Nodejs -- 使用koa2搭建数据爬虫
当前爬虫项目开发所需中间件:
cheerio: 则能够对请求结果进行解析,解析方式和jquery的解析方式几乎完全相同 cheerio中文文档 开发参考node - cheerio模块
superagent: 能够实现主动发起get/post/delete等请求
superagent-charset: 解决爬虫数据中文乱码问题,早期版本单独使用,现配合superagent使用
koa2: 搭建服务器环境等等
koa-router: koa路由,用于根据路由访问对应代码块,逻辑编写等作用(把他理解为像日常API接口就好)
knex: 操作数据库,支持多种数据库,这里使用mysql,需要mysql中间件 开发参考knex笔记
搭建开发环境
- 在项目根目录下
npm init一路回车,初始化项目环境,出现package.json文件,然后执行以下命令安装项目依赖
npm i --save cheerio superagent superagent-charset koa-router koa knex mysql
- 在项目根目录下创建app.js文件,编写coding
const Koa = require('koa'),
Router = require('koa-router'),
cheerio = require('cheerio'),
charset = require('superagent-charset'),
superagent = charset(require('superagent')),
app = new Koa(),
router = new Router();
- 然后编写路由和搭建服务器环境
router.get('/', function(ctx, next) {
ctx.body = "搭建好了,开始吧";
});
app
.use(router.routes())
.use(router.allowedMethods());
app.listen(3010, () => {
console.log('[服务已开启,访问地址为:] http://127.0.0.1:3010/');
});
- 启动服务
node app.js, 打开浏览器http://127.0.0.1:3010/ 就可以访问了 如看到搭建好了,开始吧就意味着搭建环境success
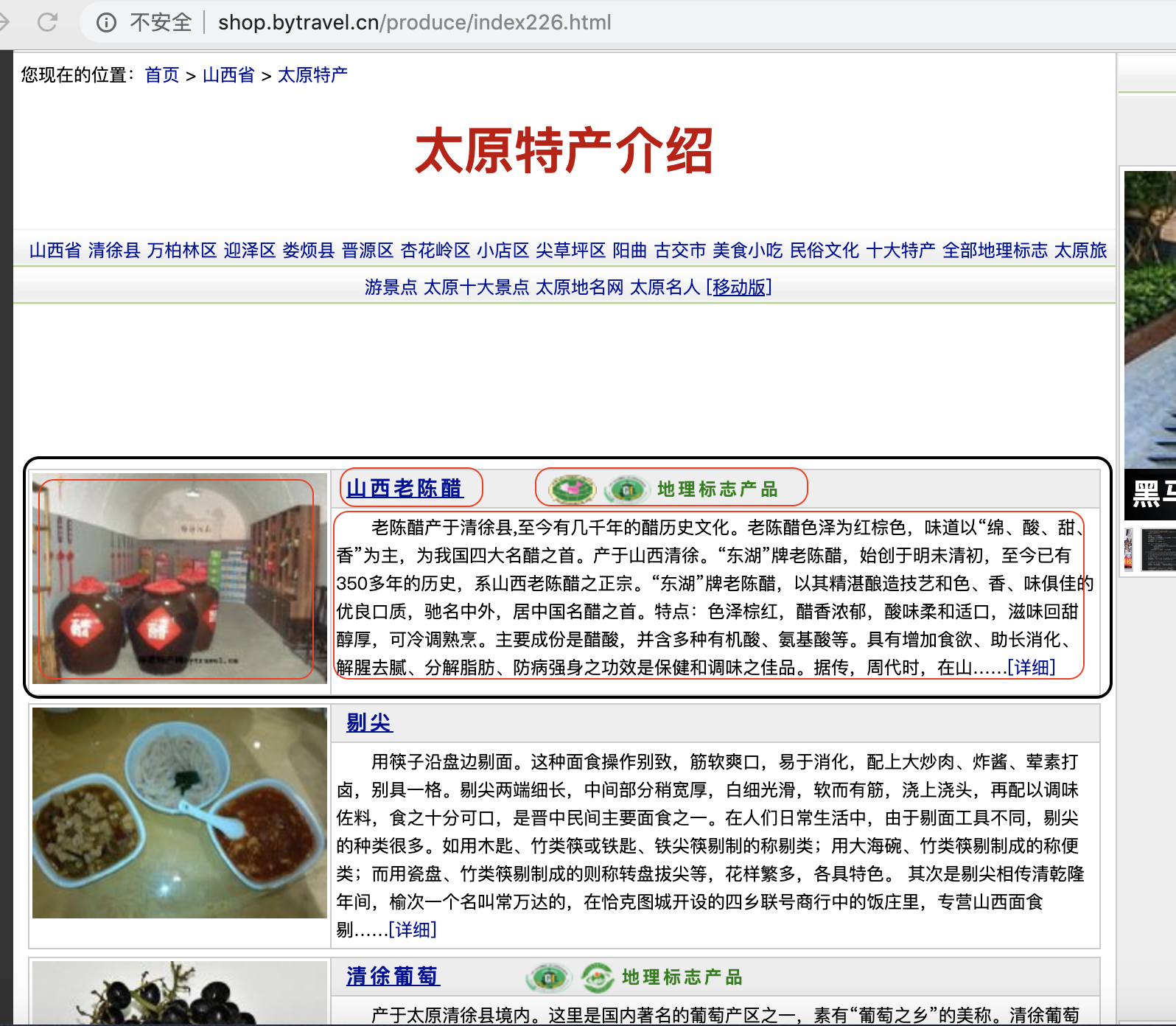
爬虫-目标网站
const Koa = require('koa'),
Router = require('koa-router'),
cheerio = require('cheerio'),
charset = require('superagent-charset'),
superagent = charset(require('superagent')),
app = new Koa(),
router = new Router();
let arr;
router.get('/', (ctx, next) => {
url = 'http://shop.bytravel.cn/produce/index226.html'; //target地址
superagent.get(url)
.charset('gbk') // 当前页面编码格式
.buffer(true)
.end((err, data) => { //页面获取到的数据
if (err) {
// return next(err);
