)参考:https://dev.mysql.com/doc/refman/5.7/en/innodb-buffer-pool-resize.html
当执行一条查询SQL时,步骤如下(以下图表参考极客,如有侵权,请联系)
从此图中了解数据查询为何走缓存快的多了,因为省去了分析、优化、执行等过程,不与存储引擎交互,当然也就没有磁盘读了。
当然,这也是项目中增大innodb_buffer_pool_size的原因 - SQL查询的优化方法
> 提前终止查询(比如使用limit避免扫描全表)
> 不需要去重,则使用union all,否则中间的临时表会因为加上distinct而导致效率低下
> 如果是经常删除插入的表,可能存在大量的空洞,导致虽然表的数量量不大,但占用空间依然很大、查询效率地下,用下面的方法可清理空间
alter table t engine=InnoDB (相当于recreate)
optimize table t (相当于recreate+analyze)
truntace table t (相当于drop+create)
> 充分利用索引(下边的索引会讲到) 充分利用MySQL影响性能的参数
这里也有必要提下MySQL的日志机制(分为redoLog和binLog),以下是SQL更新的过程
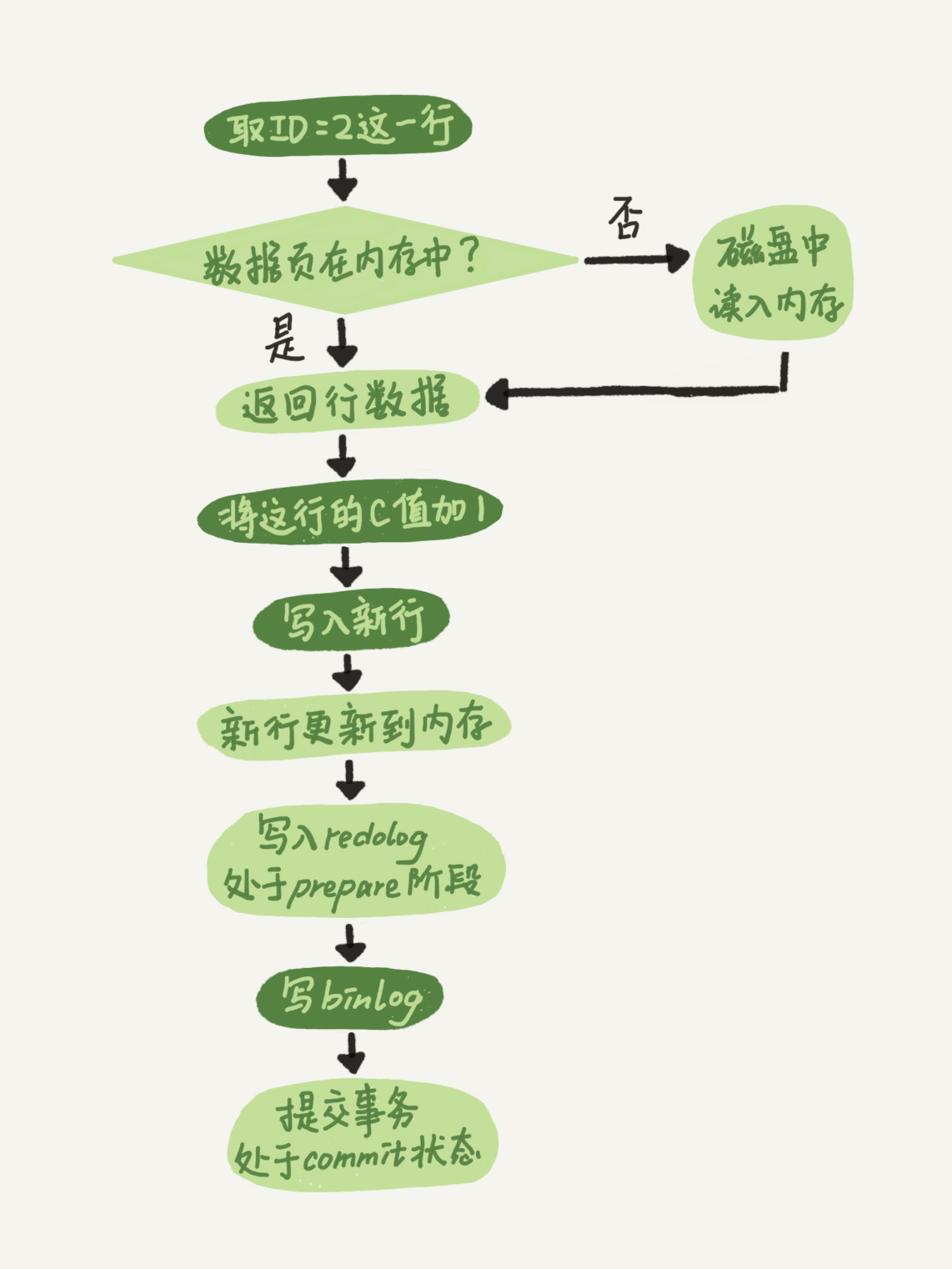
>项目中没有调整innodb_flush_logs_at_trx_commit默认值1(表示每次事务提交都会持久化到磁盘中),因为我们的数据用于学生考试,对精确性有一定的要求。>如果磁盘写压力比较大,而平板端提交等待时间长的话(比如最后提交试卷),应该调大innodb_log_buffer_size,这个参数其实只是对于单次commit比较大的数据有用,表示在真正commit前如果达到了这个参数的峰值,会先写入磁盘中,极大降低单次提交的效率。这个参数在版本更新中屡次增大,在5.7.6之后默认为16M,足以应对绝大多数情况。
>项目增大innodb_log_file_size(默认48M),是为了减少磁盘的IO,这个参数控制的是redoLog的文件大小,参考此图()
图中innodb_log_files_in_group设置为4(默认2)
