Flink流处理(三)- 数据流操作
3. 数据流操作
流处理引擎一般会提供一组内置的操作,用于对流做消费、转换,以及输出。接下来我们介绍一下最常见的流操作。
操作分为无状态的(stateless)与有状态的(stateful)。无状态的操作不包含任何内部状态。也就是说,处理此event时,并不需要任何其他历史event的信息,也不需要保存它自己的信息。无状态的操作易于并行,因为events可以以它们到达的顺序,相互独立的被处理。在出现错误时,无状态operator可以被简单的重新执行,从它丢失数据的点开始继续执行即可。
有状态的operator可能会维护之前它处理过的events的信息。它的状态信息(state)会根据到达的events进行更新,并且被用于处理之后events的逻辑。有状态的流处理应用对于并行来说会更为复杂,并且需要以容错的方式运行。因为它的状态需要高效的分区(partitioned),并能够在发生错误后得到稳定的恢复。
数据消费与输出
数据消费与输出的操作使得流处理器可以与外部系统进行通信。数据消费是指:从外部数据源获取raw data,然后转换成适用于处理的格式。实现了数据消费逻辑的operator称为data sources,它可以消费如 TCP socket 的数据、文件、Kafka topic 的数据等。数据输出(egress)是生成output的操作,它将数据以适合外部系统处理的格式输出。实现数据输出逻辑的operator称为data sink。
转换操作
转换操作是一个单次操作,每次单独的处理一个event。用于将event 做某些变换后再输出一个新的流数据。转换逻辑可以整合在operator中,或是由用户定义的方法提供。如下图所示:
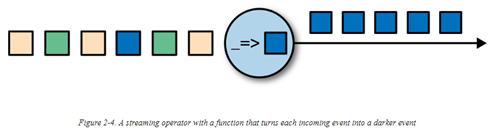
Operators 可以接收多个inputs并产生多个输出流。它们也可以用于修改dataflow graph 的结构,例如将流split为多个流,亦或是将多个流整合为一个流。
滚动聚合(rolling aggregation)
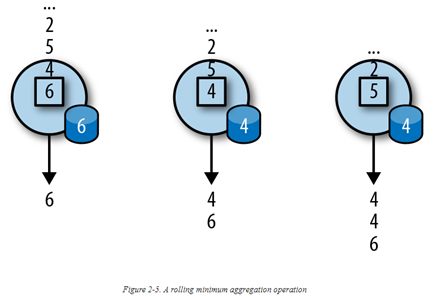
Rolling aggregation 是一个聚合操作,例如sum,minimum以及maximum。它会根据输入的event,对结果做持续的更新。聚合操作是有状态的,它将输入的数据与当前的状态信息(state)进行整合,再产生一个更新后的聚合值。为了高效地与当前状态进行整合,并输出一个single value,聚合操作必须满足结合律(associative)与交换律(commutative)。否则 operator 需要存储整个流的历史记录。下图是一个滚动聚合求最小值的示例,它持有当前最小值,并根据输入的events更新当前最小值:
窗口操作
转换与滚动聚合每次处理一个event并产生一个output event,继而(有可能)更新状态。然而,某些操作需要收集并缓存一些记录后再计算它们的结果。例如求中值函数,这个操作需要对多条数据聚合做处理,但是流是无限的,对此,我们需要限制此操作维护的数据量大小。此功能由窗口(window)操作提供。
考虑这么一个场景:应用为司机提供实时的路况信息。这里,我们需要知道在某个地段,前几分钟内是否有有拥堵或是事故)。如果仅是对流历史记录做一个单聚合(single aggregate),则会损失数据随时间变化的信息。例如,你可能想知道每5分钟内有多少个自行车穿过某交叉路口。
Window操作会持续地从一个无限流中,创建events的有限子集(称为buckets),使得我们可以在这些有限集合上做计算。Events 通常是根据数据的属性或是时间,被分配到buckets中。为了更好地定义window operator,我们先了解一下events是如何分配给buckets、以及windows是如何产生一个result的。Window 的行为由一组策略定义。Window 策略决定了什么时候创建bucket、哪个event被分配到哪个bucket中、以及bucket里的内容什么时候被评估(evaluate)。对于何时评估,这个基于触发条件。当满足某个出发条件时,bucket里的内容会被发往一个评估函数(evaluation function),此方法会对bucket里的元素进行计算。评估函数可以是聚合操作(例如求sum、最小值)、或是用户自定义的操作。决策可以是基于时间的(例如在最近5秒内收到的events),也可以是基于数量的(例如,最近收到的100个events),亦或是基于数据的属性。下面我们介绍一下常见的窗口类型。
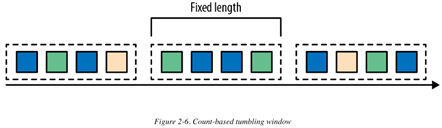
