Adaboost入门教程——最通俗易懂的原理介绍(图文实例)
https://blog.csdn.net/px_528/article/details/72963977
写在前面
说到Adaboost,公式与代码网上到处都有,《统计学习方法》里面有详细的公式原理,Github上面有很多实例,那么为什么还要写这篇文章呢?希望从一种更容易理解的角度,来为大家呈现Adaboost算法的很多关键的细节。
本文中暂时没有讨论其数学公式,一些基本公式可以参考《统计学习方法》。
基本原理
Adaboost算法基本原理就是将多个弱分类器(弱分类器一般选用单层决策树)进行合理的结合,使其成为一个强分类器。
Adaboost采用迭代的思想,每次迭代只训练一个弱分类器,训练好的弱分类器将参与下一次迭代的使用。也就是说,在第N次迭代中,一共就有N个弱分类器,其中N-1个是以前训练好的,其各种参数都不再改变,本次训练第N个分类器。其中弱分类器的关系是第N个弱分类器更可能分对前N-1个弱分类器没分对的数据,最终分类输出要看这N个分类器的综合效果。
弱分类器(单层决策树)
Adaboost一般使用单层决策树作为其弱分类器。单层决策树是决策树的最简化版本,只有一个决策点,也就是说,如果训练数据有多维特征,单层决策树也只能选择其中一维特征来做决策,并且还有一个关键点,决策的阈值也需要考虑。
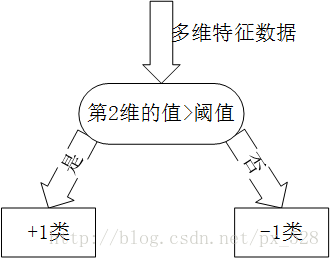
关于单层决策树的决策点,来看几个例子。比如特征只有一个维度时,可以以小于7的分为一类,标记为+1,大于(等于)7的分为另一类,标记为-1。当然也可以以13作为决策点,决策方向是大于13的分为+1类,小于(等于)13的分为-1类。在单层决策树中,一共只有一个决策点,所以下图的两个决策点不能同时选取。
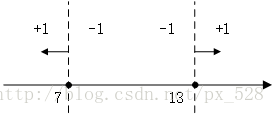
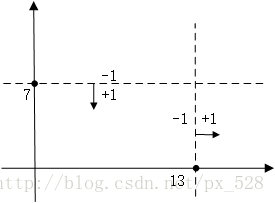
同样的道理,当特征有两个维度时,可以以纵坐标7作为决策点,决策方向是小于7分为+1类,大于(等于)7分类-1类。当然还可以以横坐标13作为决策点,决策方向是大于13的分为+1类,小于13的分为-1类。在单层决策树中,一共只有一个决策点,所以下图的两个决策点不能同时选取。
