Oracle SQL调优之绑定变量用法简介
最近在看《基于Oracle的SQL优化一书》,并做了笔记,作者的个人博客:http://www.dbsnake.net/
@
一、SQL执行过程简介
继上一篇博客Oracle的cursor学习笔记:Oracle的游标Cursor原理简介,再介绍oracle的绑定变量
介绍绑定变量之前,先介绍SQL执行过程和硬解析的概念:
执行sql的过程,会将sql的文本进行hash运算,得到对象的hash值,然后拿hash值,去Hash Buckets里遍历缓存对象句柄链表,找到对应的缓存对象句柄,然后就可以得到缓存对象句柄里对应sql执行计划、解析树等对象,所以执行相同的sql第二次执行时是会比较快的,因为不需要解析获取执行计划,解析树等对象,如果找不到库缓存对象句柄,就需要重新解析,这个过程解析过多,容易造成硬解析问题
硬解析:是指Oracle在执行目标SQL时,在库缓存中找不到可以重用的解析树和执行计划,而不得不从头开始解析目标SQL并生成相应的Parent Cursor和Child Cursor的过程。
软解析:是指Oracle在执行目标SQL时,在Library Cache中找到了匹配的Parent Cursor和Child Cursor,并将存储在Child Cursor中的解析树和执行计划直接拿过来重用,无须从头开始解析的过程。
ok,上面是SQL执行过程的简单介绍,由此可知,假如sql执行过程,在共享池里找不到执行计划、解析树等就会重现解析sql,生成执行计划和解析树等,这个过程是比较耗时间的,所以要想办法尽量不要重现解析sql,需要执行计划直接去共享池拿已经生成的
举个例子,select * from sys_user where userid='u10001';和select * from sys_user where userid='u10002';,这两个很类似的sql在执行过程,生成的执行计划很有可能是不一样的,也就是说第一条sql执行后,第二条sql继续执行,假如发现找不到对应执行计划,就会再解析sql,重现生成session cursor和一对shared cursor(parent cursor和child cursor)
然后,我们不想重新解析sql,有什么方法?方法就是用绑定变量的方法
二、绑定变量典型用法
2.1、在SQL中绑定变量
绑定变量的典型用法就是用 :variable_name的形式,variable_name是自定义的变量名称,variabl_name可以是字母、数字或者字母和数字的组合
ok,上面的那种类型的sql,就可以用一条带绑定变量的sql来表示:
select * from sys_user where userid = :u;
这样这种类型的一堆sql都只会解析一次,不用每条sql都解析一遍,可以很好的提高系统处理能力
ok,举个例子说明
环境准备:
/* 随便建一张表*/
create table t as select * from dba_objects;
注意,这些脚本只能在sqlplus或者PLSQL客户端的命令窗口执行
/* 定义绑定变量vid */
SQL> variable vid number;
/* 给绑定变量赋值为2 */
SQL> exec :vid := 2;
在sqlplus或者PLSQL客户端的命令窗口执行
/* 通过绑定变量查询 */
SQL> select * from t where object_id = :vid;
/*通过性能视图查询SQL解析情况*/
select a.*, b.name
from v$sesstat a, v$statname b
where a.statistic# = b.statistic#
and a.sid = (select distinct sid from v$mystat)
and b.name like '%parse%';
/* 去共享池查询一下这种类型的SQL信息*/
select sql_text, parse_calls, executions
from v$sql
where sql_text like 'select * from t where object_id=%';
/* 通过共享池查询查询最慢的10条sql*/
SELECT *
FROM (select PARSING_USER_ID,
EXECUTIONS,
SORTS,
COMMAND_TYPE,
DISK_READS,
sql_text
FROM v$sqlarea
order BY disk_reads DESC)
where ROWNUM < 10;
2.2、在PL/SQL中使用绑定变量
/* SQL语句使用绑定变量*/
declare
vc_empname varchar2(10);
begin
execute immediate 'select ename from t_emp where empno = :1'
into vc_empname
using 7369;
dbms_output.put_line(vc_empname);
end;
/