console.log('页面不存在', err)
}
let html = data.text,
$ = cheerio.load(html, {
decodeEntities: false,
ignoreWhitespace: false,
xmlMode: false,
lowerCaseTags: false
}), //用cheerio解析页面数据
obj = {};
arr = [];
// cheerio的使用类似jquery的操作
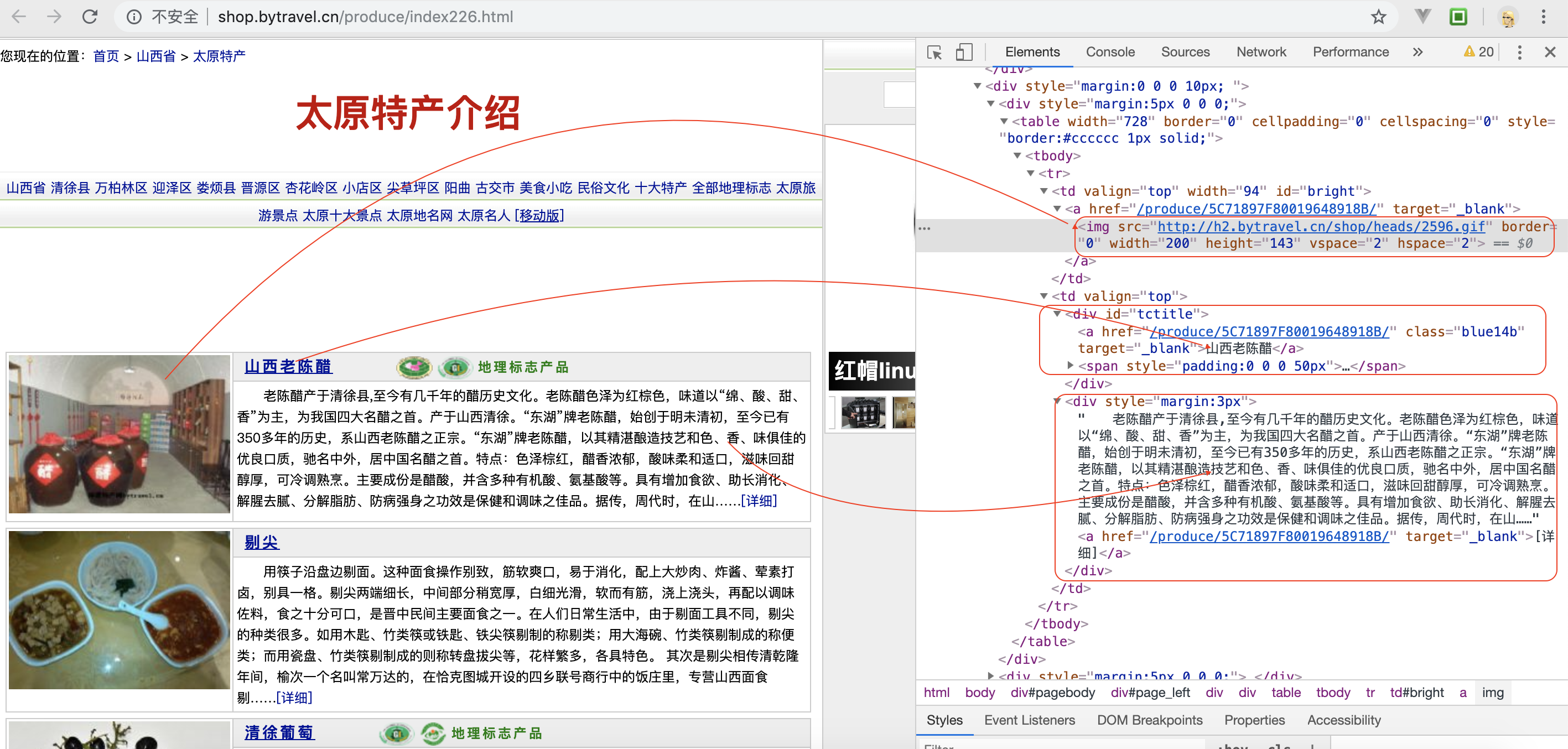
$("table tbody").each((index, element) => {
let $element = $(element);
$element.find('#tctitle').next().find('a').addClass('link').attr('class', 'link').text('')
arr.push({
'title': $element.find('a.blue14b').text(),
'image': $element.find('#bright img').attr('src'),
'summary': $element.find('#tctitle').next().text(),
'is_cgiia': $element.find('#tctitle font').attr('color') === 'green' ? 1 : 0
})
})
})
ctx.body = arr
// console.log(arr)
})
app
.use(router.routes())
.use(router.allowedMethods());
app.listen(3010, () => {
console.log('[服务已开启,访问地址为:] http://127.0.0.1:3010/');
});
命令行重启服务
node app.js, 页面出现一个数组,有大量数据,success;
- 注: 如果出现乱码,可能就是代码的编码格式和要抓取目标页面的编码格式不一样导致的,需要留心下;
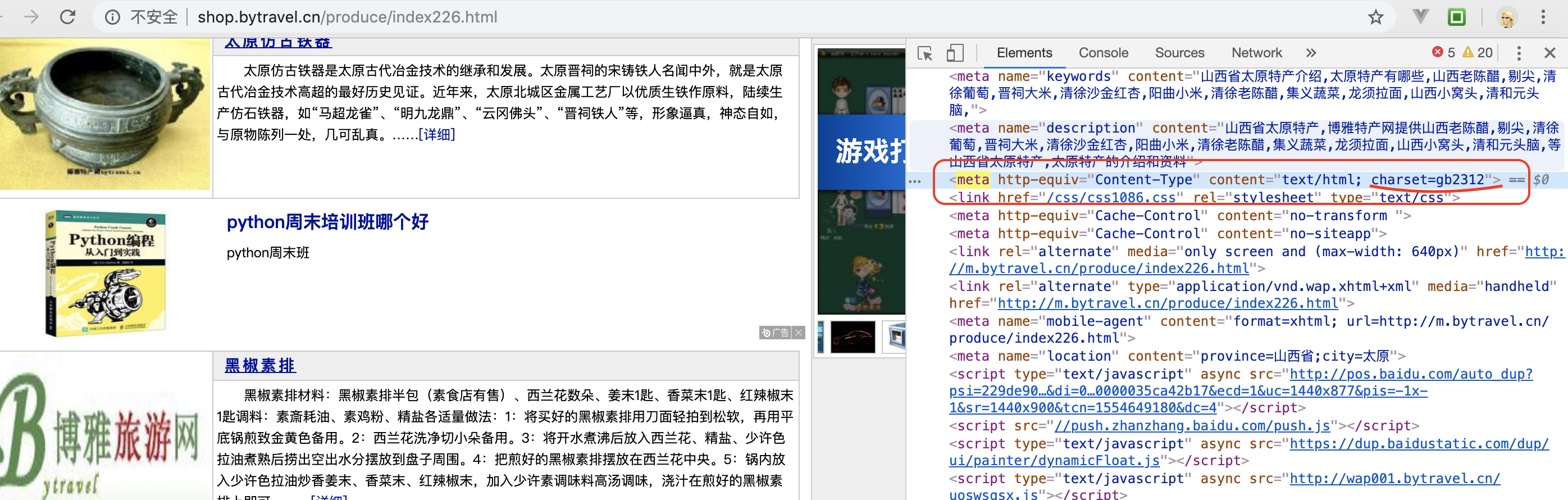
- 当前目标网站编码-- gb2312
- 如果是utf-8 可以 不使用 superagent-charset
superagent.get(url)
.charset('gbk') // 当前页面编码格式
.buffer(true)
.end(async (err, data) => { //页面获取到的数据
······
})
分析页面数据
- 通过cheerio在服务器端需要对DOM进行操作解析页面获取数据
$("table tbody").each((index, element) => {
let $element = $(element);
$element.find('#tctitle').next().find('a').addClass('link').attr('class', 'link').text(''); //去掉简介中链接接【详情】
arr.push({
'title': $element.find('a.blue14b').text(),
'image': $element.find('#bright img').attr('src'),
'summary': $element.find('#tctitle').next().text(),
