HDP Hive性能调优
(官方文档翻译整理及总结)
一、优化数据仓库
① Hive LLAP 是一项接近实时结果查询的技术,可用于BI工具以及网络看板的应用,能够将数据仓库的查询时间缩短到15秒之内,这样的查询称之为Interactive Query。
Ambari安装好之后,还需要额外的两个步骤来开启Hive LLAP:
1.在yarn中开启Hive LLAP的优先使用权
2.打开hive中的Interactive Query开发并配置相关参数
② HiveServer2 高效的连接管理,类似于mysql连接池,在Ambari中配置好相关参数。
③ Tez Hive和MapReduce之间的中间层,对查询进行预处理,对中间结果进行缓存。Tez ApplicationMaster 决定查询的最大并发数。
二、使用ORCFile Format
原数据 csv格式(通用格式,一般从mysql导出这种格式的数据)

- 更小的空间占用

- 更快的查询
先后对4种格式的表进行统计查询,去重统计查询,连接加去重查询,详细结果见截图,可以得出结论,综合存储和查询两方面,orc file format都有较好的表现, 这也是HDP平台官方推荐的做法(parquet是CDH平台推荐的一种存储格式)。
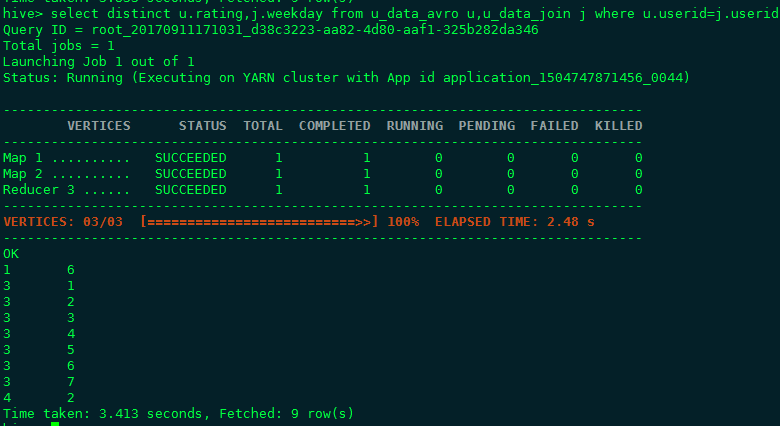
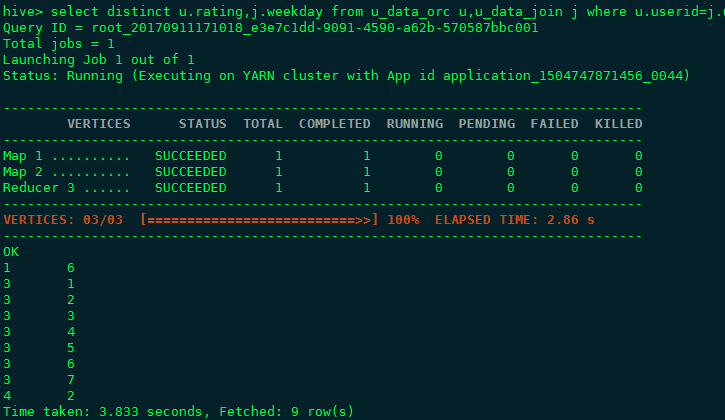
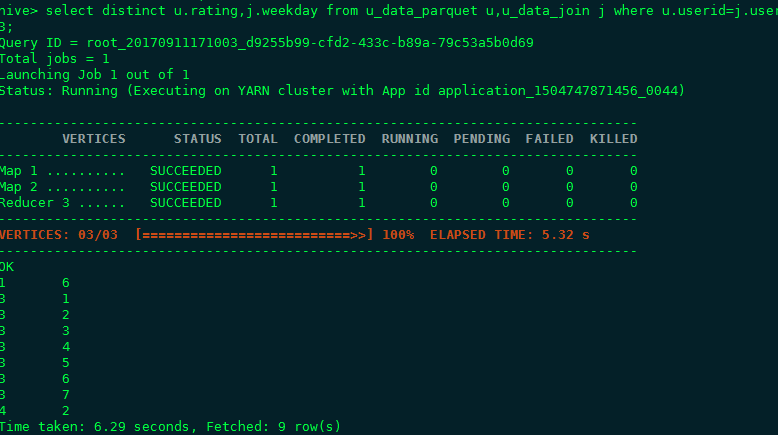
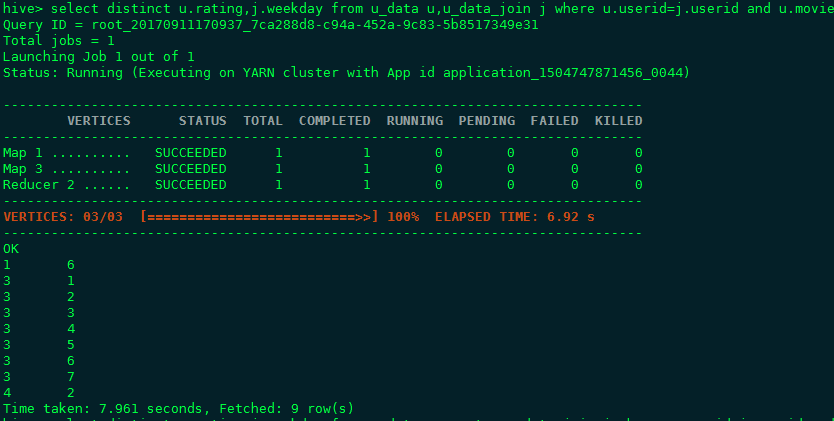
- 如何使用ORC格式 语法STORED AS orc
我们的数据,不论是从网络爬取的还是从mysql导出的,一般都是csv格式的文本文件(也就是行和列的文本格式,一般指定‘\t’为列分隔符,‘\n’为行分隔符),先 创建一个textfile格式的hive表:
CREATE TABLE ...... ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ STORED AS TEXTFILE;
然后将文件中的数据一次性load进hive表:
LOAD DATA LOCAL INPATH ‘<path>’ OVERWRITE INTO TABLE ..;
接着CREATE TABLE new_table STORED AS orc AS SELECT * FROM old_table;复制一个orcfile格式的hive表,再删掉旧表即可;
三、设计表结构时使用Partitions和Buckets
