Hadoop学习之SecondaryNameNode
在启动Hadoop时,NameNode节点上会默认启动一个SecondaryNameNode进程,使用JSP命令可以查看到。SecondaryNameNode光从字面上理解,很容易让人认为是NameNode的热备进程。其实不是,SecondaryNameNode是HDFS架构中的一个组成部分。它并不是元数据节点出现问题时的备用节点,它和元数据节点负责不同的事情。
1、SecondaryNameNode节点的用途:
简单的说,SecondaryNameNode节点的主要功能是周期性将元数据节点的命名空间镜像文件和修改日志进行合并,以防日志文件过大。
要理解SecondaryNameNode的功能,首先我们先来了解下NameNode的主要工作:
2、NameNode节点的主要工作:
NameNode的主要功能之一是用来管理文件系统的命名空间,其将所有的文件和文件目录的元数据保存在一个文件系统树中。为了保证交互速度,NameNode会在内存中保存这些元数据信息,但同时也会将这些信息保存到硬盘上进行持久化存储,通常会被保存成以下文件:命名空间镜像文件(fsimage)和修改日志文件(edits)。下图是NameNode节点上的文件目录结构:
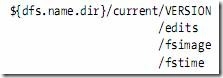
fsimage文件,也即命名空间映像文件,是内存中的元数据在硬盘上的checkpoint,它是一种序列化的格式,并不能够在硬盘上直接修改。
有了这两个文件后,Hadoop在重启时就可以根据这两个文件来进行状态恢复,fsimage相当于一个checkpoint,所以当Hadoop重启时需要两个文件:fsimage+edits,首先将最新的checkpoint的元数据信息从fsimage中加载到内存,然后逐一执行edits修改日志文件中的操作以恢复到重启之前的最终状态。
Hadoop的持久化过程是将上一次checkpoint以后最近一段时间的操作保存到修改日志文件edits中。
这里出现的一个问题是edits会随着时间增加而越来越大,导致以后重启时需要花费很长的时间来按照edits中记录的操作进行恢复。所以Hadoop用到了SecondaryNameNode,它就是用来帮助元数据节点将内存中的元数据信息checkpoint到硬盘上的。
3、SecondaryNameNode工作流程:
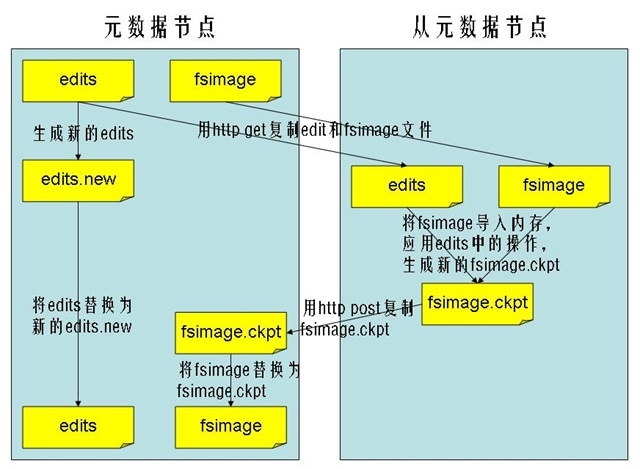
SecondaryNameNode节点通知NameNode节点生成新的日志文件,以后的日志都写到新的日志文件中。
SecondaryNameNode节点用http get从NameNode节点获得fsimage文件及旧的日志文件。
SecondaryNameNode节点将fsimage文件加载到内存中,并执行日志文件中的操作,然后生成新的fsimage文件。
SecondaryNameNode节点将新的fsimage文件用http post传回NameNode节点上。
NameNode节点可以将旧的fsimage文件及旧的日志文件,换为新的fsimage文件和新的日志文件(第一步生成的),然后更新fstime文件,写入此次checkpoint的时间。
这样NameNode节点中的fsimage文件保存了最新的checkpoint的元数据信息,日志文件也重新开始,不会变的很大了。
流程图如下所示:
4、SecondaryNameNode运行在另一台非NameNode的 机器上
SecondaryNameNode进程默认是运行在NameNode节点的机器上的,如果这台机器出错,宕机,对恢复HDFS文件系统是很大的灾难,更好的方式是:将SecondaryNameNode的进程配置在另外一台机器 上运行。至于为什么要将SNN进程运行在一台非NameNode的 机器上,这主要出于两点考虑:
可扩展性: 创建一个新的HDFS的snapshot需要将namenode中load到内存的metadata信息全部拷贝一遍,这样的操作需要的内存就需要 和namenode占用的内存一样,由于分配给namenode进程的内存其实是对HDFS文件系统的限制,如果分布式文件系统非常的大,那么namenode那台机器的内存就可能会被namenode进程全部占据。
容错性: 当snn创建一个checkpoint的时候,它会将checkpoint拷贝成metadata的几个拷贝。将这个操作运行到另外一台机器,还可以提供分布式文件系统的容错性。
5、配置将SecondaryNameNode运行在另一台机器上:
HDFS的一次运行实例是通过在namenode机器上的$HADOOP_HOME/bin/start-dfs.sh( 或者start-all.sh ) 脚本来启动的。这个脚本会在运行该脚本的机器上启动 namenode进程,而slaves机器上都会启动DataNode进程,slave机器的列表保存在 conf/slaves文件中,一行一台机器。并且会在另外一台机器上启动一个SecondaryNameNode进程,这台机器由conf/masters文件指定。所以,这里需要严格注意, conf/masters 文件中指定的机器,并不是说jobtracker或者namenode进程要 运行在这台机器上,因为这些进程是运行在 launch bin/start-dfs.sh或者 bin/start-mapred.sh(start-all.sh)的机器上的。所以,masters这个文件名是非常的令人混淆的,应该叫做secondaries会比较合适。然后,通过以下步骤:
将所有想要运行secondarynamenode进程的机器写到masters文件中,一行一台。
修改在masters文件中配置了的机器上的conf/hadoop-site.xml文件,加上如下选项:
<property>
<name>dfs.http.address</name>
<value> :50070</value>
</property>
Hadoop学习之SecondaryNameNode的更多相关文章
- Hadoop学习(5)-- Hadoop2
在Hadoop1(版本<=0.22)中,由于NameNode和JobTracker存在单点中,这制约了hadoop的发展,当集群规模超过2000台时,NameNode和JobTracker已经不 ...