'is_cgiia': $element.find('#tctitle font').attr('color') === 'green' ? 1 : 0
})
})
数据库
sudo npm install knex mysql --save
当前自定义数据库
native_symbol,数据表products
CREATE DATABASE native_symbol;
CREATE TABLE `products` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '编号',
`title` varchar(100) NOT NULL COMMENT '名称',
`image` varchar(100) NOT NULL COMMENT '图片',
`summary` varchar(1000) NOT NULL COMMENT '简介',
`tags` varchar(100) DEFAULT NULL COMMENT '标签',
`is_cgiia` tinyint(1) DEFAULT NULL COMMENT '是否是地标特产',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=20 DEFAULT CHARSET=utf8;
- 初始化(knex配置连接)
var knex = require('knex')({
client: 'mysql', //指明数据库类型,还可以是pg,sqlite3等等
connection: { //指明连接参数
host: '127.0.0.1',
user: 'root',
password: 'root',
database: 'native_symbol'
},
debug: true, //指明是否开启debug模式,默认为true表示开启
pool: { //指明数据库连接池的大小,默认为{min: 2, max: 10}
min: 0,
max: 7,
},
acquireConnectionTimeout: 10000, //指明连接计时器大小,默认为60000ms
migrations: {
tableName: 'migrations' //数据库迁移,可选
}
});
把数据库类型和连接相关的参数配置好之后,才可以正确的连接到数据库,connection的配置信息通常写到config文件中。
目前node开发服务端最优解决异步回调是
koa2 + es7(async/await)
- 例如;向users表中写入数据
// 写入库
knex('users')
.returning('id')
.insert({
name: 'charblus',
age: 18,
sex: 1
})
.then(res => {
console.log('success', res)
})
}
$("table tbody").each((index, element) => {
let $element = $(element);
$element.find('#tctitle').next().find('a').addClass('link').attr('class', 'link').text('')
arr.push({
'title': $element.find('a.blue14b').text(),
'image': $element.find('#bright img').attr('src'),
'summary': $element.find('#tctitle').next().text(),
