request-2高级用法
会话对象
会话对象让你能够跨请求保持某些参数。它也会在同一个session示例发出的所有请求之间保持cookie
cookie与session的区别
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗,考虑到安全应当使用session。
3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,考虑到减轻服务器性能方面,应当使用cookie。
4、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
5、可以考虑将登陆信息等重要信息存放为session,其他信息如果需要保留,可以放在cookie中。
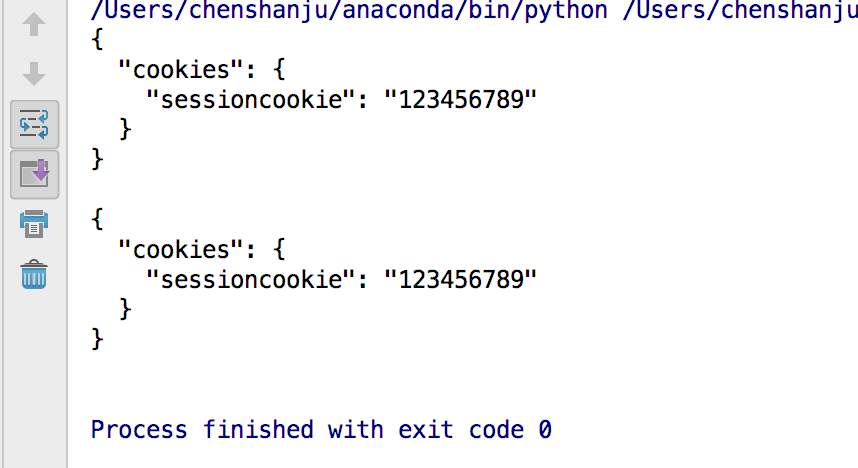
跨请求保持一些cookie
import requests
s = requests.Session()
r = s.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
print(r.text)
r = s.get("http://httpbin.org/cookies")
print(r.text)
2次请求的内容一致
会话也可用来为请求方法提供缺省数据。这是通过为会话对象的属性提供数据来实现的
import requests
s = requests.Session()
s.auth = ('auth','pass')
s.headers.update({'x-test':'true'})
# 'x-test'和'x-test2'都会被发送
s.get('http://httpbin.org/headers',headers={'x-test2':'true'})
注意:就算使用会话,方法级别的参数也不会被跨请求保持
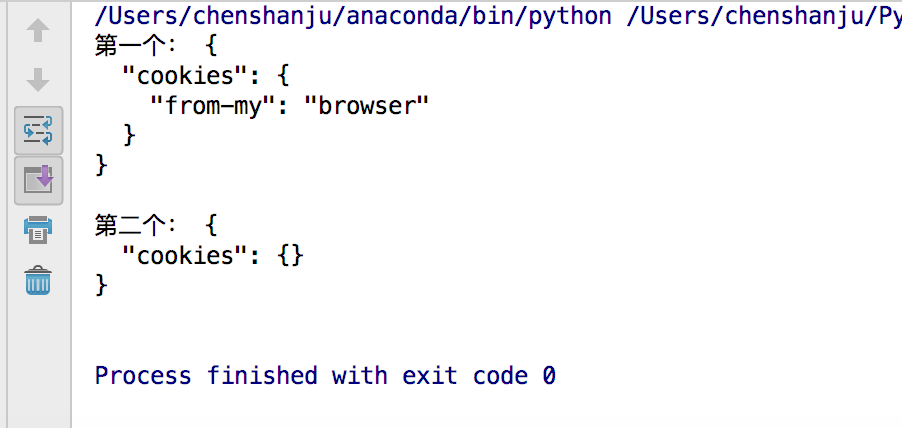
import requests
s = requests.Session()
r = s.get("http://httpbin.org/cookies", cookies={'from-my':'browser'})
print("第一个:", r.text)
r = s.get("http://httpbin.org/cookies")
print("第二个:", r.text)
### 会话作为前后文管理器
能确保 with 区块退出后会话能被关闭,即使发生了异常也一样。
with requests.Session() as s:
r = s.get("http://httpbin.org/cookies/set/sessioncookie/123456789")
print(r.text)
r = s.get("http://httpbin.org/cookies")
print(r.text)

请求与响应对象
任何时候进行了类似 requests.get() 的调用,你都在做两件主要的事情。
- 其一,你在构建一个 Request 对象, 该对象将被发送到某个服务器请求或查询一些资源。
- 其二,一旦 requests 得到一个从服务器返回的响应就会产生一个 Response 对象。该响应对象包含服务器返回的所有信息,也包含你原来创建的 Request 对象。如下是一个简单的请求,从 Wikipedia 的服务器得到一些非常重要的信息:
import requests
r = requests.get('http://en.wikipedia.org/wiki/Monty_Python')
print("响应头部信息: ", r.headers)
print("请求头部信息: ", r.request.headers)

准备的请求
略
SSL证书验证
Requests 可以为 HTTPS 请求验证 SSL 证书,就像 web 浏览器一样。SSL 验证默认是开启的,如果证书验证失败,Requests 会抛出 SSLError:
"按照教程中示例,我这并未提示SSLError类型错误
>>> requests.get('https://requestb.in')
"在该域名上我没有设置 SSL,所以失败抛出SSLError类型错误"
requests.exceptions.SSLError: hostname 'requestb.in' doesn't match either of '*.herokuapp.com', 'herokuapp.com'
"1.默认情况下verify设置为True,仅应用于验证主机的SSL证书。设置为False即忽略对SSL证书的验证"
requests.get('https://github.com', verify=True)
"2.指定证书的路径"
requests.get('https://github.com', verify='/path/to/certfile')
"3.将证书保持在对话中"
s = requests.Session()
s.verify = '/path/to/certfile'
- 默认情况下, verify 是设置为 True 的。选项 verify 仅应用于主机证书。如1
- 对于私有证书,你也可以传递一个 CA_BUNDLE 文件的路径给 verify。你也可以设置 # REQUEST_CA_BUNDLE 环境变量。如2、3
客户端证书
你也可以指定一个本地证书用作客户端证书,可以是单个文件(包含密钥和证书)或一个包含两个文件路径的元组
import requests
"一个包含两个文件路径的元组"
requests.get('https://kennethreitz.org', cert=('/path/client.cert','/path/client.key'))
"单个文件"