扩展到三维、四维、N维都是一样,在单层决策树中,一共只有一个决策点,所以只能在其中一个维度中选择一个合适的决策阈值作为决策点。
关于Adaboost的两种权重
Adaboost算法中有两种权重,一种是数据的权重,另一种是弱分类器的权重。其中,数据的权重主要用于弱分类器寻找其分类误差最小的决策点,找到之后用这个最小误差计算出该弱分类器的权重(发言权),分类器权重越大说明该弱分类器在最终决策时拥有更大的发言权。
Adaboost数据权重与弱分类器
刚刚已经介绍了单层决策树的原理,这里有一个问题,如果训练数据保持不变,那么单层决策树找到的最佳决策点每一次必然都是一样的,为什么呢?因为单层决策树是把所有可能的决策点都找了一遍然后选择了最好的,如果训练数据不变,那么每次找到的最好的点当然都是同一个点了。
所以,这里Adaboost数据权重就派上用场了,所谓“数据的权重主要用于弱分类器寻找其分类误差最小的点”,其实,在单层决策树计算误差时,Adaboost要求其乘上权重,即计算带权重的误差。
举个例子,在以前没有权重时(其实是平局权重时),一共10个点时,对应每个点的权重都是0.1,分错1个,错误率就加0.1;分错3个,错误率就是0.3。现在,每个点的权重不一样了,还是10个点,权重依次是[0.01,0.01,0.01,0.01,0.01,0.01, 0.01,0.01,0.01,0.91],如果分错了第1一个点,那么错误率是0.01,如果分错了第3个点,那么错误率是0.01,要是分错了最后一个点,那么错误率就是0.91。这样,在选择决策点的时候自然是要尽量把权重大的点(本例中是最后一个点)分对才能降低误差率。由此可见,权重分布影响着单层决策树决策点的选择,权重大的点得到更多的关注,权重小的点得到更少的关注。
在Adaboost算法中,每训练完一个弱分类器都就会调整权重,上一轮训练中被误分类的点的权重会增加,在本轮训练中,由于权重影响,本轮的弱分类器将更有可能把上一轮的误分类点分对,如果还是没有分对,那么分错的点的权重将继续增加,下一个弱分类器将更加关注这个点,尽量将其分对。
这样,达到“你分不对的我来分”,下一个分类器主要关注上一个分类器没分对的点,每个分类器都各有侧重。
Adaboost分类器的权重