'is_cgiia': $element.find('#tctitle font').attr('color') === 'green' ? 1 : 0
})
})
for (let i of arr) {
const findRes = await knex('products').select().where('title', i.title)
if (findRes.length) {
console.log('数据已存在')
} else {
// 写入库
await knex('products')
.returning('id')
.insert(i)
.then(res => {
console.log('success', res)
})
}
}
这里读写数据库是异步操作 使用
async/await, 如上knex读写数据库时都用了await,需要在当前函数前加async
- 根据目标网站链接的特性,这里加了个定时器,修改URL地址,并重新superagent请求数据,cheerio分析数据,knex存入数据
app.js
const Koa = require('koa'),
Router = require('koa-router'),
cheerio = require('cheerio'),
charset = require('superagent-charset'),
superagent = charset(require('superagent')),
app = new Koa(),
router = new Router();
let arr;
var knex = require('knex')({
client: 'mysql', //指明数据库类型,还可以是pg,sqlite3等等
connection: { //指明连接参数
host: '127.0.0.1',
user: 'root',
password: 'root',
database: 'native_symbol'
},
debug: true, //指明是否开启debug模式,默认为true表示开启
pool: { //指明数据库连接池的大小,默认为{min: 2, max: 10}
min: 0,
max: 7,
},
acquireConnectionTimeout: 10000, //指明连接计时器大小,默认为60000ms
migrations: {
tableName: 'migrations' //数据库迁移,可选
}
});
var idx = 100;
router.get('/', (ctx, next) => {
var timer = setInterval(() => {
idx++;
if (idx > 10000) {
clearInterval(timer)
return
}
url = `http://shop.bytravel.cn/produce/index${idx}.html`; //爬虫地址
timePlay(url)
console.log('页面抓包记录', idx)
}, 100);
timePlay = (url) => {
superagent.get(url)
.charset('gbk')
.buffer(true)
.end(async (err, data) => { //页面获取到的数据
// if (err) {
// // return next(err);
// console.log('页面不存在', err)
// }
let html = data.text,