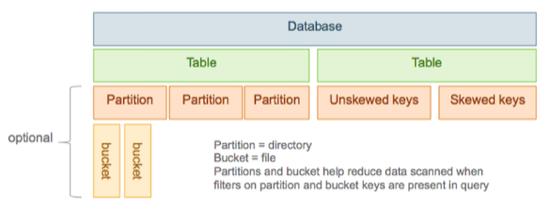
- CREATE TABLE sale(id int,amount decimal) PARTITIONED BY (date string)
创建表的时候指定一列或者多列来partition.常用的场景是按照日期来做partition,每天导入到Hive表中的都指定对应的partition,比如说:
INSERT INTO sale (date=”2017-9-12”) ... 这样这一天的所有数据在HDFS中都会保存到表目录下的名为2017-9-12的文件夹下。
这样在查询中只要涉及到日期这个字段都能大幅度提高查询性能,因为执行过滤的时候只需要去扫描partition文件夹,而不需要使用MapReduce扫描整个表来进行 过滤。
Partition使用起来较为方便,但是有几个需要注意的点:
1.绝不要对值唯一的列进行partition
2.规范好每一个partition的大小,最好大于1G
3.每一个查询语句不要处理超过100的partitions
- Bucket是对表的进一步细分,在HDFS中是Partition文件夹下面的文件,
一个Bucket对应一个文件。如果Hive表的容量变化比较频繁的话,不建议使用Bucket,因为需要动态的调整分桶,调整一些参数,不熟悉的话很容易引起性能问 题。Bucket典型的用法是用作随机取样,select语句后面跟:
TABLESAMPLING (BUCKET x OUT OF y)
四、优化查询语句
Hive主要是数据分析引擎,query语句是大部分使用场景,所以对查询语句的优化是非常有必要的。优化查询首先还是要保证两点:第一是保证语句先提交给Tez,而不是直接使用MapReduce,第二应该确认LLAP引擎正常运作。
接下来就要开始查询语句的优化了,我们知道查询语句最终还是会变成MapReduce任务来最终获取需要的结果,所以查询语句的优化本质上是MapReduce的优化,目的是为了MapReduce执行得更加有效率。
① 针对查询语句的配置修改
- 矢量化查询能够提升扫描,聚合,过滤和连接操作的性能,开启相关参数即可:
set hive.vectorized.execution.enabled = true;
set hive.vectorized.execution.reduce.enabled = true;
- 在Map端进行聚合操作:
set hive.map.aggr =true;
- 开启Hive的并行化执行:set hive.exec.parallel = true
