机器学习——Bagging与随机森林算法及其变种
随机森林算法:
一般用于大规模数据,百万级以上的。
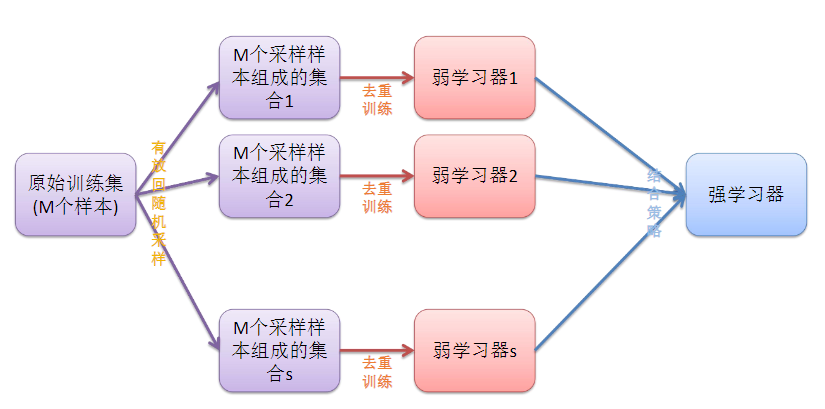
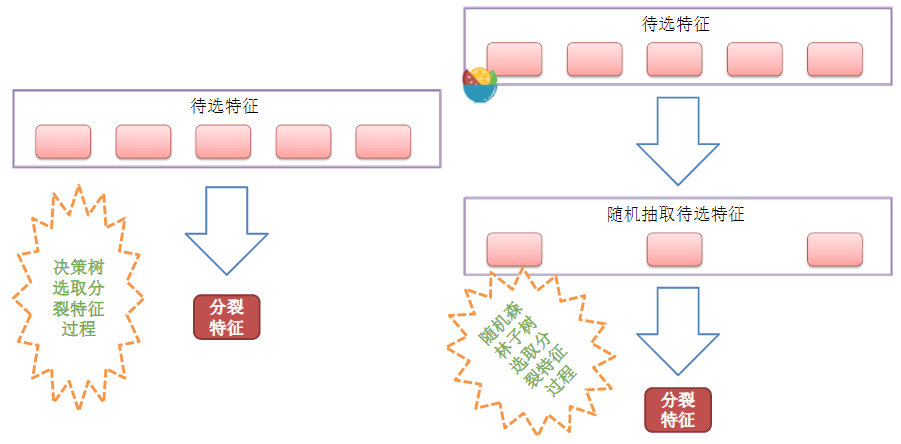
在Bagging算法的基础上,如上面的解释,在去重后得到三组数据,那么再随机抽取三个特征属性,选择最佳分割属性作为节点来创建决策树。可以说是
RF(随机森林)的变种:
ExtraTree算法
凡解:和随机森林的原理基本一样。主要差别点如下
①随机森林是在含有m个数据的原数据集上有放回的抽取m个数据,而ExtraTree算法是直接用原数据集训练。
②随机森林在选择划分特征点的时候会和传统决策树一样,会基于信息增益、信息增益率、基尼系数、均方差等原则来选择最优特征值;而ExtraTree会随机的选择一个特征值来划分决策树。
TRTE算法
不重要,了解一下即可
官解:TRTE是一种非监督的数据转化方式。对特征属性重新编码,将低维的数据集映射到高维,从而让映射到高维的数据更好的应用于分类回归模型。
划分标准为方差
看例子吧直接:

IForest
IForest是一种异常点检测算法,使用类似RF的方式来检测异常点
此算法比较坑,适应性不强。
1.在随机采样的过程中,一般只需要少量数据即可;
•2.在进行决策树构建过程中,IForest算法会随机选择一个划分特征,并对划分特征随机选择一个划分阈值;
•3.IForest算法构建的决策树一般深度max_depth是比较小的。
此算法可以用,但此算法连创作者本人也无法完整的解释原理。
RF(随机森林)的主要优点:
●1.训练可以并行化,对于大规模样本的训练具有速度的优势;
●2.由于进行随机选择决策树划分特征列表,这样在样本维度比较高的时候,仍然具有比较高的训练性能;
●3.可以给出各个特征的重要性列表;
●4.由于存在随机抽样,训练出来的模型方差小,泛化能力强;
●5. RF实现简单;
●6.对于部分特征的缺失不敏感。
RF的主要缺点:
●1.在某些噪音比较大的特征上(数据特别异常情况),RF模型容易陷入过拟合;
●2.取值比较多的划分特征对RF的决策会产生更大的影响,从而有可能影响模型的
效果。
随机树主要参数,划线部分为主要调整的参数

机器学习——Bagging与随机森林算法及其变种的更多相关文章
- Bagging与随机森林算法原理小结
在集成学习原理小结中,我们讲到了集成学习有两个流派,一个是boosting派系,它的特点是各个弱学习器之间有依赖关系.另一种是bagging流派,它的特点是各个弱学习器之间没有依赖关系,可以并行拟合. ...
