awk 实用案例介绍
awk 简介
从文件输入
[root@desktop243 Desktop]# gawk -F: '/student/{print $3}' /etc/passwd
#-F:以":"号为分隔符分割出参数
[root@desktop243 Desktop]# gawk -F: '/student/{print $1,$3}' /etc/passwd
student
[root@desktop243 Desktop]# gawk -F: '/student/{print $0}' /etc/passwd
student:x::::/home/student:/bin/bash
awk 工作原理
[root@desktop243 Desktop]# vim names
Tome Savage
Molly Lee
John Doe
cut 无法识别空格键和<Tab>打出来的空格
[root@desktop243 Desktop]# cat names | cut -d ' ' -f
Tome
Molly Lee
John
[root@desktop243 Desktop]# cat names | cut -d ' ' -f
Savage
Doe
gawk能区分空格键和<Tab>打出来的空格,“,”是代表打印时$ 和$ 之间有空格
[root@desktop243 Desktop]# gawk '{ print $1,$3}' names
Tome
Molly
John

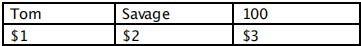
OFS,输出字段分隔符定义为两个制表符,“,”在输出时被制表符替换
[root@desktop243 Desktop]# gawk '{ OFS="\t\t";print $1,$3}' names
Tome
Molly
John
从命令输入
[root@desktop243 Desktop]# df | gawk '$3 > 100'
Filesystem 1K-blocks Used AvailableUse% Mounted on
% /
tmpfs % /dev/shm
/dev/sda1 % /boot
% /home
格式化输出 print 函数
[root@desktop243 Desktop]# date
Sat Oct :: CST
[root@desktop243 Desktop]# date | gawk '{print "Month: "$2"\nYear:",$6}'
Month: Oct
Year:
OFMT 变量
模拟分区大小的转换,保留小数点后 位:
[root@desktop243Desktop]#echo -e "/dev/sda1\t1234325\n/dev/sda3\t2209"\
> | gawk '{OFMT="%.2f";print $1":",$2/1024,"M"}'
/dev/sda1: 1205.40 M
/dev/sda3: 2.16 M
printf 函数转义字符
[root@desktop243 Desktop]# cat names
Tome Savage
Molly Lee
John Doe
names 文件中第 列的第一个字符:-%c 字符
[root@desktop243 Desktop]# gawk '{printf("The charcter is %c\n",$2)}' names
The charcter is S
The charcter is L
The charcter is D
names 文件中第 列的字符串:–%s 字符串
[root@desktop243 Desktop]# gawk '{printf("The string is %s\n",$2)}' names
The string is Savage
The string is Lee
The string is Doe
打印一个人的名字和年龄:–%d 十进制整数
规定好了是字符串或者整数,后面的变量就必须是与之匹配的类型,否则会出错。
[root@desktop243 Desktop]# echo "yangwawa 10"|gawk \
> '{printf("%s is %d years old.\n",$1,$2)}'
yangwawa is years old.
[root@desktop243 Desktop]# echo "yangwawa 10 155"|gawk\
> '{printf("%s is %d years old,his heigth si %.2fm.\n",$1,$2,$3/100)}'
yangwawa is years old,his heigth si 1.55m.