- 出现group by 操作在reduce阶段耗费很长的时间,这种现象是由于数据倾斜造成的,也就是大部分数据都落到了同一个reducer上,在这种情况下需要配置:
set hive.tez.auto.reducer.parallelism=true ;
set hive.groupby.skewindata=true ;
set hive.optimize.skewjoin=true;
(其他时候不要这样设置,因为这样设置会增加reducer数量)
② 查询语句的改写
可以使用Hive View的工具对查询语句进行图形化的解释(Visual Explain),通过解释可以了解执行相关查询语句的时候会执行哪些操作步骤以及每个步骤涉及到的行数等详细信息。通过这些信息,我们可以直接比较查询语句的不同写法能够带来什么样的优化效果。比如说有group by子句和没有group by子句的两种不同写法的图形化解释,见下面例子,一个count功能的两种写法:
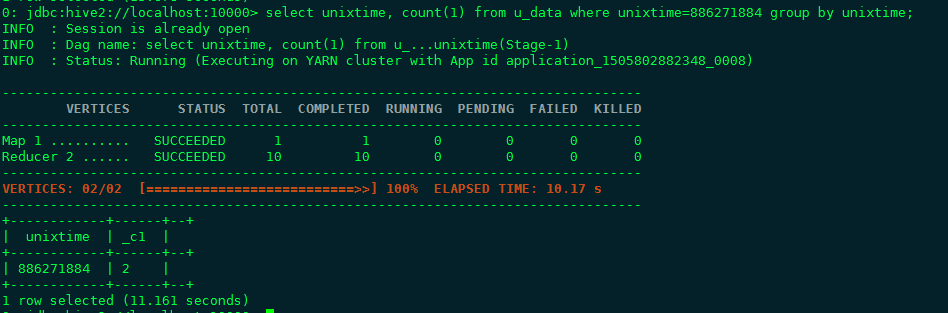
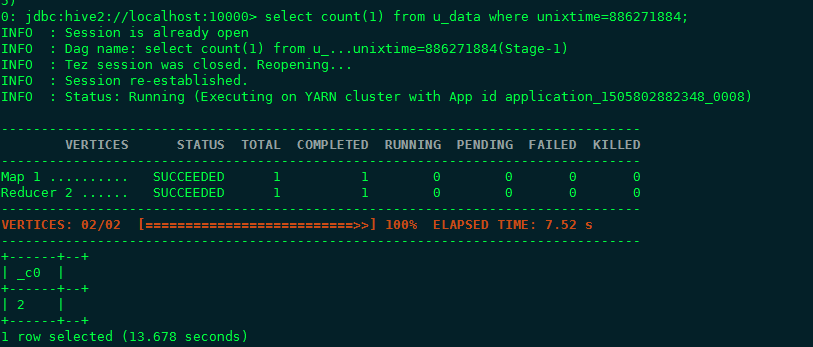
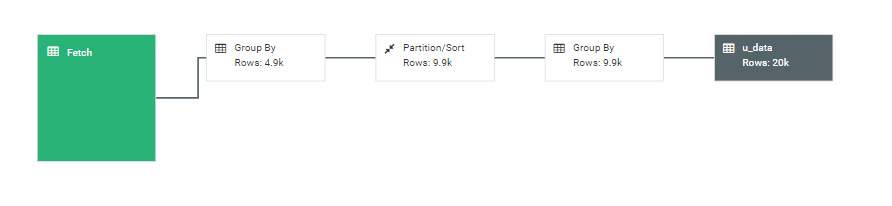
区别在于是否有group by子句,可以使用图形化工具解释两句的查询过程(从右至左):
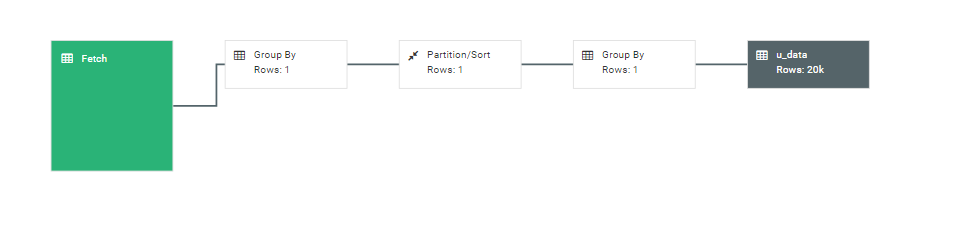
- 多表连接查询的时候,按照JOIN顺序中的最后一个表应该尽量是大表,因为JOIN前一阶段生成的数据会存在于Reducer的buffer中,通过stream最后面的表,直接从Reducer的buffer中读取已经缓冲的中间结果数据(这个中间结果数据可能是JOIN顺序中,前面表连接的结果的Key,数据量相对较小,内存开销就小),这样,与后面的大表进行连接时,只需要从buffer中读取缓存的Key,与大表中的指定Key进行连接,速度会更快,也可能避免内存缓冲区溢出。目前版本的Hive可以开启自动优化功能:
set hive.auto.convert.join = true
设置后,Hive会自动进行表连接的优化。但是对于一些比较复杂的多表查询, 需要在查询语句中隐式的手动声明顺序。例如:
SELECT /*+ STREAMTABLE(a) */ a.val, b.val, c.val
FROM a
JOIN b ON (a.key = b.key1)
JOIN c ON (c.key = b.key1);
a表被视为大表。
SELECT /*+ MAPJOIN(b) */ a.key, a.value
FROM a
JOIN b ON a.key = b.key;
MAPJION会把小表全部读入内存中