- Bagging与随机森林(RF)算法原理总结
Bagging与随机森林算法原理总结 在集成学习原理小结中,我们学习到了两个流派,一个是Boosting,它的特点是各个弱学习器之间存在依赖和关系,另一个是Bagging,它的特点是各个弱学习器之间没 ...
- 机器学习 —— 决策树及其集成算法(Bagging、随机森林、Boosting)
本文为senlie原创,转载请保留此地址:http://www.cnblogs.com/senlie/ 决策树--------------------------------------------- ...
- Python机器学习笔记——随机森林算法
随机森林算法的理论知识 随机森林是一种有监督学习算法,是以决策树为基学习器的集成学习算法.随机森林非常简单,易于实现,计算开销也很小,但是它在分类和回归上表现出非常惊人的性能,因此,随机森林被誉为“代 ...
- 机器学习回顾篇(12):集成学习之Bagging与随机森林
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- R语言︱机器学习模型评估方案(以随机森林算法为例)
笔者寄语:本文中大多内容来自<数据挖掘之道>,本文为读书笔记.在刚刚接触机器学习的时候,觉得在监督学习之后,做一个混淆矩阵就已经足够,但是完整的机器学习解决方案并不会如此草率.需要完整的评 ...
- 机器学习总结(二)bagging与随机森林
一:Bagging与随机森林 与Boosting族算法不同的是,Bagging和随机森林的个体学习器之间不存在强的依赖关系,可同时生成并行化的方法. Bagging算法 bagging的算法过程如下: ...
- 机器学习相关知识整理系列之二:Bagging及随机森林
1. Bagging的策略 从样本集中重采样(有放回)选出\(n\)个样本,定义子样本集为\(D\): 基于子样本集\(D\),所有属性上建立分类器,(ID3,C4.5,CART,SVM等): 重复以 ...
- R语言︱决策树族——随机森林算法
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:有一篇<有监督学习选择深度学习 ...
随机推荐
- 2019-9-18-WPF-笔刷绑定不上可能的原因
title author date CreateTime categories WPF 笔刷绑定不上可能的原因 lindexi 2019-09-18 09:46:14 +0800 2019-9-18 ...
- Kubernetes弹性伸缩全场景解读(五) - 定时伸缩组件发布与开源
前言 容器技术的发展让软件交付和运维变得更加标准化.轻量化.自动化.这使得动态调整负载的容量变成一件非常简单的事情.在kubernetes中,通常只需要修改对应的replicas数目即可完成.当负载的 ...
- @loj - 2865@ 「IOI2018」狼人
目录 @description@ @solution@ @accepted code@ @details@ @description@ 在日本的茨城县内共有 N 个城市和 M 条道路.这些城市是根据人 ...
- 从HelloWorld看Knative Serving代码实现
摘要: Knative Serving以Kubernetes和Istio为基础,支持无服务器应用程序和函数的部署并提供服务.我们从部署一个HelloWorld示例入手来分析Knative Servin ...
- HZOJ 大佬(kat)
及其水水水的假期望(然而我已经被期望吓怕了……). 数据范围及其沙雕导致丢掉5分…… 因为其实每天的期望是一样的,考虑分开. f[i][j]表示做k道题,难度最大为j的概率. 则f[i][j]=(f[ ...
- PHP 网站大流量与高并发的解决方法
php 网站如何应对大流量与高并发呢? 首先,确认服务器硬件是否足够支持当前的流量. 普通的P4服务器一般最多能支持每天10万地理IP,如果访问量比这个还要大,则请配置一台更高性能的专用服务器. 否则 ...
- poj 1066 Treasure Hunt (Geometry + BFS)
1066 -- Treasure Hunt 题意是,在一个金字塔中有一个宝藏,金字塔里面有很多的墙,要穿过墙壁才能进入到宝藏所在的地方.可是因为某些原因,只能在两个墙壁的交点连线的中点穿过墙壁.问最少 ...
- oracle等式比较和范围比较
当WHERE子句中有索引列, ORACLE不能合并它们,ORACLE将用范围比较. 举例: DEPTNO上有一个非唯一性索引,EMP_CAT也有一个非唯一性索引. SELECT ENAME FROM ...
- H3C 网络接口层
- 【b801】笨小猴
Time Limit: 1 second Memory Limit: 50 MB [问题描述] 笨小猴的词汇量很小,所以每次做英语选择题的时候都很头疼.但是他找到了一种方法,经试验证明,用这种方法去选 ...