每一个log文件的大小为innodb_log_file_size,如果设置过小,checkpoint到达(覆盖之前的日志)后,就会先擦除掉之前的redoLog,然后再往前写。
所以如果这个参数过小,就会经常降低磁盘IO,推荐设置为innodb_buffer_pool_size的1/4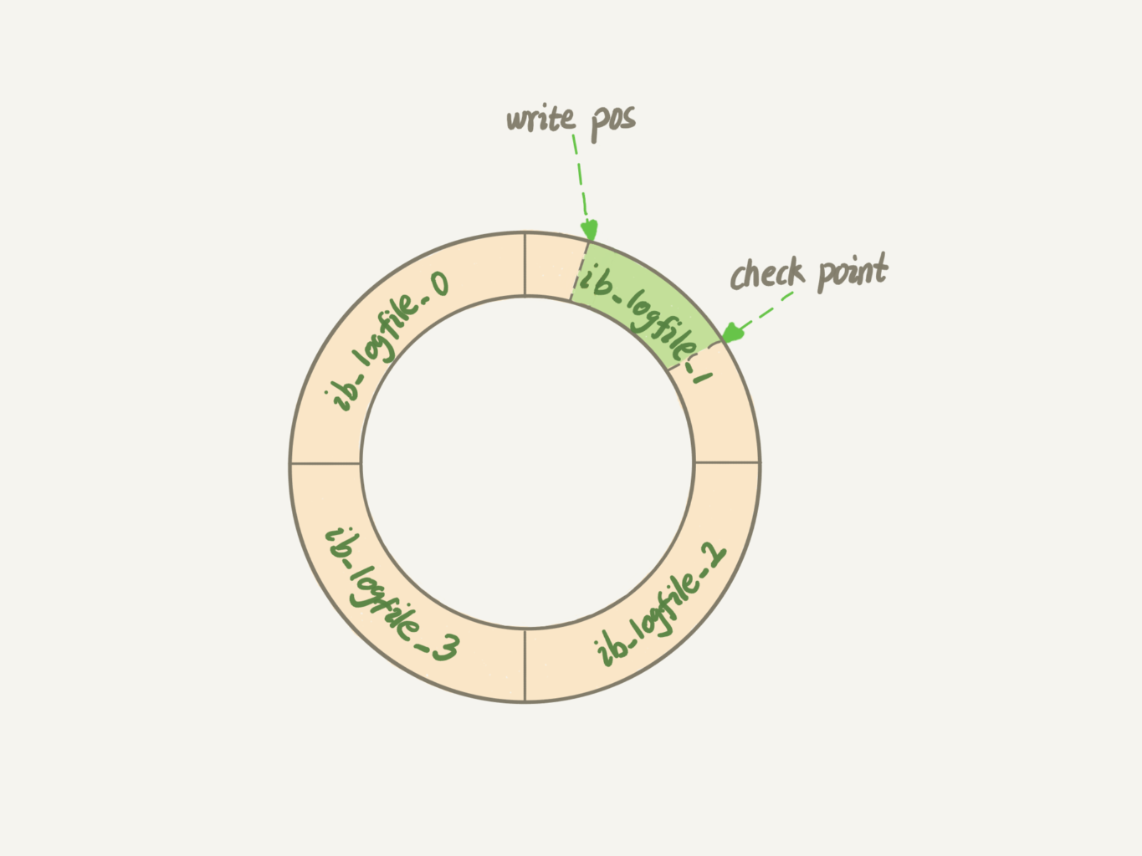
- 充分利用索引
因为当时项目中已经解决磁盘读的问题,所以没有在索引上进行优化。实际上,索引优化是非常值得学习的手段(特别是执行慢的代码段)
而对于执行慢的的SQL,可以使用慢查询方法来寻找,方法如下:慢查询:查询时间长于long_query_time参数的设置(默认10秒),查询方法:show variables like 'long_query_time';
查看慢查询日志(slow_query_log):show variables like 'slow_query%'; (默认不开启)
慢日志开启方法:my.cnf中设置slow_query_log =1 以及slow_query_log_file的路径然后通过mysqldumpslow来找到执行慢的SQL
下面总结几条建立索引的一般规则
> 尽量使用自增主键索引,因为非主键索需要二次查询
> 利用覆盖索引来避免回表
> 利用前缀索来避免索引的字段过长
> 使用短字段建立索引
> 避免使用使索引失效的语句,比如
不等于(可转换为大于和小于)、
is null和is not null(如果失效可设置列默认值)、
or(如果失效使用使用union解决)、
in(如果失效使用between和exists替换)
now()函数、用户自定义函数、存储函数、用户变量、临时表、mysql库中的系统表、至于什么B树、MySQL的B+树等装逼的知识,不在本文讨论范围内,感兴趣的自己去查
学会监控MySQL的运行状态(找到慢查询)
show global status; // 显示所有状态,下面列出几个跟性能关系比较大的status
show status like 'Threads%'; // 显示的Threads_connected可用来标示并发数
show status like '%conn%' // 显示的Connections是所有尝试连接的数量