$ = cheerio.load(html, {
decodeEntities: false,
ignoreWhitespace: false,
xmlMode: false,
lowerCaseTags: false
}), //用cheerio解析页面数据
obj = {};
arr = [];
$("table tbody").each((index, element) => {
let $element = $(element);
$element.find('#tctitle').next().find('a').addClass('link').attr('class', 'link').text('')
arr.push({
'title': $element.find('a.blue14b').text(),
'image': $element.find('#bright img').attr('src'),
'summary': $element.find('#tctitle').next().text(),
'is_cgiia': $element.find('#tctitle font').attr('color') === 'green' ? 1 : 0
})
})
for (let i of arr) {
const findRes = await knex('products').select().where('title', i.title)
if (findRes.length) {
console.log('数据已存在')
} else {
// 写入库
await knex('products')
.returning('id')
.insert(i)
.then(res => {
console.log('success', res)
})
}
}
});
}
ctx.body = arr;
// console.log(arr)
});
app
.use(router.routes())
.use(router.allowedMethods());
app.listen(3010, () => {
console.log('[服务已开启,访问地址为:] http://127.0.0.1:3010/');
});
Nodejs -- 使用koa2搭建数据爬虫的更多相关文章
- 使用Node.js搭建数据爬虫crawler
0. 通用爬虫框架包括: (1) 将爬取url加入队列,并获取指定url的前端资源(crawler爬虫框架主要使用Crawler类进行抓取网页) (2)解析前端资源,获取指定所需字段的值,即获取有价值 ...
- iKcamp团队制作|基于Koa2搭建Node.js实战项目教学(含视频)☞ 环境准备
安装搭建项目的开发环境 视频地址:https://www.cctalk.com/v/15114357764004 文章 Koa 起手 - 环境准备 由于 koa2 已经开始使用 async/await ...
- nodejs实现最简单的爬虫
本文将以抓取百度搜索结果中关键词的相关搜索为例子,教会大家以nodejs制作最简单的爬虫: 开始之前呢,先来个公众号求粉: 将使用的node模块及属性介绍: request: ...
- 搭建pyspider爬虫服务
1. 环境准备 首先yum更新 yum update -y 安装开发编译工具 yum install gcc gcc-c++ -y 安装依赖库 yum install python-pip pytho ...