printf 函数修饰符
[root@desktop243 Desktop]# echo "Bluefox" | gawk '{printf("Welcome to \
> |%s| lab\n",$1)}'
Welcome to |Bluefox|lab
[root@desktop243 Desktop]# echo "Bluefox" | gawk '{printf("Welcome to\
> |%10s|lab\n",$1)}'
Welcome to | Bluefox|lab
[root@desktop243 Desktop]# echo "Bluefox" | gawk '{printf("Welcome to
> |%-10s|lab\n",$1)}'
Welcome to |Bluefox |lab
[root@desktop243 Desktop]# gawk '{printf("%s\t\t%s\t\t%d\n",$1,$2,$3)}' \
>names > name ;rm -f names ;mv name names
[root@desktop243 Desktop]# cat names
Tome Savage
Molly Lee
John Doe
文件中的 awk 命令
执行结果:
[root@desktop243 Desktop]# cat names | gawk -f abc.awk
________--------________
Nice to meet you -->Molly
________--------________
________--------________
John
代码:
[root@desktop243 Desktop]# cat abc.awk
#!/bin/gawk
/^[Mm]olly/{print "Nice to meet you -->"$}
{print "________--------________"}
$> {print $}
被测试的文件:
[root@desktop243 Desktop]# cat names
Tome Savage
Molly Lee
John Doe
分析:
程序开始后首先读到的$ 是 Tome Savage ,开始的字符既不是 M 也不是m, 后 面 的 {print "Nice to meet you -->"$}不 会 执 行 , 执 行 {print "________
--------________"}后,判断 100 不大于 200,则 {print $1}不执行;接着$0 是 Molly
Lee ,首字符串匹配,执行{print "Nice to meet you -->"$}的结果是
Nice to meet you -->Molly,然后执行下一句,执行最后一句时发现 不大于 ,
{print $}不执行;最后传给$0的是John Doe ,第一句由于不匹配而没有
执行,执行完第二句代码,最后 大于 ,所以执行{print $},结果是显示 John。
#!/bin/gawk
/^[Mm]olly/{print "Nice to meet you -->"$;\
print "________--------________"}
$> {print $}
再测试,结果:
[root@desktop243 Desktop]# gawk -f abc.awk names
Nice to meet you -->Molly
________--------________
John
记录与字段
默认:
[root@desktop243 Desktop]# gawk '{print $1,$2}' names
Tome Savage
Molly Lee
John Doe
自定义:
[root@desktop243 Desktop]# gawk 'ORS="\n+-+\n"{print $1,$2}' names
Tome Savage
+-+
Molly Lee
+-+
John Doe
+-+
[root@desktop243 Desktop]# echo "Mayy Daly" >> names
[root@desktop243 Desktop]# gawk '{print NF,$0}' names
Tome Savage
Molly Lee
John Doe
Mayy Daly
[root@desktop243 Desktop]# gawk '{print NR,": ->",$0}' /etc/passwd
: -> root:x:::root:/root:/bin/bash
: -> bin:x:::bin:/bin:/sbin/nologin
…… ……
: -> student:x::::/home/student:/bin/bash
: -> visitor:x::::/home/visitor:/bin/bash
字段分隔符
实例:
[root@desktop243Desktop]# cat /etc/passwd | gawk 'BEGIN{FS=":";print"--count
normal user now--"}$3 >= 500 { print $1;count++} END {printf("Total : %d
Normal users\n",count)}'
--count normal user now--
nfsnobody
student
visitor
Total : Normal users
默认是以空格为分隔符
[root@desktop243 Desktop]# gawk 'NR <= 4 {print NR,$1}' /etc/passwd
root:x:::root:/root:/bin/bash
bin:x:::bin:/bin:/sbin/nologin
daemon:x:::daemon:/sbin:/sbin/nologin
adm:x:::adm:/var/adm:/sbin/nologin
指定分隔符为“:”
[root@desktop243 Desktop]# gawk -F : 'NR <= 4 {print NR,$1}' /etc/passwd
root
bin
daemon
adm
模式
实例:
[root@desktop2 Desktop]# gawk '/^root/' /etc/passwd
root:x:::root:/root:/bin/bash
[root@desktop2 Desktop]# gawk '/^root/ || /^student/' /etc/passwd
root:x:::root:/root:/bin/bash
student:x::::/home/student:/bin/bash
[root@desktop2 Desktop]# gawk -F: '/student/{print $1":"$3}' /etc/passwd
student:
[root@desktop2 Desktop]# gawk '/^sshd/,/^stude*/' /etc/passwd
sshd:x:::Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
nslcd:x:::LDAP Client User:/:/sbin/nologin