- 改写where子句。对于一些特殊的表连接查询时,有时候可以把过滤条件放到on 子句里面。比如:
SELECT a.val, b.val
FROM a
LEFT OUTER JOIN b ON (a.key=b.key)
WHERE a.ds='2009-07-07' AND b.ds='2009-07-07'
改写:
SELECT a.val, b.val
FROM a
LEFT OUTER JOIN b
ON (a.key=b.key AND b.ds='2009-07-07' AND a.ds='2009-07-07')
改写效果如图:
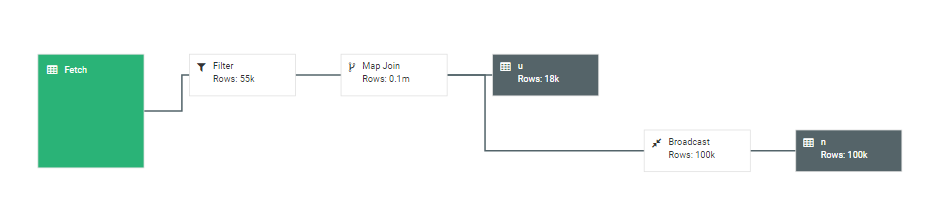
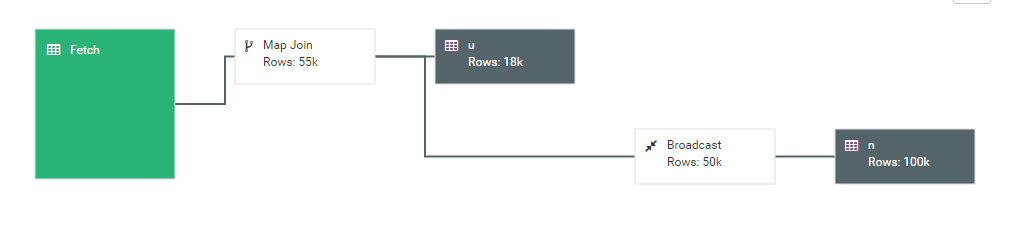
首先完成2表JOIN,然后再通过WHERE条件进行过滤,这样在JOIN过程中可能会输出大量结果,再对这些结果进行过滤,比较耗时。可以进行优化,将WHERE 条件放在ON后,在JOIN的过程中,就对不满足条件的记录进行了预先过滤。
五、使用CBO组件
对查询语句的修改优化需要不断的实践,同时需要对MapReduce的过程和各种操作有一定的了解。针对这种情况,Hive提供了一个工具:CBO()Cost-Based Optimizer.CBO是Hive查询引擎的核心组件,它能够优化和计算单个查询各个计划(即操作流程)的消耗。然后在内部对查询计划做一系列的优化和重写,最后会生成Tez上的jobs,在hadoop上最终执行获得结果。
CBO类似于一种静态代码检测工具,所以为了让CBO生效,需要事先让Hive分析对应的表。开启对列和表的静态分析:
|
Purpose |
Command |
|
对没有partitioned的表开启静态分析 |
ANALYZE TABLE [ |
|
对partitioned的表开启静态分析 |
ANALYZE TABLE [ |
|
对列开启静态分析 |
ANALYZE TABLE [ |
HDP Hive性能调优的更多相关文章
- Hive(十)Hive性能调优总结
一.Fetch抓取 1.理论分析 Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算.例如:SELECT * FROM employees;在这种情况下,Hive可以简单 ...
- Hive 性能调优
避免执行MR select * or select field1,field2 limit 10 where语句中只有分区字段或该表的本地字段 使用本地set hive.exec.mode.local ...