- iKcamp|基于Koa2搭建Node.js实战(含视频)☞ 记录日志
沪江CCtalk视频地址:https://www.cctalk.com/v/15114923883523 log 日志中间件 最困难的事情就是认识自己. 在一个真实的项目中,开发只是整个投入的一小部分 ...
- iKcamp|基于Koa2搭建Node.js实战(含视频)☞ 解析JSON
视频地址:https://www.cctalk.com/v/15114923886141 JSON 数据 我颠倒了整个世界,只为摆正你的倒影. 前面的文章中,我们已经完成了项目中常见的问题,比如 路由 ...
- iKcamp|基于Koa2搭建Node.js实战(含视频)☞ 处理静态资源
视频地址:https://www.cctalk.com/v/15114923882788 处理静态资源 无非花开花落,静静. 指定静态资源目录 这里我们使用第三方中间件: koa-static 安装并 ...
- iKcamp|基于Koa2搭建Node.js实战(含视频)☞ 视图Nunjucks
视频地址:https://www.cctalk.com/v/15114923888328 视图 Nunjucks 彩虹是上帝和人类立的约,上帝不会再用洪水灭人. 客户端和服务端之间相互通信,传递的数据 ...
- iKcamp|基于Koa2搭建Node.js实战(含视频)☞ 代码分层
视频地址:https://www.cctalk.com/v/15114923889408 文章 在前面几节中,我们已经实现了项目中的几个常见操作:启动服务器.路由中间件.Get 和 Post 形式的请 ...
随机推荐
- B-tree indexes
High Performance MySQL, Third Edition by Baron Schwartz, Peter Zaitsev, and Vadim Tkachenko http://d ...
- 读取Excel列,转换为String输出(Java实现)
需要导入的jar包 具体实现 public class ColumnToString { public static void main(String[] args) { new ColumnToSt ...
- kubernetes实战(十一):k8s使用openLDAP统一认证
1.基本概念 为了方便管理和集成jenkins,k8s.harbor.jenkins均使用openLDAP统一认证. 2.部署openLDAP 此处将openLDAP部署在k8s上,openLDAP可 ...
- 【F12】谷歌浏览器F12前端调试工具 Console
谷歌浏览器F12前端调试工具 Console 前言 先上图:不知道有多少人发现,在浏览器开发工具的“Console”上的百度首页的关于百度招聘的信息: 今天要给大家介绍的就是是Web前端调试工具中的C ...
- 01_Python 基础课程安排
Python 基础课程安排 目标 明确基础班课程内容 课程清单 序号 内容 目标 01 Linux 基础 让大家对 Ubuntu 的使用从很 陌生 达到 灵活操作 02 Python 基础 涵盖 Py ...
- Shell初学(四)运算符
一.算术运算符 下表列出了常用的算术运算符,假定变量 a 为 10,变量 b 为 20: 运算符 说明 举例 + 加法 `expr $a + $b` 结果为 30. - 减法 `expr $a - $ ...
- 解压赋值及python的一些基础运算
#解压赋值lis=[11,22,33,44,55] money1,money2,money3,money4,money5=lis print(money1,money2,money3,money4,m ...
- 机器学习理论基础学习19---受限玻尔兹曼机(Restricted Boltzmann Machine)
一.背景介绍 玻尔兹曼机 = 马尔科夫随机场 + 隐结点 二.RBM的Representation BM存在问题:inference 精确:untractable: 近似:计算量太大 因此为了使计算简 ...
- unity3d-编辑器结构
1.Porject视图 Project视图主要存放游戏中用到的所有资源文件,常见的资源包括: 游戏脚本.预设.材质.动画.自定义字体.纹理.物理材质和GUI皮肤.这些资源需要 赋予Hierarchy视 ...
- 树结构数据的展示和编辑-zTree树插件的简单使用
最近在项目当中遇到一个需求,需要以树结构的方式展示一些数据,并可对每一个树节点做内容的编辑以及树节点的添加和删除,刚好听说有zTree这个插件可以实现这样的需求,所以在项目的这个需求完成之后,在博客里 ...