分析Linux内核创建一个新进程的过程
一、原理分析
1.进程的描述
进程控制块PCB——task_struct,为了管理进程,内核必须对每个进程进行清晰的描述,进程描述符提供了内核所需了解的进程信息。
struct task_struct{
volatile long state; //进程状态,-1表示不可执行,0表示可执行,大于1表示停止
void *stack; //内核堆栈
atomic_t usage;
unsigned int flags; //进程标识符
unsigned int ptrace;
……
}
2.进程的创建
道生一(start_ kernel...cpu_ idle),一生二(kernel_ init和kthreadd),二生三(即前面的0、1、2三个进程),三生万物(1号进程是所有用户态进程的祖先,2号进程是所有内核线程的祖先)
start_ kernel创建了cpu_ idle,也就是0号进程。而0号进程又创建了两个线程,一个是kernel_ init,也就是1号进程,这个进程最终启动了用户态;另一个是kthreadd。0号进程是固定的代码,1号进程是通过复制0号进程PCB之后在此基础上做修改得到的。
iret与int 0x80指令对应,一个是弹出寄存器值,一个是压入寄存器的值。
如果将系统调用类比于fork();那么就相当于系统调用创建了一个子进程,然后子进程返回之后将在内核态运行,而返回到父进程后仍然在用户态运行。
Linux中创建进程一共有三个函数:fork,创建子进程 vfork,与fork类似,但是父子进程共享地址空间,而且子进程先于父进程运行。 clone,主要用于创建线程。Linux中所有的进程创建都是基于复制的方式,Linux通过复制父进程来创建一个新进程,通过调用do_ fork来实现。然后对子进程做一些特殊的处理。而Linux中的线程,又是一种特殊的进程。根据代码的分析,do_ fork中,copy_ process管子进程运行的准备,wake_ up_ new_ task作为子进程forking的完成。fork()函数最大的特点就是被调用一次,返回两次。
追踪do_fork的代码
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = ;
long nr; // ... // 复制进程描述符,返回创建的task_struct的指针
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace); if (!IS_ERR(p)) {
struct completion vfork;
struct pid *pid; trace_sched_process_fork(current, p); // 取出task结构体内的pid
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid); if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr); // 如果使用的是vfork,那么必须采用某种完成机制,确保父进程后运行
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
} // 将子进程添加到调度器的队列,使得子进程有机会获得CPU
wake_up_new_task(p); // ... // 如果设置了 CLONE_VFORK 则将父进程插入等待队列,并挂起父进程直到子进程释放自己的内存空间
// 保证子进程优先于父进程运行
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
} put_pid(pid);
} else {
nr = PTR_ERR(p);
}
return nr;
}
通过上面的代码,可以看出,do_fork大概做了这么几件事情:
(1)调用copy_process,将当期进程复制一份出来为子进程,并且为子进程设置相应地上下文信息。
(2)初始化vfork的完成处理信息(如果是vfork调用)
(3)调用wake_up_new_task,将子进程放入调度器的队列中,此时的子进程就可以被调度进程选中,得以运行。
(4)如果是vfork调用,需要阻塞父进程,知道子进程执行exec。
3.创建的新进程从哪里开始执行?
kernel中是可以指定新进程开始的位置(也就是通过eip寄存器指定代码行)。fork中也有相似的机制 这涉及子进程的内核堆栈数据状态和task_ struct中thread记录的sp和ip的一致性问题,这是在copy_ thread in copy_ process设定的。
copy_thread的流程如下:
(1) 获取子进程寄存器信息的存放位置
(2) 对子进程的thread.sp赋值,将来子进程运行,这就是子进程的esp寄存器的值。
(3)如果是创建内核线程,那么它的运行位置是ret_from_kernel_thread,将这段代码的地址赋给thread.ip,之后准备其他寄存器信息,退出 。
(4)将父进程的寄存器信息复制给子进程。
(5)将子进程的eax寄存器值设置为0,所以fork调用在子进程中的返回值为0。
(6)子进程从ret_from_fork开始执行,所以它的地址赋给thread.ip,也就是将来的eip寄存器。 从上面的流程中,我们看出,子进程复制了父进程的上下文信息,仅仅对某些地方做了改动,运行逻辑和父进程完全一致。