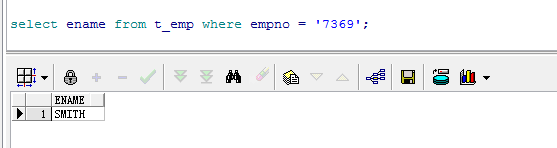
往t_emp表写入一条数据,并统计是否执行成功,返回数值
/*DML语句使用绑定变量*/
declare
vc_sql varchar2(2000);
vc_number number;
begin
vc_sql := 'insert into t_emp(empno,ename,job) values(:1,:2,:3)';
execute immediate vc_sql using 7990,'SMITH','HR';
vc_number := sql%rowcount;
dbms_output.put_line(to_char(vc_number));
commit;
end;
/
所以绑定变量在pl/sql里的核心语法为:
execute immediate [sql语句] using [变量]
2.3、PL/SQL批量绑定变量
例子来自《基于Oracle的SQL优化》一书,要实现的的是批量绑定变量,fetch关键字,将empno大于7900的职员信息打印出来
declare
cur_emp sys_refcursor;
vc_sql varchar2(2000);
type namelist is table of varchar2(10);
enames namelist;
CN_BATCH_SIZE constant pls_integer := 1000;
begin
vc_sql:= 'select ename from t_emp where empno > :1';
open cur_emp for vc_sql using 7900;
loop
fetch cur_emp bulk collect into enames limit CN_BATCH_SIZE;
for i in 1..enames.count loop
dbms_output.put_line(enames(i));
end loop;
exit when enames.count < CN_BATCH_SIZE;
end loop;
close cur_emp;
end;
/
2.4、Java代码里使用绑定变量
不用绑定变量的写法:
String empno = '7369';
String query_sql = 'select ename from t_emp where empno = 7369 ';
stmt = con.prepareStatement( query_sql );
stmt.executeQuery();
使用绑定变量的写法:
String empno = 'xxxxx';
String query_sql = 'select ename from t_emp where empno = ? '; //嵌入绑定变量
stmt = con.prepareStatement( query_sql );
stmt.setString(1, empno ); //为绑定变量赋值
stmt.executeQuery();
批量绑定变量写法:
此例子来自《基于Oracle的SQL优化》一书:
String vc_sql = 'update t_emp set sal = ? where empno = ?';
pstmt = connection.prepareStatement(dml);
pstmt.clearBatch();
for (int i = 0; i < UPDATE_COUNT; ++ i) {
pstmt.setInt(1, generateEmpno(i));
pstms.setInt(2, generateSal(i));
pstmt.addBatch();
}
pstmt.executeBatch();
connection.commit();
Oracle SQL调优之绑定变量用法简介的更多相关文章
- Oracle性能调优之虚拟索引用法简介
本博客记录一下Oracle虚拟索引的用法,虚拟索引是定义在数据字典中的伪索引,可以说是伪列,没有修改的索引字段的.虚拟索引的目的模拟索引,不会增加存储空间的使用,有了虚拟索引,开发者使用执行计划的时候 ...
- Oracle性能调优之物化视图用法简介
目录 一.物化视图简介 二.实践:创建物化视图 一.物化视图简介 物化视图分类 物化视图分类,物化视图语法和as后面的sql分为: (1) 基于主键的物化视图(主键物化视图) (2)基于Rowid的物 ...
- Oracle SQL 调优健康检查脚本
Oracle SQL 调优健康检查脚本 我们关注数据库系统的性能,进行数据库调优的主要工作就是进行SQL的优化.良好的数据架构设计.配合应用系统中间件和写一手漂亮的SQL,是未来系统上线后不出现致命性 ...
- Oracle SQL调优记录
目录 一.前言 二.注意点 三.Oracle执行计划 四.调优记录 @ 一.前言 本博客只记录工作中的一次oracle sql调优记录,因为数据量过多导致的查询缓慢,一方面是因为业务太过繁杂,关联了太 ...