- Hadoop学习总结之五:Hadoop的运行痕迹
Hadoop学习总结之五:Hadoop的运行痕迹 Hadoop 学习总结之一:HDFS简介 Hadoop学习总结之二:HDFS读写过程解析 Hadoop学习总结之三:Map-Reduce入门 Ha ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(2) ——解读Hello World
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(1) ——菜鸟入门
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- Hadoop学习------Hadoop安装方式之(二):伪分布部署
要想发挥Hadoop分布式.并行处理的优势,还须以分布式模式来部署运行Hadoop.单机模式是指Hadoop在单个节点上以单个进程的方式运行,伪分布模式是指在单个节点上运行NameNode.DataN ...
- Hadoop学习笔记(1)(转)
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
- Hadoop学习笔记(9) ——源码初窥
Hadoop学习笔记(9) ——源码初窥 之前我们把Hadoop算是入了门,下载的源码,写了HelloWorld,简要分析了其编程要点,然后也编了个较复杂的示例.接下来其实就有两条路可走了,一条是继续 ...
随机推荐
- TreeBuilder科学的树创建器
public static class TreeBuilder { public static List<dynamic> Build(IEnumerable<dynamic> ...
- 验证控件插图扩展控件ValidatorCalloutExtender(用于扩展验证控件)和TextBoxWatermarkExtender
<asp:ScriptManager ID="ScriptManager1" runat="server"> </asp:ScriptMan ...
- IIS在默认情况并不支持对PUT和DELETE请求的支持
IIS在默认情况并不支持对PUT和DELETE请求的支持: IIS拒绝PUT和DELETE请求是由默认注册的一个名为:“WebDAVModule”的自定义HttpModule导致的.WebDAV的全称 ...
- [Angularjs]视图和路由(四)
写在前面 关于angularjs的路由的概念基本上这篇就要结束了,通过学习,以及在实际项目中的实践,还是比较容易上手的.自己也通过angularjs做了一个在app上的一个模块,效果还是可以的. 系列 ...
- CRM行编辑控件
原创,转载请说明出处 王红福 http://www.cnblogs.com/hellohongfu/p/4792452.html CRM 本身的表格可以根据定义显示列信息,但是出于性能考虑不能详细的展 ...
- SharePoint 使用代码为页面添加WebPart
传统的SharePoint实施中,我们通常会创建SharePoint页面,然后添加webpartzone,而后在上面添加webpart:但是有些情况下,也要求我们使用代码,将webpart添加到相应w ...
- Stooge排序与Bogo排序算法
本文地址:http://www.cnblogs.com/archimedes/p/stooge-bogo-sort-algorithm.html,转载请注明源地址. Stooge排序算法 Stooge ...
- 【转载】iOS堆和栈的理解
操作系统iOS 中应用程序使用的计算机内存不是统一分配空间,运行代码使用的空间在三个不同的内存区域,分成三个段:“text segment “,“stack segment ”,“heap segme ...
- 【读书笔记】iOS-本地文件和数据安全注意事项
一,程序文件的安全. 可通过将JavaScript源码时行混淆和加密,防止黑客轻易地阅读和篡改相关的逻辑,也可以防止自己的Web端与Native端的通讯协议泄露. 二,本地数据安全. 对于本地的重要数 ...
- IOS 沙盒机制 浅析
IOS中的沙盒机制(SandBox)是一种安全体系,它规定了应用程序只能在为该应用创建的文件夹内读取文件,不可以访问其他地方的内容.所有的非代码文件都保存在这个地方,比如图片.声音.属性列表和文本文件 ...