另外,子进程从ret_from_fork处开始执行,子进程的运行是由这几处保证的:
(1)dup_task_struct中为其分配了新的堆栈 。
(2)copy_process中调用了sched_fork,将其置为TASK_RUNNING 。
(3)copy_thread中将父进程的寄存器上下文复制给子进程,这是非常关键的一步,这里保证了父子进程的堆栈信息是一致的。
(4)将ret_from_fork的地址设置为eip寄存器的值,这是子进程的第一条指令。
二、实验内容
更新menu,删除test_fork.c和test.c文件,重新执行make rootfs。首先还是将QEMU启动,然后在sys_clone处设置一个断点。执行以下代码:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char * argv[])
{
int pid;
/* fork another process */
pid = fork();
if (pid < )
{
/* error occurred */
fprintf(stderr,"Fork Failed!");
exit(-);
}
else if (pid == )
{
/* child process */
printf("This is Child Process!\n");
}
else
{
/* parent process */
printf("This is Parent Process!\n");
/* parent will wait for the child to complete*/
wait(NULL);
printf("Child Complete!\n");
}
}
执行后,来到了断点处

sys_clone实际上调用的还是do_fork,也就是说真正的进程创建是都是最终调用do_fork,然后进入该函数,里面有一个函数copy_process,这里面就是开始了详细的创建。首先是异常判断,然后开始了dup_task_struct,也就是复制父进程,产生子进程。 具体函数为
int __weak arch_dup_task_struct(struct task_struct *dst,
struct task_struct *src)
{
*dst = *src;
return ;
}
复制结束后,子进程和父进程是一样的,复制过程中内核堆栈也被复制了,接下来是对子进程进行赋值

复制文件,复制文件系统,复制信号等。 然后单步进入函数copy_thread。
p->thread.sp = (unsigned long) childregs; //子进程栈地址
*childregs = *current_pt_regs(); //子进程的寄存器
childregs->ax = ; //ax保存返回值,子进程执行fork的返回值是0
p->thread.ip = (unsigned long) ret_from_fork; //子进程的开始执行地址
再往下继续单步
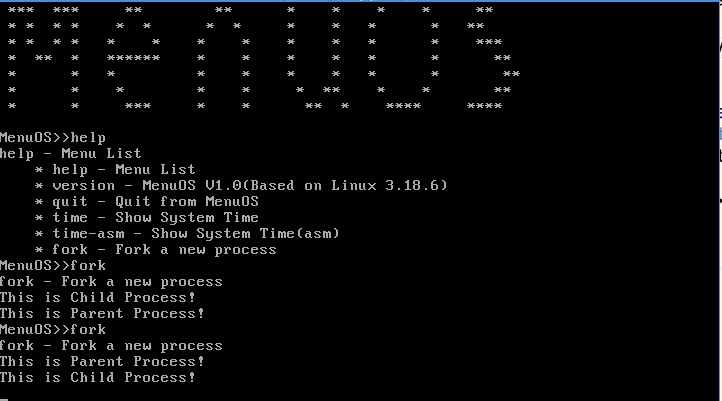
编译内核查看fork命令,得到子进程与父进程结果。
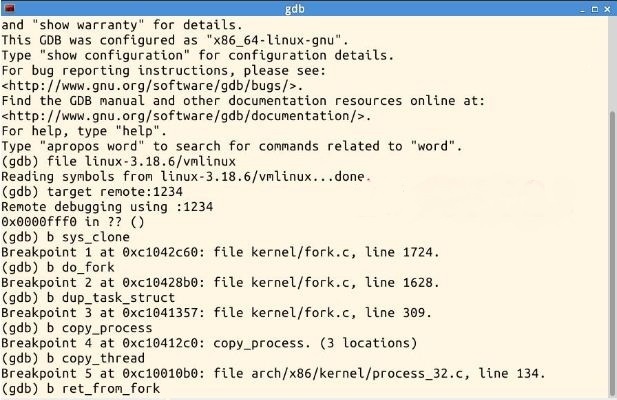
启动gdb调试,并对主要的函数设置断点。
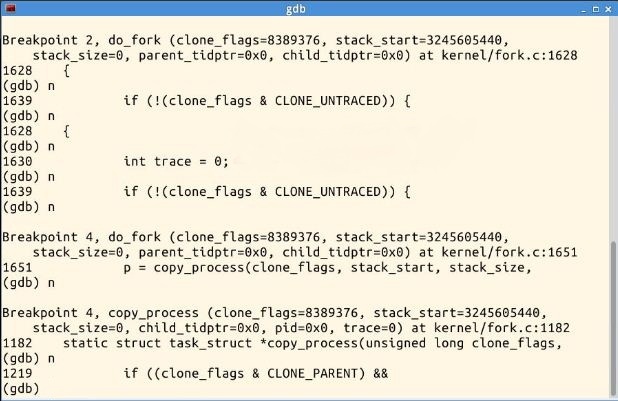
三、总结
对于“特别关注新进程是从哪里开始执行的?为什么从哪里能顺利执行下去?即执行起点与内核堆栈如何保证一致”,由于ret_ from_ fork决定新进程的第一条指令地址。子进程从ret_ from_ fork处开始执行。因为在ret_ from_ fork之前,也就是在copy_ thread()函数中* childregs = * current_ pt_ regs();该句将父进程的regs参数赋值到子进程的内核堆栈。* childregs的类型为pt_ regs,里面存放了SAVE_ ALL中压入栈的参数,因此在之后的RESTORE ALL中能顺利执行下去。
新的进程通过克隆旧的程序(当前进程)而建立。fork() 和 clone()(对于线程)系统调用可用来建立新的进程。这两个系统调用结束时,内核在系统的物理内存中为新的进程分配新的 task_struct 结构,同时为新进程要使用的堆栈分配物理页。Linux 还会为新的进程分配新的进程标识符。然后,新 task_struct 结构的地址保存在链表中,而旧进程的 task_struct 结构内容被复制到新进程的 task_struct 结构中。 在克隆进程时,Linux 允许两个进程共享相同的资源。可共享的资源包括文件、信号处理程序和虚拟内存等。
刘帅
原创作品转载请注明出处
《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
分析Linux内核创建一个新进程的过程的更多相关文章
- linux内核分析作业6:分析Linux内核创建一个新进程的过程
task_struct结构: struct task_struct { volatile long state;进程状态 void *stack; 堆栈 pid_t pid; 进程标识符 u ...