tcpdump:x::::/:/sbin/nologin
pulse:x:::PulseAudio System Daemon:/var/run/pulse:/sbin/nologin
gdm:x::::/var/lib/gdm:/sbin/nologin
student:x::::/home/student:/bin/bash
操作
模式 { 操作语句 1 操作语句 2 ...... }
正则表达式
匹配操作符
[root@desktop2 Desktop]# gawk -F: '$1 ~ /[sS]tud*/{print $1":"$3}' /etc/passwd
student:
POSIX 字符类表达式
awk 脚本
[root@desktop2 Desktop]#vim info
#!/bin/gawk
# The first awk script
/student/ { print "Studentid is" , $}
/vistor/ {print "vistor id is", $}
运行:
[root@desktop2 Desktop]#gawk -F: -f info /etc/passwd
比较表达式
条件表达式
[root@desktop2Desktop]#echo "111 333"| gawk '{max=$1>$2?$1:$2;print max}'
[root@desktop Desktop]# cat /etc/passwd | gawk -F: '{printf("%s is %s
user\n",$1,$3 >= 500?"Normal":"System") }'
rootis System user
bin is System user
…… ……
student is Normal user
visitor is Normal user
算术运算
逻辑操作符
范围模式
验证数据的有效性
[root@shiyan ~]# cat employees
Name Numbers Time Price
Tome //
Marry //
Molly //
John //
Tome //
Molly //
John //
[root@shiyan ~]# gawk 'NF !=4 {print NR,": has only",NF,"fileds"}' employees
: has only fileds
: has only fileds
数值变量和字符串变量
用户自定义变量
[root@sya ~]#gawk'$1~/^T/{wage=$2*$4;print$1,$3,"wage:",wage}' ./employees
Tome // wage:
Tome // wage:
BEGIN 模式
[root@shiyan ~]# gawk 'BEGIN{FS=":";OFS="\t\t";ORS="\n****\n"} NR >=20 &&
NR <= {print $,$NF}' /etc/passwd
smmsp /sbin/nologin
****
nscd /sbin/nologin
****
oprofile /sbin/nologin
****
pcap /sbin/nologin
****
[root@desktop1 Desktop]# echo "$(date +%F)" | gawk 'BEGIN{FS="-";} \
> { print $"/"$"/"$}'
//
[root@shiyan ~]# gawk 'BEGIN{print "Hello World"}'
Hello World
END 模式
[root@shiyan ~]# gawk 'END{print "Total user:",NR}' /etc/passwd
Total user:
[root@shiyan ~]#gawk '/^<Virt/ { total++ } END { print total, virtual hosts }'
/etc/httpd/httpd.conf
virtual hosts
输出重定向
[root@shiyan ~]# vim rw.awk
#!/bin/gawk
{ \
if ( NF != ) \
{ \
print "Line",NR,":missing some info" \
}else{ \
print $,"saled:",$*$ > "/root/cc"\
} \
}
测试:
[root@shiyan ~]# gawk -f rw.awk employees
Line :missing some info
Line :missing some info
[root@shiyan ~]# cat cc
Tome saled:
Marry saled:
Molly saled:
John saled:
John saled:
输入重定向-读输入 getline
[root@shiyan ~]# gawk 'BEGIN{"date"| getline DATE}{print DATE,$1,$7}'
/etc/passwd
年 月 日 星期六 :: CST root:x:::root:/root:/bin/bash
年 月 日 星期六 :: CST bin:x:::bin:/bin:/sbin/nologin
…… ……
[root@shiyan ~]# gawk 'BEGIN{"date +%F"| getline DATE}{print DATE,$1,$7}'
/etc/passwd
-- root:x:::root:/root:/bin/bash
-- bin:x:::bin:/bin:/sbin/nologin
…… ……
[root@shiyan ~]# gawk 'BEGIN{print"What is your name?";\
>getline name < "/dev/tty"}\
>$ ~ name{print "Found",name,"online",NR".";\
>print"NIce to meet you",name,"@_@"}' /etc/passwd
Whatis your name?
student #getline 是重定向到终端接受的
Found student online .
NIce to meet you student @_@
Bash 向 awk 发送参数
[root@shiyan ~]# echo "$(date +%F)"|gawk 'BEGIN{ FS=":";\
>getline D < "-"}NR>={print D" "$"/"$":"$}' /etc/passwd
-- avahi-autoipd/:/sbin/nologin
-- student/:/bin/bash
-- visitor/:/bin/bash
-- oracle/:/bin/bash
管道
[root@shiyan ~]# gawk '/^[^#:]+/{print $1}' /etc/hosts
127.0.0.1
172.24.205.191
172.24.200.254
172.24.254.254
[root@shiyan ~]# gawk '/^[^#:]+/{print $1 |"ping -c2 "$1}' /etc/hosts
PING 127.0.0.1 (127.0.0.1) () bytes of data.
