twitter storm源码走读之6 -- Trident Topology执行过程分析
欢迎转载,转载请注明出处,徽沪一郎。
TridentTopology是storm提供的高层使用接口,常见的一些SQL中的操作在tridenttopology提供的api中都有类似的影射。关于TridentTopology的使用及运行原理,当前进行详细分析的文章不多。
从TridentTopology到vanilla topology(普通的topology)由三个层次组成:
- 面向最终用户的概念stream, operation
- 利用planner将tridenttopology转换成vanilla topology
- 执行vanilla topology
本文尝试TridentTopology是如何先一步步转换成普通的storm Topology(即vanila topology), 转换后的topology的执行中有哪些区别?
概述
从TridentTopology到基本的Topology有三层,下图给出一个全局的视图。
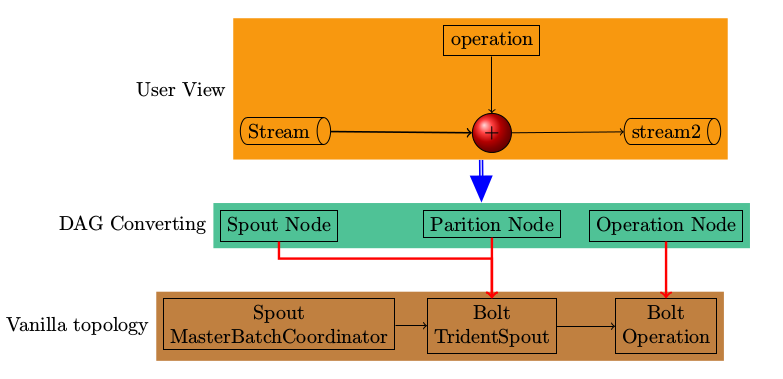
创建TridentTopology
下面的代码摘自StormStarter中的TridentWordCount.java
TridentTopology topology = new TridentTopology();
topology.newStream("spout1", spout).parallelismHint(16).each(new Fields("sentence"),
new Split(), new Fields("word")).groupBy(new Fields("word")).persistentAggregate(new MemoryMapState.Factory(),
new Count(), new Fields("count")).parallelismHint(16); return topology.build();
上述代码的newStream一行,分两大部分,一是使用newStream来创建一个stream对象,然后针对该Stream进行各种操作,each/shuffle/persistentAggregate等就是各种operation.
用户在使用TridentTopology的时候,只需要熟悉Stream和TridentTopology中的API函数即可。
转换TridentTopology为Vanilla Topology
上一节创建了Stream,但是如何将其与原有的Spout及Bolt联系起来呢?问题的关键就在TridentTopology::build函数和TridentTopologyBuilder::buildTopology
TridentTopology::build
newStream及其后的函数调用创建了一个含有三大类节点的List,利用该List创建了一个有向非循环图(DAG)。这三类节点分别是operation, partition, spout,在build函数将节点分类分别加入到boltNodes或spoutNodes,注意此处的spout或bolt不能等同于普通的spout和bolt.
TridentTopologyBuilder::buildTopology
利用在build函数中创建的boltNodes,spoutNodes及生成的graph来创建vanilla topology所需要的bolt及spout.
在buildTopology中会看到类似的代码片段。
builder.setBolt(spoutCoordinator(id), new TridentSpoutCoordinator(c.commitStateId, (ITridentSpout) c.spout))
.globalGrouping(masterCoordinator(c.batchGroupId), MasterBatchCoordinator.BATCH_STREAM_ID)
.globalGrouping(masterCoordinator(c.batchGroupId), MasterBatchCoordinator.SUCCESS_STREAM_ID);
builder.setSpout(masterCoordinator(batch), new MasterBatchCoordinator(commitIds, batchesToSpouts.get(batch)));
for(String b: c.committerBatches) {
specs.get(b).commitStream = new GlobalStreamId(masterCoordinator(b), MasterBatchCoordinator.COMMIT_STREAM_ID);
}
BoltDeclarer d = builder.setBolt(id, new TridentBoltExecutor(c.bolt, batchIdsForBolts, specs), c.parallelism);
最终生成的普通Topology,与普通Topology中的Spout相对应的是MasterBatchCoordinator,而在创建TridentTopology使用的spout则成了Bolt,使用于Stream上的各种Operation也存在于多个普通Bolt中。
TridentTopology的执行
TridentTopology被转换为普通的Topology(vanilla Topology)之后提交到nimbus,它的具体执行过程有什么不同呢?
主要有几点:
- MasterBatchCoordinator通过Batch_stream_id来发送通知给TridentSpoutExecutor
- TridentSpoutExecutor收到通知发送成批的tuple给下一跳的Bolt
- 下一跳的Bolt收到tuple之后,使用TridentBoltExecutor来进行处理
- TridentBoltExecutor调用SubtopologyBolt::execute
- InitialReceiver::execute被调用
- TridentProcessor::execute被调用
MasterBatchCoordinator收到ack之后,会发送success消息给Spout
MasterBatchCoordinator在commit的时候,会发送commit消息给Spout,让Spout将缓存的消息删除
twitter storm源码走读之6 -- Trident Topology执行过程分析的更多相关文章
- twitter storm源码走读之7 -- trident topology可靠性分析
欢迎转载,转载请注明出处,徽沪一郎. 本文详细分析TridentTopology的可靠性实现, TridentTopology通过transactional spout与transactional s ...