- 滚动(tumbling)窗口:分配events到不重叠的固定大小的buckets中。在超出window的边界后,所有在window内的的事件会被发往到评估函数做处理。基于数量的(count-based )滚动窗口定义了:在收集多少个events后,开始触发评估。图2-6显示了一个count-based滚动窗口,将输入流分散到四个events一组的buckets中。
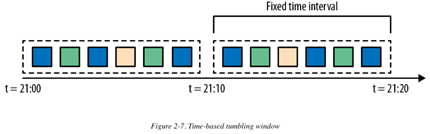
基于时间的滚动窗口定义了:以时间周期分隔,在一个时间周期内的events会被缓存到bucket 中。
图 2-7 展示了一个基于时间的滚动窗口,将events收集到buckets中,每10分钟触发一次计算。
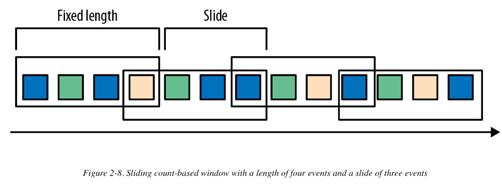
2. 滑动窗口:分配events到可重叠的固定大小的buckets中。也就是说,一个event可能属于多个buckets。我们在定义一个滑动窗口时,需要提供两个变量:长度(length)和步长(slide)。Slide的值决定了新bucket创建的间隔。下图是一个基于数量(count-based)的滑动窗口,长度为4个events,slide为3个events:
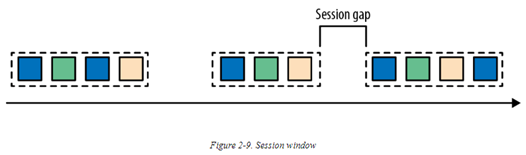
3. 会话(session)窗口:会话窗口在某些实际场景中会比滚动窗口与滑动窗口更适用。考虑这样一个场景:一个应用需要分析在线用户的行为。这里我们需要聚合在一个session内,某个用户的所有事件。Session 由一系列连续的事件组成,并且在连续事件之后,会有一段无事件时间。例如,用户浏览新闻时,点击不同的页面,可以被看作一个session。因为一个session 的长度并无法预先定义,而是取决于实际的数据。所以滚动已经滑动窗口并不适用于此场景。我们需要的是一个windows操作可以将所有属于同一个session 的事件,分发到同一个bucket中。会话窗口可以根据一个“会话间隔”(session gap)定义一个session的过期时间。在到达过期时间后,一个会话窗口即被关闭。下图展示了一个会话窗口:
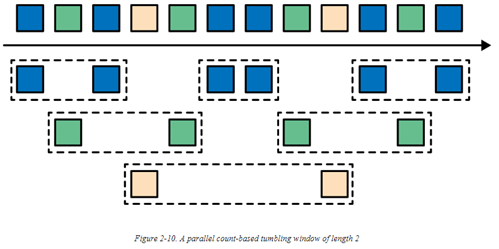
到目前为止,我们看到的所有窗口类型都是应用于整个流。但是在实际场景中,可能需要将一个流分为多个逻辑上的流,并在之上使用并行window。例如,假设我们收到的数据源来自于各个不同的传感器,我们可能需要通过传感器的ID先对stream做整合,然后再在之上应用窗口计算。在并行窗口(parallel windows)中,每个分区(partition)均完全独立地应用它特定的窗口策略。下图展示了一个基于计数的滚动窗口,长度为2,通过event 颜色分区:
在流处理中有两个十分重要的概念:时间语义(time semantics)以及状态管理(state management)。窗口操作与这两个概念关系密切。时间可能是流处理中最重要的方面。尽管低延时是流处理中非常棒的一个特性,但是它的实际延迟值已经远超出了快速分析(just fast analytics)的延迟。流处理在实际系统、网络、以及通信信道(communication channel)中还不够完善,并且流数据经常会延迟到达,或是乱序到达。这里很重要的一点是:在这些情况下,如何交付出精准、明确(deterministic)的结果。除此之外,流处理应用除了处理当前产生的event外,还应具备处理历史events的能力,这可以实现流的离线分析,甚至是时间穿梭分析(time travel analyses)。当然,如果你的系统无法保证对状态信息的容错,则这些功能均毫无意义。到目前为止,我们提到的所有窗口类型都需要先将数据缓存,然后再应用计算并产生结果。实际上,如果你想在一个流应用上计算任何感兴趣的信息,即使是一个简单的计数(count),也需要维护状态信息(state)。假设一个流处理应用可能会跑几天,几个月,甚至几年,我们需要确保在任何故障发生后,state能可靠地被恢复,并且系统需要确保仍能提供准确的结果。下面我们会介绍在流处理中time 的概念,以及在发生错误情况下的state guarantees。
References:
Vasiliki Kalavri, Fabian Hueske. Stream Processing With Apache Flink. 2019
Flink流处理(三)- 数据流操作的更多相关文章
- 深度介绍Flink在字节跳动数据流的实践
本文是字节跳动数据平台开发套件团队在1月9日Flink Forward Asia 2021: Flink Forward 峰会上的演讲分享,将着重分享Flink在字节跳动数据流的实践. 字节跳动数据流 ...