- Hive性能调优(二)----数据倾斜
Hive在分布式运行的时候最害怕的是数据倾斜,这是由于分布式系统的特性决定的,因为分布式系统之所以很快是由于作业平均分配给了不同的节点,不同节点同心协力,从而达到更快处理完作业的目的. Hive中数据 ...
- Hive性能调优(一)----文件存储格式及压缩方式选择
合理使用文件存储格式 建表时,尽量使用 orc.parquet 这些列式存储格式,因为列式存储的表,每一列的数据在物理上是存储在一起的,Hive查询时会只遍历需要列数据,大大减少处理的数据量. 采用合 ...
- Hive性能调优
表分为内部表.外部表.分区表,桶表.内部表.外部表.分区表对应的是目录,桶表对应目录下的文件.
- Spark性能调优之解决数据倾斜
Spark性能调优之解决数据倾斜 数据倾斜七种解决方案 shuffle的过程最容易引起数据倾斜 1.使用Hive ETL预处理数据 • 方案适用场景:如果导致数据倾斜的是Hive表.如果该Hiv ...
- Spark 常规性能调优
1. 常规性能调优 一:最优资源配置 Spark性能调优的第一步,就是为任务分配更多的资源,在一定范围内,增加资源的分配与性能的提升是成正比的,实现了最优的资源配置后,在此基础上再考虑进行后面论述的性 ...
- Informatica_(6)性能调优
六.实战汇总31.powercenter 字符集 了解源或者目标数据库的字符集,并在Powercenter服务器上设置相关的环境变量或者完成相关的设置,不同的数据库有不同的设置方法: 多数字符集的问题 ...
- Spark Streaming性能调优详解
Spark Streaming性能调优详解 Spark 2015-04-28 7:43:05 7896℃ 0评论 分享到微博 下载为PDF 2014 Spark亚太峰会会议资料下载.< ...
随机推荐
- mysql 正确清理binlog日志的两种方法
前言: MySQL中的binlog日志记录了数据库中数据的变动,便于对数据的基于时间点和基于位置的恢复,但是binlog也会日渐增大,占用很大的磁盘空间,因此,要对binlog使用正确安全的方法清理掉 ...
- 统计学习方法9—EM算法
EM算法是一种迭代算法,是一种用于计算包含隐变量概率模型的最大似然估计方法,或极大后验概率.EM即expectation maximization,期望最大化算法. 1. 极大似然估计 在概率 ...
- XTOJ 1267:Highway(树的直径)***
http://202.197.224.59/OnlineJudge2/index.php/Problem/read/id/1267 题意:给出一棵树,每条树边有权值,现在要修建n-1条边,边的权值为边 ...
- 超哥的 LINUX 入门大纲
前言 “Linux?听说是一个操作系统,好用吗?” “我也不知道呀,和windows有什么区别?我能在Linux上玩LOL吗” “别提了,我用过Linux,就是黑乎乎一个屏幕,鼠标也不能用,不停地的敲 ...
- c++稍微复杂桶排序(未完待续~)
由于上次的桶排序占用空间太多,这次又有了一个新的办法 直接上代码: #include <bits/stdc++.h> using namespace std; int n; void bu ...
- Android 开发你需要了解的那些事
本文微信公众号「AndroidTraveler」首发. 背景 最近部门有新入职员工,作为规划技术路线的导师,这边给新员工安排了学习路线. 除了基本的学习路线之外,每次沟通,我都留了一个小问题,让小伙伴 ...
- Java面试总结(一)
1.equals和==和hashcode “==”是运算符,比较两个变量的值是否相等 equals是Object类的方法.比较两个对象是否相等 hashcode是Object类的方法,返回一个 ...
- WPF 入门笔记之布局
一.布局原则: 1. 不应显示的设定元素的尺寸,反而元素可以改变它的尺寸,并适应它们的内容 2. 不应使用平布的坐标,指定元素的位置. 3. 布局容器和它的子元素是共享可以使用的空间 4. 可以嵌套的 ...
- 解决Tomcat catalina.out 不断膨胀,导致磁盘占用过大的问题
到服务器上看了一下任务中心的日志情况,膨胀的很快,必须采取措施限制其增长速度. 我们采用Cronlog组件对此进行日志切分,官网http://cronolog.org/一直未能打开,只能从其它地方寻找 ...
- 【UR #7】水题走四方 题解
链接:http://uoj.ac/problem/84 20分算法:萌萌的小爆搜,别搜进环里就行. 50分:我们考虑一下最优决策是什么样的.看似很显然的一点就是我们先让本体在原地不动,让分身去遍历子树 ...