bytes from 127.0.0.1: icmp_seq= ttl= time=0.028 ms
connect: Network is unreachable
connect: Network is unreachable
connect: Network is unreachable
bytes from 127.0.0.1: icmp_seq= ttl= time=0.037 ms
--- 127.0.0.1 ping statistics ---
packets transmitted, received, % packetloss, time 999ms
rtt min/avg/max/mdev = 0.028/0.032/0.037/0.007 ms
关闭文件和管道
system 函数
[root@desktop1 Desktop]# gawk '/^[^#:]/{ if(system("ping -c2 "
$" > /dev/null")== ){print $" is on line"}else{ print $" is down"}}' /etc/hosts
127.0.0.1 is on line
172.24.0.2 is down
172.24.200.254 is on line
172.24.254.254 is on line
注意里面的空格“ ” !
if 语句
if/else 语句
if/else 和 else if 语句
while 循环
[root@desktop Desktop]# gawk -F: '{print NR,":User info:\n======";i=1;
while(i<=NF){print $i;i++};print "\n"}' /etc/passwd
:User info:
======
root
x
root
/root
/bin/bash
…… ……
:User info:
======
visitor
x
/home/visitor
/bin/bash
for 循环
[root@desktop Desktop]# gawk -F: '{print NR,":User info:\n======";
i=;for(;i<=NF;i++){print $i};print "\n"}' /etc/passwd
:User info:
======
root
x
root
/root
/bin/bash
:User info:
======
bin
x
bin
/bin
/sbin/nologin
…… ……
循环控制
为了方便实验,创建一个/tmp/passwd:
[root@localhost ~]# cat /tmp/passwd
avahi-autoipd:x:::avahi-autoipd:/var/lib/avahi-autoipd:/sbin/nologin
student:x::::/home/student:/bin/bash
visitor:x::::/home/visitor:/bin/bash
harry:x::::/home/harry:/bin/bash
[root@desktop Desktop]# gawk -F: '{i=1;
while(i++ < NF ){
if($i~/daemon/)
{print NR,$;break;}
}
}' /etc/passwd
daemon
haldaemon
avahi
continue 语句:会将匹配的这行其他段打印出来,继续往下查询
[root@localhost ~]# cat /tmp/passwd | gawk -F: '{ i=0;
while(i++ < NF){if($i~/student/){ print "========";continue; }
else { print $i ;}}}'
avahi-autoipd
x avahi-autoipd
/var/lib/avahi-autoipd
/sbin/nologin
========
x ========
/bin/bash
visitor
x /home/visitor
/bin/bash
harry
x /home/harry
/bin/bash
break 语句:匹配的这行其他段都不会打印,继续往下查询
[root@localhost ~]# cat /tmp/passwd | gawk -F: '{ i=0;
while(i++ < NF){if($i~/student/){ print "========";break; }
else { print $i ;}}}'
avahi-autoipd
x avahi-autoipd
/var/lib/avahi-autoipd
/sbin/nologin
========
visitor
x /home/visitor
/bin/bash
harry
x /home/harry
/bin/bash
next 语句
[root@desktop18 Desktop]# gawk -F: '{if($3<500){next;}else{print $1}}'
/etc/passwd
nfsnobody
student
visitor
exit 语句
exit,找到匹配的就会退出,返回 ,不再往下查询:
[root@localhost ~]# cat /tmp/passwd | gawk -F: '{ i=0;while(i++ <
NF){if($i~/student/){ print "========";exit(); } else { print $i ;}}}'
avahi-autoipd
x avahi-autoipd
/var/lib/avahi-autoipd
/sbin/nologin
========
[root@localhost ~]# echo $?