s = requests.Session()
s.cert = '/path/client.cert'
如果你指定了一个错误路径或一个无效的证书:
requests.get('https://kennethreitz.org', cert='/wrong_path/client.pem')
SSLError: [Errno 336265225] _ssl.c:347: error:140B0009:SSL routines:SSL_CTX_use_PrivateKey_file:PEM lib
注意:本地证书的私有 key 必须是解密状态。目前,Requests 不支持使用加密的 key。
CA证书
Requests 默认附带了一套它信任的根证书,来自于 Mozilla trust store。然而它们在每次 Requests 更新时才会更新。这意味着如果你固定使用某一版本的 Requests,你的证书有可能已经 太旧了。
从 Requests 2.4.0 版之后,如果系统中装了 certifi 包,Requests 会试图使用它里边的 证书。这样用户就可以在不修改代码的情况下更新他们的可信任证书。
为了安全起见,我们建议你经常更新 certifi!
响应体内容工作流
"默认情况下,当你进行网络请求后,响应体会立即被下载。你可以通过 stream 参数覆盖这个行为,推迟下载响应体直到访问 Response.content 属性:"
r = requests.get('http://httpbin.org/get', stream=True)
print(r.content)
保持活动状态(持久连接)
好消息——归功于 urllib3,同一会话内的持久连接是完全自动处理的!同一会话内你发出的任何请求都会自动复用恰当的连接!
注意:只有所有的响应体数据被读取完毕连接才会被释放为连接池;所以确保将 stream 设置为 False 或读取 Response 对象的 content 属性
流式上传
Requests支持流式上传,这允许你发送大的数据流或文件而无需先把它们读入内存。要使用流式上传,仅需为你的请求体提供一个类文件对象即可:
with open('massive-body') as f:
requests.post('http://some.url/streamed', data=f)
类文件对象,file-like对象,可以像文件对象一样操作
socket对象、输入输出对象(stdin、stdout)都是类文件对象
块编码请求
post多个分块编码的文件
你可以在一个请求中发送多个文件。例如,假设你要上传多个图像文件到一个 HTML 表单,使用一个多文件 field 叫做 "images":

import requests,sys
home_dir=sys.path[1]
url1 = "https://dealer2.autoimg.cn/dealerdfs/g13/M15/22/20/280x210_0_q87_autohomedealer__wKgH41l8Vs2AHMDIAAGEde4vSVM969.jpg"
url2 = "https://car3.autoimg.cn/cardfs/product/g29/M0B/C1/E9/1024x0_1_q87_autohomecar__ChcCSFwTdleADxGNAAZKawd52u8079.jpg"
with open(home_dir+"/data/foo.png", 'wb') as f:
r = requests.get(url1)
f.write(r.content)
with open(home_dir+"/data/bar.png", 'wb') as f:
r = requests.get(url2)
f.write(r.content)
url = "http://httpbin.org/post"
multiple_files = [
('images',(home_dir+'/data/foo.png',open(home_dir+'/data/foo.png','rb'),'image/png')),
('images',(home_dir+'/data/bar.png',open(home_dir+'/data/bar.png','rb'),'image/png'))
]
r = requests.post(url,files=multiple_files)
print(r.text)
事件挂钩
Requests有一个钩子系统,你可以用来操控部分请求过程,或信号事件处理。
import requests
def print_url(r,*args,**kwargs):
print(r.url)
# 可用的钩子:response,
# 1.此例中钩子函数的key必须是response,不能指定为其他值,
# 2.字典指定必须在请求中。
# 通过字典 dict(response=函数) 给hooks请求参数为每个请求分配一个钩子函数,即hooks=dict(response=函数名)
r = requests.get('http://httpbin.org', hooks=dict(response=print_url))

问题:除了response,有没有其他可用的钩子,没有查
自定义身份验证
流式请求
代理
socks
合规性
编码式
HTTP动词
定制动词
响应头连接字段
传输适配器
阻塞和非阻塞
Header排序
超时
request-2高级用法的更多相关文章
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python 内置函数sorted()在高级用法
对于Python内置函数sorted(),先拿来跟list(列表)中的成员函数list.sort()进行下对比.在本质上,list的排序和内建函数sorted的排序是差不多的,连参数都基本上是一样的. ...