show processlist 显示正在执行的MySQL连接,记录数与上面的Threads-connected相等> 对应的配置项可以在配置文件中修改(windows的my.ini,linux的my.cnf),比如max_connections等
- 查看执行计划 (explain或desc SQL)

比如上面的执行计划结果是使用了SQL: explain SELECT * FROM t where c=10;
表t中,c为非主键索引,下面逐个字段做简单解释
> id是执行计划的顺序标示,如果有自查询,则id越大越先执行
> select_type:查询类型
simple:无子查询和union
primary:包含子查询的查询语句的最外层或union的第一句
subquery:子查询
derived:临时表
union:union中的第二个及以后的查询
union result:union的结果
> table:表名(可能为临时表的derived)
> type:访问类型(索引是否被使用需要用这个字段判断),以下是性能从低到高的类型
all:全表扫描
index:按照索引顺序进行全表扫描
range:范围扫描
ref:非唯一索引的匹配
const:唯一索引的匹配(本例)
system:查询表只有一行
null:不需要扫描表
> possible keys:与查询相关,可能使用的索引
> key:真正使用的索引(优化器的选择)
> key_len:使用的索引长度
> ref:显示某列或const被选择
> rows:预估查询行数
> Extra:补充信息,对于分析性能帮忙比较大,不再详列 关于事务,尽量避免死锁的可能、减少锁数据的时间
需要了解以下内容
> MySQL默认都是行锁
> 行锁都是对索引的锁
> 不要把查询语句放在事务开启和提交之间
> 默认锁级别为REPEATABLE READ(可重读),可通过更改TRANSACTION ISOLATION LEVEL,下面的四种级别的锁,就不再赘述了
SERIALIZABLE(序列化)、REPEATABLE READ(可重读)、READ COMMITTED(提交后读)、READ UNCOMMITTED(未提交读)
MySQL的其他基本原理
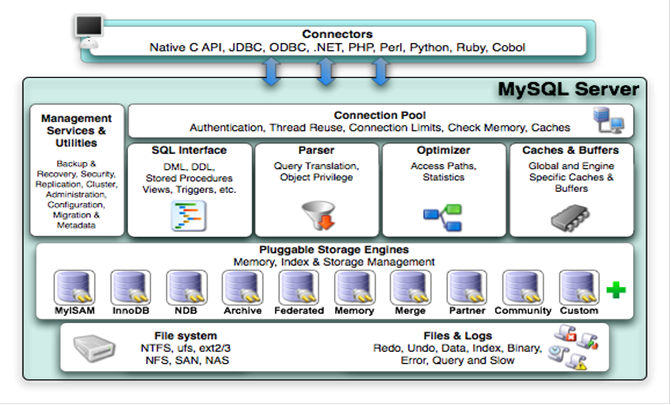
- MySQL是半双工(结果传输时不能再次发送)
- 基本架构如下(老经典图)