- Oracle SQL调优之分区表
目录 一.分区表简介 二.分区表优势 三.分区表分类 3.1 范围分区 3.2 列表分区 3.3 散列分区 3.4 组合分区 四.分区相关操作 五.分区相关查询 附录:分区表索引失效的操作 一.分区表 ...
- Oracle SQL调优系列之SQL Monitor Report
@ 目录 1.SQL Monitor简介 2.捕捉sql的前提 3.SQL Monitor 参数设置 4.SQL Monitor Report 4.1.SQL_ID获取 4.2.Text文本格式 4. ...
- Oracle SQL调优
在多数情况下,Oracle使用索引t来更快地遍历表,优化器主要根据定义的索引来提高性能. 但是,如果在SQL语句的where子句中写的SQL代码不合理,就会造成优化器删去索引而使用全表扫描,一般就这种 ...
- Oracle SQL调优之表设计
在看<收获,不止sql优化>一书,并做了笔记,本博客介绍一下一些和调优相关的表比如分区表.临时表.索引组织表.簇表以及表压缩技术 分区表使用与查询频繁而更新数据不频繁的情况,不过要记得加全 ...
- Oracle SQL 调优之 sqlhc
SQL 执行慢,如何 快速准确的优化. sqlhc 就是其中最好工具之一 通过获得sql所有的执行计划,列出实际的性能的瓶颈点,列出 sql 所在的表上的行数,每一列的数据和分布,现有的索引,sql ...
随机推荐
- turtle绘制图形
Example1: import turtle as t #初始设置画笔的宽度(size).颜色(color) t.pensize(5) t.pencolor("black") # ...
- c# NPOI 导出23万条记录耗时12秒
先上测试代码: string connectionString = "Server=localhost;Initial Catalog=******;User ID=sa;Password= ...
- 编译Assimp傻瓜教程
assimp的编译过程和搭建OpenGL环境时glfw的编译基本相同,建议先阅读环境搭建 下载源码 这里使用的是3.3.1版本,Github下载assimp源码 解压完你会得到 接下来我们要编译这些源 ...
- 记一次Linux修改MySQL配置不生效的问题
背景 自己手上有一个项目服务用的是AWS EC2,最近从安全性和性能方面考虑,最近打算把腾讯云的MySQL数据库迁移到AWS RDS上,因为AWS的出口规则和安全组等问题,我需要修改默认的3306端口 ...
- python变量前的单下划线(私有变量)和双下划线()
1.单下划线 变量前的单下划线表示表面上私有 ,但是其实这样的实例变量外部是可以访问的,但是,按照约定俗成的规定,当你看到这样的变量时,意思就是,“虽然我可以被访问,但是,请把我视为私有变量,不要随意 ...
- RN 性能优化
按需加载: 导出模块使用属性getter动态require 使用Import语句导入模块,会自动执行所加载的模块.如果你有一个公共组件供业务方使用,例如:common.js import A from ...
- asp.net core系列 71 Web架构分层指南
一.概述 本章Web架构分层指南,参考了“Microsoft应用程序体系结构指南”(该书是在2009年出版的,当时出版是为了帮助开发人员和架构师更快速,更低风险地使用Microsoft平台和.NET ...
- 第一章 .NET基础-C#基础
一.1.1. 基础语法 一.1.1.1. 注释符 一.1.1.1.1. 注释符的作用 l 注释 l 解释 一.1.1.1.2. C#中的3中注释符 l 单行注释 // l 多上注释 /* 要注释的内容 ...
- 【Python3爬虫】快就完事了--使用Celery加速你的爬虫
一.写在前面 在上一篇博客中提到过对于网络爬虫这种包含大量网络请求的任务,是可以用Celery来做到加速爬取的,那么,这一篇博客就要具体说一下怎么用Celery来对我们的爬虫进行一个加速! 二.知识补 ...
- 开发人员需要掌握的日常Linux命令集
本文整理了开发人员日常用到的linux相关命令,供参考. 文件相关 cd # 进入某个目录,不接参数进入当前用户目录(等同于cd ~)如/home/devuser,可接绝对路径或相对路径(../..表 ...