- Python之Requests的高级用法
# 高级用法 本篇文档涵盖了Requests的一些更加高级的特性. ## 会话对象 会话对象让你能够跨请求保持某些参数.它也会在同一个Session实例发出的所有请求之间保持cookies. 会话对象 ...
- Requests库的文档高级用法
高级用法 本篇文档涵盖了 Requests 的一些高级特性. 会话对象 会话对象让你能够跨请求保持某些参数.它也会在同一个 Session 实例发出的所有请求之间保持 cookie, 期间使用 url ...
- Python爬虫Urllib库的高级用法
Python爬虫Urllib库的高级用法 设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Head ...
- Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 爬虫 requests模块高级用法
一 介绍 #介绍:使用requests可以模拟浏览器的请求,比起之前用到的urllib,requests模块的api更加便捷(本质就是封装了urllib3) #注意:requests库发送请求将网页内 ...
- Fiddler 高级用法:Fiddler Script 与 HTTP 断点调试
转载自 https://my.oschina.net/leejun2005/blog/399108 1.Fiddler Script 1.1 Fiddler Script简介 在web前端开发的过程中 ...
- 《TomCat与Java Web开发技术详解》(第二版) 第五章节的学习总结 ---- Servlet的高级用法
这一章节主要是介绍了Servlet技术的一些高级用法,如下是我自己的整理归纳 1.下载文件:即获取服务器文件,并把文件写入反馈给客户端 ServletContext.getResourceAsStre ...
- 转 Python爬虫入门四之Urllib库的高级用法
静觅 » Python爬虫入门四之Urllib库的高级用法 1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我 ...
随机推荐
- <NET CLR via c# 第4版>笔记 第19章 可空值类型
System.Nullable<T> 是结构. 19.1 C# 对可空值类型的支持 C# 允许用问号表示法来声明可空值类型,如: Int32? x = 5; Int32? y = null ...
- php 值引用
1.值传递 复制代码 代码如下: <?php function exam($var1){ $var1++: echo "In Exam:" . $var1 . "& ...
- WTForms组件
WTForms组件 WTForms是一个支持多个web框架的form组件,主要用于对用户请求数据进行验证. 注意: from wtforms import Form 和 from flask_wtf ...
- idea中看不到项目结构该怎么办
点击file->project structure..->Modules 点击右上角+加号 ->import Modules 2.选择你的项目,点击确定 3.在如下页面选择imp ...
- 几个你所不知道的技巧助你写出更优雅的vue.js代码
1. watch 与 computed 的巧妙结合 如上图,一个简单的列表页面. 你可能会这么做: created(){ this.fetchData() }, watch: { keyword(){ ...
- SSH 获取GET/POST参数
在做项目的API通知接口的时候,发现在SSH框架中无法获取到对方服务器发来的异步通知信息.最后排查到的原因可能是struts2对HttpServletRequest进行了二次处理,那么该如何拿到pos ...
- HDU1070:Milk
Milk Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submis ...
- web页面的数据从excel中读取
# -*- coding: utf-8 -*- import xdrlib ,sysimport xlrdimport datetimeimport jsonimport conf,reimport ...
- mysql升级到5.6源
###更新mysql的yum源wget http://dev.mysql.com/get/mysql-community-release-el6-4.noarch.rpm### 安装新的mysql源y ...
- 如何调优JVM
堆设置 -Xmx3550m:设置JVM最大堆内存 为3550M. -Xms3550m:设置JVM初始堆内存 为3550M.此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存. -X ...