- 带你玩转Flink流批一体分布式实时处理引擎
摘要:Apache Flink是为分布式.高性能的流处理应用程序打造的开源流处理框架. 本文分享自华为云社区<[云驻共创]手把手教你玩转Flink流批一体分布式实时处理引擎>,作者: 萌兔 ...
- Flink流处理的时间窗口
Flink流处理的时间窗口 对于流处理系统来说,流入的消息是无限的,所以对于聚合或是连接等操作,流处理系统需要对流入的消息进行分段,然后基于每一段数据进行聚合或是连接等操作. 消息的分段即称为窗口,流 ...
- Java基础-IO流对象之数据流(DataOutputStream与DataInputStream)
Java基础-IO流对象之数据流(DataOutputStream与DataInputStream) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.数据流特点 操作基本数据类型 ...
- FLINK流计算拓扑任务代码分析<一>
我打算以 flink 官方的 例子 <<Monitoring the Wikipedia Edit Stream>> 作为示例,进行 flink 流计算任务 的源码解析说明. ...
- flink 流式处理中如何集成mybatis框架
flink 中自身虽然实现了大量的connectors,如下图所示,也实现了jdbc的connector,可以通过jdbc 去操作数据库,但是flink-jdbc包中对数据库的操作是以ROW来操作并且 ...
- Flink整合面向用户的数据流SDKs/API(Flink关于弃用Dataset API的论述)
动机 Flink提供了三种主要的sdk/API来编写程序:Table API/SQL.DataStream API和DataSet API.我们认为这个API太多了,建议弃用DataSet API,而 ...
- IO流 总结三
编码:字符串变成字节数组. 解码:字节数组变成字符串 String --> byte[]; str.getBytes(); byte --> String: new String(byt ...
- Flink流处理(一)- 状态流处理简介
1. Flink 简介 Flink 是一个分布式流处理器,提供直观且易于使用的API,以供实现有状态的流处理应用.它能够以fault-tolerant的方式高效地运行在大规模系统中. 流处理技术在当今 ...
随机推荐
- LAMP集成环境搭建
本教程是在centos6.8 64位系统下进行操作 我们首先准备搭建LAMP环境 LAMP指的是Linux.Apache.MySQL 和 PHP 如果要安装PHP5.5 需要 首先rpm -ivh h ...
- 纪中集训2020.02.05【NOIP提高组】模拟B 组总结反思——【佛山市选2010】组合数计算,生成字符串 PPMM
目录 JZOJ2290. [佛山市选2010]组合数计算 比赛时 之后 JZOJ2291. [佛山市选2010]生成字符串 比赛时 之后 JZOJ2292. PPMM 比赛时 之后 JZOJ2290. ...
- AGC001 E - BBQ Hard [组合数]
这题就是要求 \(\sum_{i=1}^{n} \sum_{j=i+1}^{n} C(a_i+a_j+b_i+b_j,a_i+a_j)\) 考虑搞一搞,\(C(a_i+a_j+b_i+b_j,a_i+ ...
- 解决NahimicSvc32.exe与bilibili直播姬的音频不兼容的问题
某次测试哔哩哔哩直播姬的时候发现系统声音采集异常的错误 NahimicSvc32.exe是NahimicService下的程序,奇怪的是我的本本所有硬件没有一个微星有关系,怎么就装上了微星的服务程序? ...
- 使用IntersectionObserver制作滚动动画以及其他记录
前言 最近在重做公司项目的主页,正好新来了个UI,整个都重新设计了一下,动画还挺多的.我之前没有怎么玩过这些,踩了挺多坑,最后找到了目前而言最合适的方法,现在做一个记录. 需要把原来的主页从项目中抽出 ...
- 代数式转换为c语言表达式(很简单)
- 百度地图根据list经纬度算每个点到剩余点的平均距离、最远距离和最近距离
一.使用步骤 说明:给你一大串坐标list.计算每个点到其他所有点的最近最远平均距离. 1.打开百度地图api在线demo(随便一个都行) 2.替换<script></script& ...
- source insight增加tab标签页的方法之sihook
1.效果如下 2.方法见如下博客 http://www.cnblogs.com/Red_angelX/archive/2013/01/23/2873603.html
- BZOJ3680 JSOI2004 平衡点 - 随机/近似算法
迭代乱搞了下就过了…… #include <bits/stdc++.h> using namespace std; ],y[],w[]; double xm,ym,wt,k,lambda= ...
- java 学习(day2) 时钟类
看过python的面向对象,所以入手java总的来说还是比较快的. 看视频学习之后写了一个简单的时钟 一个时钟有两部分组成小时和分钟.再大一些还有月,日. 分析一下就是,上述这些属性到达一个值之后,就 ...