由于Adaboost中若干个分类器的关系是第N个分类器更可能分对第N-1个分类器没分对的数据,而不能保证以前分对的数据也能同时分对。所以在Adaboost中,每个弱分类器都有各自最关注的点,每个弱分类器都只关注整个数据集的中一部分数据,所以它们必然是共同组合在一起才能发挥出作用。所以最终投票表决时,需要根据弱分类器的权重来进行加权投票,权重大小是根据弱分类器的分类错误率计算得出的,总的规律就是弱分类器错误率越低,其权重就越高。
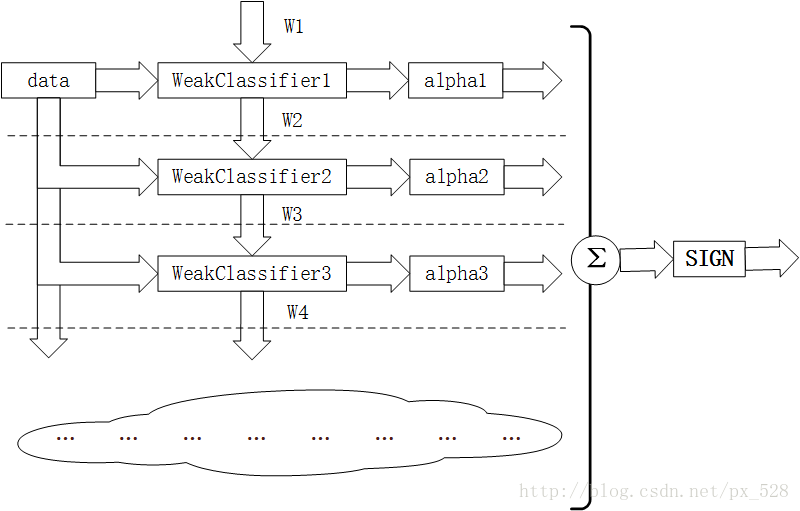
图解Adaboost分类器结构
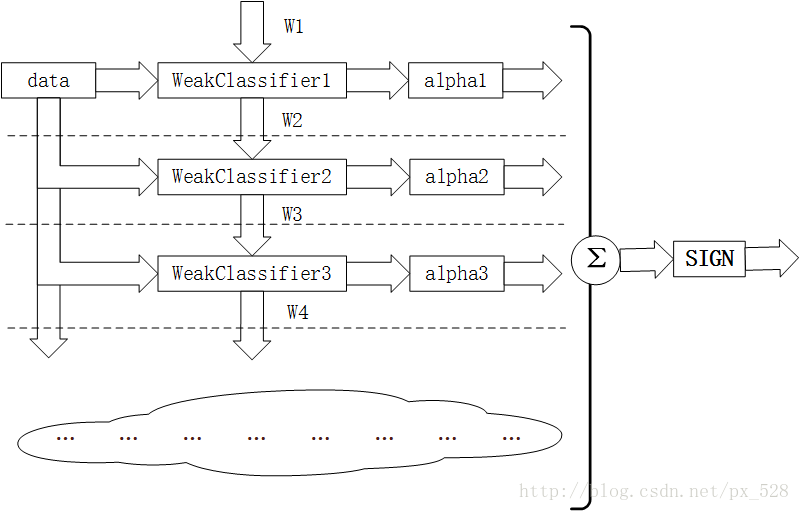
如图所示为Adaboost分类器的整体结构。从右到左,可见最终的求和与符号函数,再看到左边求和之前,图中的虚线表示不同轮次的迭代效果,第1次迭代时,只有第1行的结构,第2次迭代时,包括第1行与第2行的结构,每次迭代增加一行结构,图下方的“云”表示不断迭代结构的省略。
第i轮迭代要做这么几件事:
1. 新增弱分类器WeakClassifier(i)与弱分类器权重alpha(i)
2. 通过数据集data与数据权重W(i)训练弱分类器WeakClassifier(i),并得出其分类错误率,以此计算出其弱分类器权重alpha(i)
3. 通过加权投票表决的方法,让所有弱分类器进行加权投票表决的方法得到最终预测输出,计算最终分类错误率,如果最终错误率低于设定阈值(比如5%),那么迭代结束;如果最终错误率高于设定阈值,那么更新数据权重得到W(i+1)
图解Adaboost加权表决结果
关于最终的加权投票表决,举几个例子:
比如在一维特征时,经过3次迭代,并且知道每次迭代后的弱分类器的决策点与发言权,看看如何实现加权投票表决的。
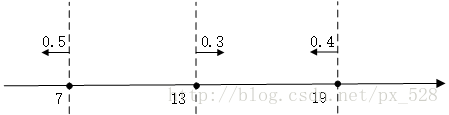
如图所示,3次迭代后得到了3个决策点,
最左边的决策点是小于(等于)7的分为+1类,大于7的分为-1类,且分类器的权重为0.5;
中间的决策点是大于(等于)13的分为+1类,小于13分为-1类,权重0.3;
最右边的决策点是小于(等于19)的分为+1类,大于19分为-1类,权重0.4。
对于最左边的弱分类器,它的投票表示,小于(等于)7的区域得0.5,大与7得-0.5,同理对于中间的分类器,它的投票表示大于(等于)13的为0.3,小于13分为-0.3,最右边的投票结果为小于(等于19)的为0.4,大于19分为-0.4,如下图:
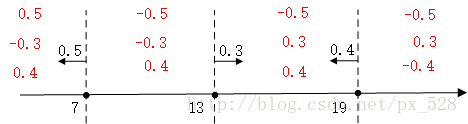