- twitter storm 源码走读之5 -- worker进程内部消息传递处理和数据结构分析
欢迎转载,转载请注明出处,徽沪一郎. 本文从外部消息在worker进程内部的转化,传递及处理过程入手,一步步分析在worker-data中的数据项存在的原因和意义.试图从代码实现的角度来回答,如果是从 ...
- twitter storm源码走读之2 -- tuple消息发送场景分析
欢迎转载,转载请注明出处源自徽沪一郎.本文尝试分析tuple发送时的具体细节,本博的另一篇文章<bolt消息传递路径之源码解读>主要从消息接收方面来阐述问题,两篇文章互为补充. worke ...
- twitter storm源码走读之3--topology提交过程分析
概要 storm cluster可以想像成为一个工厂,nimbus主要负责从外部接收订单和任务分配.除了从外部接单,nimbus还要将这些外部订单转换成为内部工作分配,这个时候nimbus充当了调度室 ...
- twitter storm源码走读之1 -- nimbus启动场景分析
欢迎转载,转载时请注明作者徽沪一郎及出处,谢谢. 本文详细介绍了twitter storm中的nimbus节点的启动场景,分析nimbus是如何一步步实现定义于storm.thrift中的servic ...
- twitter storm源码走读之8 -- TridentTopology创建过程详解
欢迎转载,转载请注明出处,徽沪一郎. 从用户层面来看TridentTopology,有两个重要的概念一是Stream,另一个是作用于Stream上的各种Operation.在实现层面来看,无论是str ...
- twitter storm源码走读之4 -- worker进程中线程的分类及用途
欢迎转载,转载请注明出版,徽沪一郎. 本文重点分析storm的worker进程在正常启动之后有哪些类型的线程,针对每种类型的线程,剖析其用途及消息的接收与发送流程. 概述 worker进程启动过程中最 ...
- 【原】storm源码之mac os x编译twitter storm源码
twitter storm是由backtype公司创始人nathanmarz一手研发和开源的流计算(实时计算)框架,堪称实时计算领域的hadoop.nathanmarz也是在mac os x环境下开发 ...
- Storm源码分析--Nimbus-data
nimbus-datastorm-core/backtype/storm/nimbus.clj (defn nimbus-data [conf inimbus] (let [forced-schedu ...
随机推荐
- Buy Tickets(poj 2828)
题意:排队买票,但是 中途 出现插队情况,比如 0 123,代表值为123的人 插入到 0 的位置,如果后面 出现 0 456,那么新的 0的位置就是 456,123就变成是 1的位置了 分析:这道题 ...
- 膜拜(codevs 3369)
3369 膜拜 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 黄金 Gold 题解 题目描述 Description 神牛有很多…当然…每个同学都有自己衷心膜拜的 ...
- Android实现网络音乐播放器
本文是一个简单的音乐播放器 布局代码 <?xml version="1.0" encoding="utf-8"?> <RelativeLayo ...
- 从几个方向进行Web渗透测试
渗透测试就是对系统安全性的测试,通过模拟恶意黑客的攻击方法,来评估系统安全的一种评估方法. 渗透测试可以包括各种形式的攻击,一般来说会有专门的公司提供这种服务,这里整理了几种常见的渗透测试方法,可以对 ...
- poj 3468 成段增减
Sample Input 10 5 1 2 3 4 5 6 7 8 9 10 Q 4 4 Q 1 10 Q 2 4 C 3 6 3 Q 2 4 Sample Output 4 55 9 15 #inc ...
- androidSDK也要配置环境变量(转)
android的开发人员来说,首先要做的就是环境变量的配置.java是需要配置环境变量的.当然,安卓的环境变量需要我们配置adb的使用,将开发平台的两个工具包配置到环境变量里. 工具/原料 andro ...
- Spark metrics on wordcount example
I read the section Metrics on spark website. I wish to try it on the wordcount example, I can't make ...
- Android DrawerLayout 高仿QQ5.2双向侧滑菜单
1.概述 之前写了一个Android 高仿 QQ5.0 侧滑菜单效果 自定义控件来袭 ,恰逢QQ5.2又加了一个右侧菜单,刚好看了下DrawerLayout,一方面官方的东西,我都比较感兴趣:另一方面 ...
- Spring的meta标签
Spring的解析源码 public void parseMetaElements(Element ele, BeanMetadataAttributeAccessor attributeAccess ...
- redis的相关知识
1. 依赖包安装 pom.xml 加入: <!-- redis cache related.....start --> <dependency> <groupId> ...