Kafka Streams详细
概述
1 Kafka Streams
Kafka Streams。Apache Kafka开源项目的一个组成部分。是一个功能强大,易于使用的库。用于在Kafka上构建高可分布式、拓展性,容错的应用程序。
2 Kafka Streams特点
1)功能强大
高扩展性,弹性,容错
2)轻量级
无需专门的集群
一个库,而不是框架
3)完全集成
100%的Kafka 0.10.0版本兼容
易于集成到现有的应用程序
4)实时性
毫秒级延迟
并非微批处理
窗口允许乱序数据
允许迟到数据
3 为什么要有Kafka Stream
当前已经有非常多的流式处理系统,最知名且应用最多的开源流式处理系统有Spark Streaming和Apache Storm。Apache Storm发展多年,应用广泛,提供记录级别的处理能力,当前也支持SQL on Stream。而Spark Streaming基于Apache Spark,可以非常方便与图计算,SQL处理等集成,功能强大,对于熟悉其它Spark应用开发的用户而言使用门槛低。另外,目前主流的Hadoop发行版,如Cloudera和Hortonworks,都集成了Apache Storm和Apache Spark,使得部署更容易。
既然Apache Spark与Apache Storm拥用如此多的优势,那为何还需要Kafka Stream呢?笔者认为主要有如下原因。
第一,Spark和Storm都是流式处理框架,而Kafka Stream提供的是一个基于Kafka的流式处理类库。框架要求开发者按照特定的方式去开发逻辑部分,供框架调用。开发者很难了解框架的具体运行方式,从而使得调试成本高,并且使用受限。而Kafka Stream作为流式处理类库,直接提供具体的类给开发者调用,整个应用的运行方式主要由开发者控制,方便使用和调试。
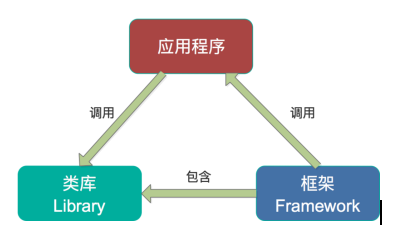
第二,虽然Cloudera与Hortonworks方便了Storm和Spark的部署,但是这些框架的部署仍然相对复杂。而Kafka Stream作为类库,可以非常方便的嵌入应用程序中,它对应用的打包和部署基本没有任何要求。
第三,就流式处理系统而言,基本都支持Kafka作为数据源。例如Storm具有专门的kafka-spout,而Spark也提供专门的spark-streaming-kafka模块。事实上,Kafka基本上是主流的流式处理系统的标准数据源。换言之,大部分流式系统中都已部署了Kafka,此时使用Kafka Stream的成本非常低。
第四,使用Storm或Spark Streaming时,需要为框架本身的进程预留资源,如Storm的supervisor和Spark on YARN的node manager。即使对于应用实例而言,框架本身也会占用部分资源,如Spark Streaming需要为shuffle和storage预留内存。但是Kafka作为类库不占用系统资源。
第五,由于Kafka本身提供数据持久化,因此Kafka Stream提供滚动部署和滚动升级以及重新计算的能力。
第六,由于Kafka Consumer Rebalance机制,Kafka Stream可以在线动态调整并行度。
Kafka Streams详细的更多相关文章
- Confluent Platform 3.0支持使用Kafka Streams实现实时的数据处理(最新版已经是3.1了,支持kafka0.10了)
来自 Confluent 的 Confluent Platform 3.0 消息系统支持使用 Kafka Streams 实现实时的数据处理,这家公司也是在背后支撑 Apache Kafka 消息框架 ...
- [翻译]Kafka Streams简介: 让流处理变得更简单
Introducing Kafka Streams: Stream Processing Made Simple 这是Jay Kreps在三月写的一篇文章,用来介绍Kafka Streams.当时Ka ...