此文会持续更新,直到把所有我认为对实际项目有帮助的地方总结完毕!
参考:
https://dev.mysql.com/doc/refman/8.0/en/server-status-variables.html#statvar_Connections
https://www.cnblogs.com/kevingrace/p/6133818.html
https://zhuanlan.zhihu.com/p/59818056
https://blog.csdn.net/dream_188810/article/details/78870520
https://www.cnblogs.com/parryyang/p/5711537.html
我是如何在实际项目中解决MySQL性能问题的更多相关文章
- Flask项目中使用mysql数据库启动项目是发出警告
Flask项目中使用mysql数据库启动项目是发出警告: Warning: (1366, "Incorrect string value: '\xD6\xD0\xB9\xFA\xB1\xEA ...
- 转 mvc项目中,解决引用jquery文件后智能提示失效的办法
mvc项目中,解决用Url.Content方法引用jquery文件后智能提示失效的办法 这个标题不知道要怎么写才好, 但是希望文章的内容对大家有帮助. 场景如下: 我们在用开发开发程序的时候,经常 ...
- 在maven项目中解决第三方jar包依赖的问题
在maven项目中,对于那些在maven仓库中不存在的第三方jar,依赖解决通常有如下解决方法: 方法1:直接将jar包拷贝到项目指定目录下,然后在pom文件中指定依赖类型为system,如: < ...
- WPF项目中解决ConfigurationManager不能用(转)
https://blog.csdn.net/MOESECSDN/article/details/78107888 在WPF项目中遇到这样的问题,做一下笔记.希望对自己和读者都有帮助. 在aap.con ...
- web项目中解决post乱码和get乱码的方法
前提复习编码问题产生的原因: 1. 什么是URL编码. URL编码是一种浏览器用来打包表单输入的格式,浏览器从表单中获取所有的name和其对应的value,将他们以name/value编码方式作为U ...
