磁盘告警之---神奇的魔法(Sparse file)
一、问题来源
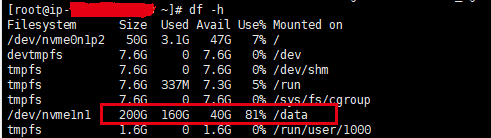

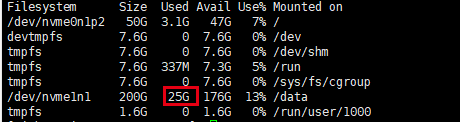
二、出现的问题
[root@ip-XXXXXXXX data]# ls -lh test.dat
-rw------- root root 60G Sep : test.dat
[root@ip-XXXXXXXX data]# du -sh test.dat
.4G test.dat
三、排查过程
[root@ip---- data]# du -h --apparent-size test.dat
60G test.dat
四、Sparse file
既然找到问题了,就得好好看看这是个啥东西,看了之后第一反应就是这个文件预分配了60G,但实际上只使用了4.4G...,蒽~~,就这么个意思......
1、定义
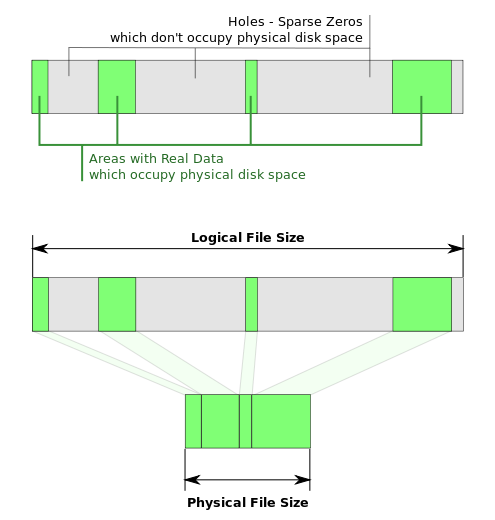
2、其他使用场景

dd of=sparse-file bs=7M seek= count= # 相当于创建一个7G的空文件,不占磁盘上的存储数据
或者
truncate -s 7G lile # 相当于创建一个7G的空文件,不占磁盘上的存储数据
4、测试
# 可以看到/run目录下是7.7G
[root@master run]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/nvme0n1p2 200G .0G 195G % /
devtmpfs .7G .7G % /dev
tmpfs .7G .7G % /dev/shm
tmpfs .7G 428K .7G % /run
tmpfs .7G .7G % /sys/fs/cgroup
tmpfs .6G .6G % /run/user/ # 创建一个7G的sparse file
[root@master run]# truncate -s 7G lile [root@master run]# ls -lh lile
-rw-r--r-- root root .0G Sep : lile # lile这个文件只是一个空的文件,不占存储空间
[root@master run]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/nvme0n1p2 200G .0G 195G % /
devtmpfs .7G .7G % /dev
tmpfs .7G .7G % /dev/shm
tmpfs .7G 428K .7G % /run
tmpfs .7G .7G % /sys/fs/cgroup
tmpfs .6G .6G % /run/user/ # 使用dd创建一个大小为7G的普通文件
[root@master run]# dd if=/dev/zero of=output bs=1G count=
+ records in
+ records out
bytes (7.5 GB) copied, 3.5524 s, 2.1 GB/s # 可以看到是成功的,这就说明sparse文件预分配的大小不影响磁盘存储空间,不影响其他文件使用存储空间
[root@master run]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/nvme0n1p2 200G .0G 195G % /
devtmpfs .7G .7G % /dev
tmpfs .7G .7G % /dev/shm
tmpfs .7G .1G 704M % /run
tmpfs .7G .7G % /sys/fs/cgroup
tmpfs .6G .6G % /run/user/
5、总结及注意
1)Sparse files并不占用磁盘存储空间
2)平时我们使用ls -lh查看文件大小、find / -size +1G 找出来的日志大小并不一定准确,尽量再一遍使用du -sh确认
3)ls命令和du命令在一定程度上可以这样表示
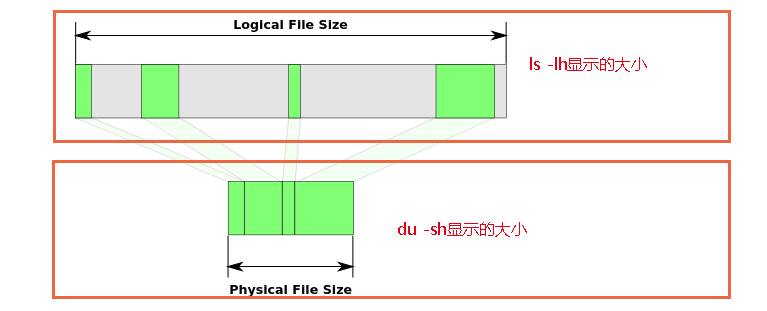
五、其他
1、本想看一下跟sparse file相关的unix系统方面的,但是感觉自己知识点不太足,有点难度....