- Kafka Streams简介: 让流处理变得更简单
Introducing Kafka Streams: Stream Processing Made Simple 这是Jay Kreps在三月写的一篇文章,用来介绍Kafka Streams.当时Ka ...
- 手把手教你写Kafka Streams程序
本文从以下四个方面手把手教你写Kafka Streams程序: 一. 设置Maven项目 二. 编写第一个Streams应用程序:Pipe 三. 编写第二个Streams应用程序:Line Split ...
- Kafka Streams演示程序
本文从以下六个方面详细介绍Kafka Streams的演示程序: Step 1: 下载代码 Step 2: 启动kafka服务 Step 3: 准备输入topic并启动Kafka生产者 Step 4: ...
- Kafka Streams开发入门(4)
背景 上一篇演示了filter操作算子的用法.今天展示一下如何根据不同的条件谓词(Predicate)将一个消息流实时地进行分流,划分成多个新的消息流,即所谓的流split.有的时候我们想要对消息流中 ...
- Kafka Streams | 流,实时处理和功能
1.目标 在我们之前的Kafka教程中,我们讨论了Kafka中的ZooKeeper.今天,在这个Kafka Streams教程中,我们将学习Kafka中Streams的实际含义.此外,我们将看到Kaf ...
- 翻译 - Kafka Streams 介绍(一)
2019独角兽企业重金招聘Python工程师标准>>> 资料 [原文地址](http://kafka.apache.org/11/documentation/streams/) 正文 ...
- Kafka Streams 剖析
1.概述 Kafka Streams 是一个用来处理流式数据的库,属于Java类库,它并不是一个流处理框架,和Storm,Spark Streaming这类流处理框架是明显不一样的.那这样一个库是做什 ...
随机推荐
- codeforces 1B 模拟
题目大意: 给出两种行列位置的表示方法,一个是Excel表示法,一个是(R,C)坐标表示.给出一种表示,输出另外一种表示. 基本思路: 模拟,首先判断是哪一种表示法,然后转换成另外一种表示方法: 我做 ...
- fzu 1901 next+脑洞
题目大意: 给你一个字符串str,对于每个str长度为p的前缀,如果str[i]==str[p+i](p+i<len),那么我们认为它是一个periodic prefixs.求所有满足题意的前缀 ...
- kubeadm部署多master节点高可用k8s1.16.2
一.架构信息 系统版本:CentOS 7.6 内核:3.10.0‐1062.4.1.el7.x86_64 Kubernetes: v1.16.2 Dockerce: 19.03 推荐硬件配置:2核4 ...
- Python Class (一)
继承 class Character(object): def __init__(self, name): self.health = 100 self.name = name def printNa ...
- Java基础之ArrayList类
一.ArrayList ArrayList继承了AbstractList分别实现了List.RandomAccess(随机访问).Cloneable(可被克隆(复制的意思)). Serializabl ...
- 【leetcode】538. Convert BST to Greater Tree
题目如下: Given a Binary Search Tree (BST), convert it to a Greater Tree such that every key of the orig ...
- leetcode-163周赛-1261-在污染的二叉树中查找元素
题目描述: 方法一: class FindElements: def __init__(self, root: TreeNode): self.d = set() def f(r, x): if r: ...
- layer.msg的使用
源码: layer.msg('只想弱弱提示'); layer.msg('表情提示', {icon: 6}); layer.msg('关闭后想做些什么呢', function(){ //自动执行这里面的 ...
- 泛型(Java 5 开始)
前言 Java 5 开始之前,从集合读取的数据都必须进行类型转换,如果插入错误的数据就会报错. 有了泛型,编译器会自动为你的插入进行转换,并在插入时告知是否插入了类型错误的对象. 将类型由原来的具体的 ...
- thinkphp整合后台模板
将后台模板源码dist文件夹中的所有文件移动到thinkphp view index中 thinkphp的资源文件都不是从view文件夹下读取的 因此需要资源文件asset文件夹和demo文件夹放到t ...