求和可得:
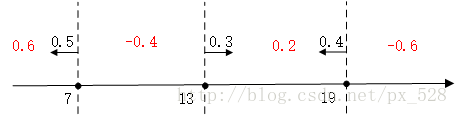
最后进行符号函数转化即可得到最终分类结果:
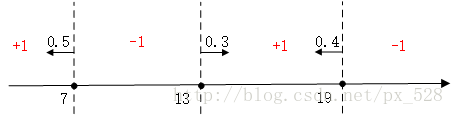
更加直观的,来看一个更复杂的例子。对于二维也是一样,刚好有一个实例可以分析一下,原始数据分布如下图:
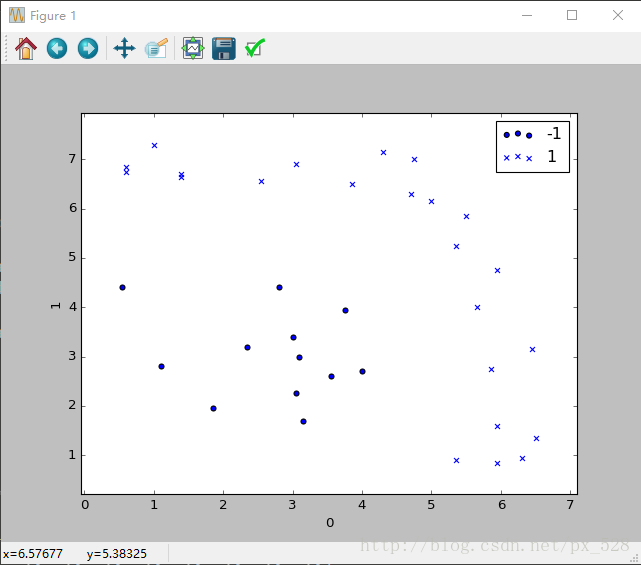
Adaboost分类器试图把两类数据分开,运行一下程序,显示出决策点,如下图:
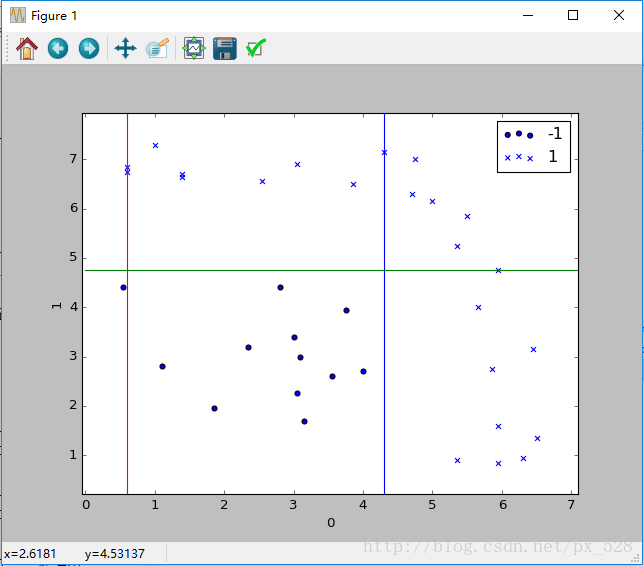
这样一看,似乎是分开了,不过具体参数是怎样呢?查看程序的输出,可以得到如其决策点与弱分类器权重,在图中标记出来如下:
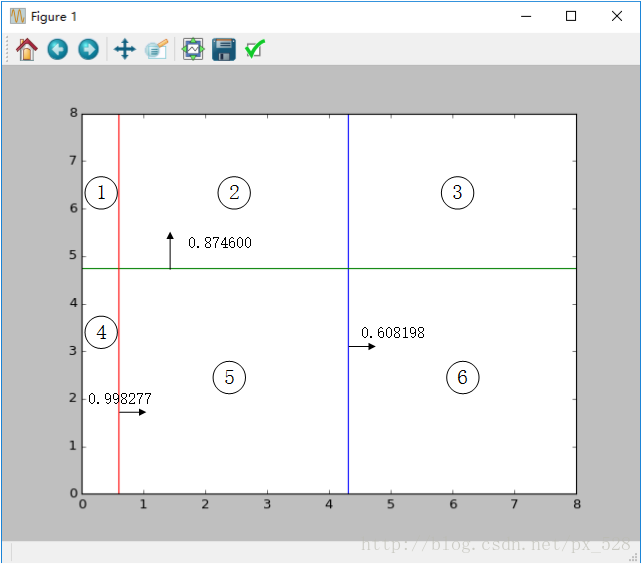
图中被分成了6分区域,每个区域对应的类别就是:
1号:sign(-0.998277+0.874600-0.608198)=-1
2号:sign(+0.998277+0.874600-0.608198)=+1
3号:sign(+0.998277+0.874600+0.608198)=+1
4号:sign(-0.998277-0.874600-0.608198)=-1
5号:sign(+0.998277-0.874600-0.608198)=-1
6号:sign(+0.998277-0.874600+0.608198)=+1
其中sign(x)是符号函数,正数返回1负数返回-1。
最终得到如下效果:
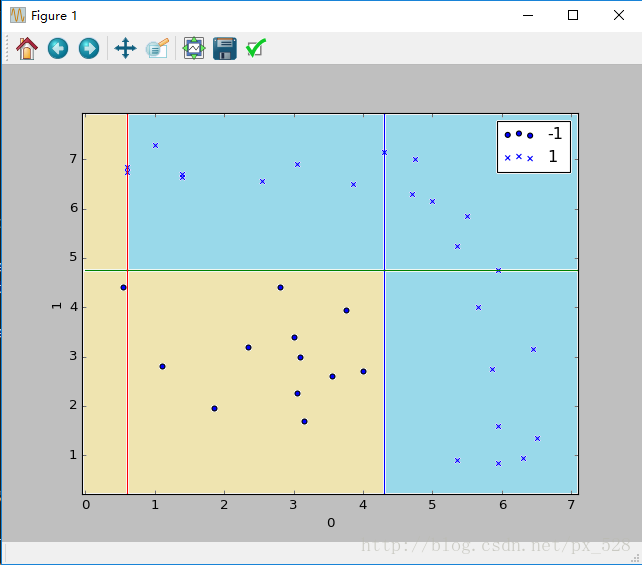
通过这两个例子,相信你已经明白了Adaboost算法加权投票时怎么回事儿了。
总结
说了这么多,也举了这么多例子,就是为了让你从细节上明白Adaboost的基本原理,博主认为理解Adaboost的两种权重的关系是理解Adaboost算法的关键所在。
Adaboost入门教程——最通俗易懂的原理介绍(图文实例)的更多相关文章
- esri-leaflet入门教程(1)-leaflet介绍
esri-leaflet入门教程(1)-esri leaflet介绍 by 李远祥 关于leaflet,可能很多人比较陌生,如果搭上esri几个字母,可能会有更多的人关注.如果没有留意过leaflet ...