磁盘告警之---神奇的魔法(Sparse file)的更多相关文章
- 第17章 内存映射文件(3)_稀疏文件(Sparse File)
17.8 稀疏调拨的内存映射文件 17.8.1 稀疏文件简介 (1)稀疏文件(Sparse File):指的是文件中出现大量的0数据,这些数据对我们用处不大,但是却一样的占用空间.NTFS文件系统对此 ...
- SQL Server ->> Sparse File(稀疏文件)
Sparse File(稀疏文件)不是SQL Server的特性.它属于Windows的NTFS文件系统的一个特性.如果某个大文件中的数据包含着大量“0数据”(这个应该从二进制上看),这样的文件就可以 ...
- Linux 磁盘告警分析
硬件配置 cat /etc/redhat-release && dmidecode -s system-product-name && cat /proc/cpuinf ...
- 转 由一次磁盘告警引发的血案:du 和 ls 的区别
如果你完全不明白或者完全明白图片含义, 那么你不用继续往下看了. 否则, 这篇文章也许正是你需要的. 背景 确切地说,不是收到的自动告警短信或者邮件告诉我某机器上的磁盘满了,而是某同学人肉发现该机器写 ...
- 用windows自带的fsutil来创建1G稀疏文件(sparse file)
fsutils file createnew a.dat 1073741824 fsutil sparse setflag a.dat fsutil sparse setrange a.dat 0 ...
- 基于【磁盘】操作的IO接口:File
基本操作Api import org.apache.commons.lang3.time.DateFormatUtils; import java.io.*; import java.util.Dat ...
- 神奇的魔法数字0x61c88647
来源JDK源码,产生的数字分布很均匀 用法代码如下. # -*- coding: utf-8 -*- HASH_INCREMENT = 0x61c88647 def magic_hash(n): fo ...
- KVM虚拟化技术(六)磁盘管理
KVM支持的虚拟磁盘类型 raw 这并非是一种真正的磁盘格式,而是代表虚拟机所使用的原始镜像:它并不存储元数据,因此可以作为保证虚拟机兼容性的候选方案,然而也正因为 它不存储元数据,因此不能支持某些高 ...
- Python监控SQL Server数据库服务器磁盘使用情况
本篇博客总结一下Python采集SQL Server数据库服务器的磁盘使用信息,其实这里也是根据需求不断推进演化的一个历程,我们监控服务器的磁盘走了大概这样一个历程: 1:使用SQL Server作业 ...
随机推荐
- 01-WIN2012R2+SQL2016故障转移群集的搭建
一.前期准备 1.1.准备4台机器 机器名 IP 功能 jf-yukong 192.168.10.200 做域控服务器 Jf-storage 192.168.10.201 做ISCSI存储服务器 J ...
- Elasticsearch Lucene 数据写入原理 | ES 核心篇
前言 最近 TL 分享了下 <Elasticsearch基础整理>https://www.jianshu.com/p/e8226138485d ,蹭着这个机会.写个小文巩固下,本文主要讲 ...
- ABAP-复制采购订单行项目到新的行
FUNCTION zmm_fm_copy2new. *"------------------------------------------------------------------- ...
- 监控JVM
WAS配置visualVM 在was控制台:找到应用程序服务器--java和进程管理--进程定义--JAVA虚拟机/通用JVM 参数 ,对应英文Application servers > ser ...
- 使用executor、callable以及一个Future 计算欧拉数e
package test; import java.math.BigDecimal; import java.math.MathContext; import java.math.RoundingMo ...
- Spring源码剖析6:Spring AOP概述
原文出处: 五月的仓颉 我们为什么要使用 AOP 前言 一年半前写了一篇文章Spring3:AOP,是当时学习如何使用Spring AOP的时候写的,比较基础.这篇文章最后的推荐以及回复认为我写的对大 ...
- 集合系列 List(三):Vector
Vector 的底层实现以及结构与 ArrayList 完全相同,只是在某一些细节上会有所不同.这些细节主要有: 线程安全 扩容大小 线程安全 我们知道 ArrayList 是线程不安全的,只能在单线 ...
- 《Tomcat和JVM的性能调优你真的学会了吗?》总结篇
Tomcat性能调优: 找到Tomcat根目录下的conf目录,修改server.xml文件的内容.对于这部分的调优,我所了解到的就是无非设置一下Tomcat服务器的最大并发数和Tomcat初始化时创 ...
- nanopi NEO2 学习笔记 3:python 安装 RPi.GPIO
如果我要用python控制NEO2的各种引脚,i2c 或 spi ,RPi.GPIO模块是个非常好的选择 这个第三方模块是来自树莓派的,好像友善之臂的工程师稍作修改移植到了NEO2上,就放在 /roo ...
- js 前端实现打印功能
// 此处是一个打印的方法 可以在点击事件的时候调用 dayin = () =>{ // 获取当前页面要打印的内容 // 这里的className(‘print’)是我给要打印的区域起的 ...