- 第六周分析Linux内核创建一个新进程的过程
潘恒 原创作品转载请注明出处<Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 task_struct结构: ...
- 实验 六:分析linux内核创建一个新进程的过程
实验六:分析Linux内核创建一个新进程的过程 作者:王朝宪 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029 ...
- 20135202闫佳歆--week6 分析Linux内核创建一个新进程的过程——实验及总结
week 6 实验:分析Linux内核创建一个新进程的过程 1.使用gdb跟踪创建新进程的过程 准备工作: rm menu -rf git clone https://github.com/mengn ...
- 《Linux内核--分析Linux内核创建一个新进程的过程 》 20135311傅冬菁
20135311傅冬菁 分析Linux内核创建一个新进程的过程 一.学习内容 进程控制块——PCB task_struct数据结构 PCB task_struct中包含: 进程状态.进程打开的文件. ...
- 作业六:分析Linux内核创建一个新进程的过程
分析Linux内核创建一个新进程的过程 进程描述符PCB----task_struct数据结构 操作系统:1.进程管理 2.内存管理 3 文件系统 一.新进程如何创建和修改task_struct数据结 ...
- Linux内核分析-分析Linux内核创建一个新进程的过程
作者:江军 ID:fuchen1994 实验题目:分析Linux内核创建一个新进程的过程 阅读理解task_struct数据结构http://codelab.shiyanlou.com/xref/li ...
- Linux内核分析第六周学习笔记——分析Linux内核创建一个新进程的过程
Linux内核分析第六周学习笔记--分析Linux内核创建一个新进程的过程 zl + <Linux内核分析>MOOC课程http://mooc.study.163.com/course/U ...
- 第六周——分析Linux内核创建一个新进程的过程
"万子恵 + 原创作品转载请注明出处 + <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 &q ...
- 实验六:分析Linux内核创建一个新进程的过程
原创作品转载请注明出处 + <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 题目自拟,内容围绕对Linu ...
随机推荐
- CC1310电源管脚
对于48pin脚的CC1310而言,属于电源类的管脚如下: 上述电源类管脚的关系如下: 1 VDDS类管脚 VDDS类管脚包括VDDS.VDDS2.VDDS3和VDDS_DCDC四个管脚.其中VDDS ...
- linux grep -I 属性
忽略大小写的查找: grep -i 'address' test.log --> address ADDRESS
- Flyweight(享元)--对象结构型模式
1.意图 运用共享技术有效地支持大量细粒度的对象. 2.动机 Flyweight模式描述了如何共享对象,使得可以细粒度地使用它们,而无需高昂的代价.flyweight是一个共享对象,它可以同时在多个场 ...
- http2协议翻译(转)
超文本传输协议版本 2 IETF HTTP2草案(draft-ietf-httpbis-http2-13) 摘要 本规范描述了一种优化的超文本传输协议(HTTP).HTTP/2通过引进报头字段压缩以及 ...
- 网站appache的ab命令压力测试性能
①:相关不错的博文链接:http://johnnyhg.iteye.com/blog/523818 ②:首先配置好对应的环境上去,有对应的命令 ③:压力测试的指令如下: 1. 最基本的关心两个选项 - ...
- java_js从字符串中截取数字
var str="1件*20桶*30包*123.45公斤"; var res=str.match(/\d+(\.\d+)?/g); alert(res);
- Sum All Primes
function sumPrimes(num) { //return num; var arr = []; var ifPrime = function(num){ if(num < 2){ r ...
- Python3利用BeautifulSoup4批量抓取站点图片的代码
边学边写代码,记录下来.这段代码用于批量抓取主站下所有子网页中符合特定尺寸要求的的图片文件,支持中断. 原理很简单:使用BeautifulSoup4分析网页,获取网页<a/>和<im ...
- ListView13添加2
Columns=//添加列总行的标题 GridLines=true //显示网格线 添加数据------------- listView1.Items.Add("123123123" ...
- doT.js源码解读
doT.js非常的简洁.全部代码也就200行不到.它的基本思路就是通过强大的正则表达式,把模块转变成可执行的函数,动态生成html字符串.核心new Function(c.varname, str); ...