- VXLAN 基础教程:VXLAN 协议原理介绍
VXLAN(Virtual eXtensible Local Area Network,虚拟可扩展局域网),是一种虚拟化隧道通信技术.它是一种 Overlay(覆盖网络)技术,通过三层的网络来搭建虚拟 ...
- Dapper入门教程(一)——Dapper介绍
Dapper是什么? Dpper是一款.Net平台简单(Simple)的对象映射库,并且Dapper拥有着"微型ORM之王"的称号.就速度而言与手写ADO.NET SqlDateR ...
- python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架 Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬 ...
- 最新hadoop入门教程汇总篇(附详细图文步骤)
关于hadoop的分享此前一直都是零零散散的想到什么就写什么,整体写的比较乱吧.最近可能还算好的吧,毕竟花了两周的时间详细的写完的了hadoop从规划到环境安装配置等全部内容.写过程不是很难,最烦的可 ...
- HTML5+CSS3前端入门教程---从0开始通过一个商城实例手把手教你学习PC端和移动端页面开发第5章CSS盒子模型
本教程案例在线演示 有路网PC端 有路网移动端 教程配套源码资源 教程配套源码资源 div div 可定义文档中的分区(division). div 标签可以把网页分割为独立的.不同的部分. 可以看成 ...
- Docker入门教程(一)介绍
http://dockone.io/article/101 Docker入门教程(一)介绍 [编者的话]DockerOne组织翻译了Flux7的Docker入门教程,本文是系列入门教程的第一篇,介绍了 ...
- Docker入门教程(二)命令
Docker入门教程(二)命令 [编者的话]DockerOne组织翻译了Flux7的Docker入门教程,本文是系列入门教程的第二篇,介绍了Docker的基本命令以及命令的用法和功能. 在Docker ...
- Python 数据处理库 pandas 入门教程
Python 数据处理库 pandas 入门教程2018/04/17 · 工具与框架 · Pandas, Python 原文出处: 强波的技术博客 pandas是一个Python语言的软件包,在我们使 ...
随机推荐
- Starting MySQL...The server quit without updating PID file [失败]local/mysql/data/localhost.localdomain.pid报错
在添加命令自动补全的时候mysql启动失败 这是原配 # For advice on how to change settings please see # http://dev.mysql.com/ ...
- 20145317 网络对抗技术 逆向与Bof基础
20145317 网络对抗技术 逆向与Bof基础 实践要求 1. 掌握NOP,JNE,JE,JMP,CMP汇编指令的机器码 2. 掌握反汇编与十六进制编程器 3. 能正确修改机器指令改变程序执行流程 ...
- String和int互相转换,String转float
String-->int int a=Integer.parseIn(str); int-->String String s= a+""; String-->fl ...
- 【运行错误】Uncaught DOMException: Blocked a frame with origin "null" from accessing a cross-origin frame.
代码如下: <html> <head> <script> /*window.frames[]可以通过下标或名称访问单独的frame*/ window.onload= ...
- LOJ#2632. 「BalticOI 2011 Day1」打开灯泡 Switch the Lamp On
题目描述 译自 BalticOI 2011 Day1 T3「Switch the Lamp On」有一种正方形的电路元件,在它的两组相对顶点中,有一组会用导线连接起来,另一组则不会.有 N×M 个这样 ...
- CSU 1805 Three Capitals(矩阵树定理+Best定理)
http://acm.csu.edu.cn/csuoj/problemset/problem?pid=1805 题意: A和B之间有a条边,A和G之间有b条边,B和G之间有c条边.现在从A点出发走遍所 ...
- Java擦除
概述: Java泛型在使用过程有诸多的问题,如不存在List<String>.class, List<Integer>不能赋值给List<Number>(不可协变) ...
- 遇到Io阻塞时会切换任务之【爬虫版】
#! /usr/bin/env python3 # -*- coding:utf- -*- from urllib import request import gevent,time from gev ...
- XML_CPP_资料_libXml2_01_Code_ZC(?.pro)
ZC:最下面有 ?.pro文件的设置写法 ZC: Win7x64,qt-opensource-windows-x86-msvc2010_opengl-5.3.2.exe,cn_visual_studi ...
- Android开机广播和关机广播
有些时候我们需要我们的程序在系统开机后能自动运行,这个时候我们可以使用Android中的广播机制,编写一个继承BroadcastReceiver的类,接受系统启动关闭广播.代码如下: /** *@au ...