- 关于在项目中遇到MySQL数据库死锁的问题
在MySQL中, 当一个事务去更新某条数据, 还没有提交的时候, 第二个事务去更新该数据, 则会出现等待获取锁超时异常: >> Lock wait timeout exceeded; tr ...
- 项目中解决实际问题的代码片段-javascript方法,Vue方法(长期更新)
总结项目用到的一些处理方法,用来解决数据处理的一些实际问题,所有方法都可以放在一个公共工具方法里面,实现不限ES5,ES6还有些Vue处理的方法. 都是项目中来的,有代码跟图片展示,长期更新. 1.获 ...
- docker 使用mysqldump命令备份导出项目中的mysql数据
下图为镜像重命名后的镜像名为uoj,现在要把这个镜像中的mysql导出 运行如下命令: docker exec -it uoj mysqldump -uroot -proot app_uoj233 & ...
- 如何在AbpNext项目中使用Mysql数据库
配置步骤: 1.更改.Web项目的appsettings.json的数据库连接字符串.如:server=0.0.0.0;database=VincentAbpTest;uid=root;pwd=123 ...
随机推荐
- hdu多校第一场 1013(hdu6590)Code 凸包交
题意: 给定一组(x1,x2,y),其中y为1或0,问是否有一组(w1,w2,b),使得上述的每一个(x1,x2,y)都满足x1*w1+x2*w2+b在y=1时大于0,在y=-1时小于0. 题解: 赛 ...
- class.forname & classloader
From https://www.cnblogs.com/gaojing/archive/2012/03/15/2413638.html 传统的使用jdbc来访问数据库的流程为: Class.forN ...
- try-catch 捕捉不到异常
code: int _tmain(int argc, _TCHAR* argv[]) { cout << "In main." << endl; //定义 ...
- Ubuntu下搭建Pixhawk开发环境
安装提示 需要网络环境,不然下载会很慢. 工具安装 1. 权限设置 sudo usermod -a -G dialout $USER 代码输入可以拷贝,但是不可以用快捷键. 需要输入密码,输入密码无显 ...
- Date、DateFormat、Calendar、System、Math类总结
java.util.Date: 构造方法 public Date() 空参构造,返回当前时间 public Date(long 毫秒值) 指定毫秒值的时间 普通方法 long getTime() 获取 ...
- Eclips安装STS(Spring Tool Suite (STS) for Eclipse)插件
Spring Tool Suite(sts)就是一个基于Eclipse的开发环境, 用于开发Spring应用程序.它提供了一个现成的使用环境来实现, 调试, 运行, 和部署你的Spring应用程序.包 ...
- 面试系列16 redis的持久化
1.RDB和AOF两种持久化机制的介绍 RDB持久化机制,对redis中的数据执行周期性的持久化 AOF机制对每条写入命令作为日志,以append-only的模式写入一个日志文件中,在redis重启的 ...
- 《Practices of an Agile Developer:Woring in the Real World》读书笔记 PB16110698(~3.22)第三周
<Practices of an Agile Developer:Woring in the Real World>读书笔记 本周我阅读了<高效程序员的45个习惯:敏捷开发修炼之道 ...
- http及浏览器相关知识点归纳
http是应用层协议,采用请求/响应模型 1.浏览器地址栏输入URL地址后发生了什么? 浏览器判断地址是否是合理的URL地址,是否是http协议请求,如果是则进入下一步 浏览器对此URL进行缓存检查: ...
- 【期望DP】[poj2096]Collecting Bugs
偷一波翻译: 工程师可以花费一天去找出一个漏洞——这个漏洞可以是以前出现过的种类,也可能是未曾出现过的种类,同时,这个漏洞出现在每个系统的概率相同.要求得出找到n种漏洞,并且在每个系统中均发现漏洞的期 ...