关联数组的下标
[root@desktop18 Desktop]# vim employess
Tom //
Mary //
Bill //
Mary //
Tom //
[root@desktop18 Desktop]# gawk '{ name[k++]=$1} END{for(i=0;i<NR;i++){
printi,name[i]}}' employess
Tom
Mary
Bill
Mary
Tom
用字符串作为数组的下标

将用户名($)相同的行的工资($)相加
[root@desktop18 Desktop]# gawk '{ name[$1]+=$4} END{for(Name in name){
print Name,":",name[Name]}}' employess
Tom :
Mary :
Bill :
处理命令行参数
[root@desktop18 Desktop]# vim argvs
#!/bin/gawk
BEGIN{\
for ( i=;i < ARGC ; i++ )\
{ \
printf( "ARGV[%d] is --> %s\n",i,ARGV[i])\
}\
printf( "Total : %d parameters\n",ARGC);\
}
[root@desktop18 Desktop]# gawk -f argvs /etc /root 172.24.200.254
ARGV[] is --> gawk
ARGV[] is --> /etc
ARGV[] is --> /root
ARGV[] is -->
ARGV[] is --> 172.24.200.254
Total : parameters
[root@desktop18 Desktop]# gawk -f argvs /etc "ls /root"
ARGV[] is --> gawk
ARGV[] is --> /etc
ARGV[] is --> ls /root
Total : parameters
[root@desktop18 Desktop]# echo "172.24.200.254" | xargs ping -c2
PING 172.24.200.254 (172.24.200.254) () bytes of data.
From 192.168.117.167 icmp_seq= Destination Host Unreachable
From 192.168.117.167 icmp_seq= Destination Host Unreachable
--- 172.24.200.254 ping statistics ---
packets transmitted, received, + errors, % packetloss, time 3000ms
pipe
[root@desktop18 Desktop]# echo "172.24.200.254 /etc/passwd /root" | xargs
gawk -f argvs
ARGV[] is --> gawk
ARGV[] is --> 172.24.200.254
ARGV[] is --> /etc/passwd
ARGV[] is --> /root
Total : parameters
字符串 sub 和 gsub 函数
[root@desk18Desktop]# gawk '{sub(/[Tt]om/,"ttooomm",$1);print $0}' employess
ttooomm //
Mary //
Bill //
Mary //
ttooomm //
sub:只对匹配部分一次替换
[root@desktop18 Desktop]# gawk '{sub(/0/,"kkkkk");print $0}' employess
Tom 2kkkkk08//
Mary 2kkkkk08//
Bill 2kkkkk09//
Mary 2kkkkk09//
Tom 2kkkkk09//
gsub 全部替换
[root@desktop18 Desktop]# gawk '{gsub(/0/,"kkkkk");print $0}' employess
Tom 2kkkkkkkkkk8/kkkkk3/kkkkk5
Mary 2kkkkkkkkkk8/kkkkk4/kkkkk6
Bill 2kkkkkkkkkk9/1kkkkk/kkkkk9
Mary 2kkkkkkkkkk9/1kkkkk/
Tom 2kkkkkkkkkk9//1kkkkk
sub 函数示例
字符串长度 length 函数
带参数:
[root@desktop18 Desktop]# echo "123qwe" | gawk 'BEGIN{getline RR <"-";print
length(RR)}' [root@desktop18 Desktop]# gawk '{print $1,length($1)}' employess
Tom
Mary
Bill
Mary
Tom
不带参数:
[root@desktop18 Desktop]# gawk '{print $1,length}' employess
Tom
Mary
Bill
Mary
Tom
字符 substr 函数
[root@desktop18 Desktop]# gawk '{print substr($1,2,length)}' employess
om
ary
字符 match 函数
[root@desktop18 Desktop]# gawk '{print $3}' employess --
--
//
--
--
[root@desktop18 Desktop]# gawk '{match($3,/[12][0-9][0-9][0-9]/);
print $,substr($,RSTART,RLENGTH)}' employess
Tom
Mary
Bill
Mary
Tom
字符 split 函数
[root@desktop18 Desktop]# cat database
-- car
-- car
-- dog
-- bike
统计 月份的销售总额:
[root@desktop18 Desktop]# gawk '{
>split($,DATE,"-");
> if(DATE[] == ){
> count+=$
> }
>}
>END{
> print "May : "count
>}' database
May :
整数 int 函数
生成随机数
[root@desktop18 Desktop]# gawk '{print NR,rand()}' database
0.237788
0.291066
0.845814
0.152208
[root@desktop18 Desktop]# gawk '{print NR,rand()}' /etc/passwd
0.237788
0.291066
0.845814
0.152208
…… ……
0.377663
0.899756
当有种子时,生成的随机数不同文件或同一文件相同行的随机数是不一样的,文件有多少行
就生成多少个随机数
[root@desktop18 Desktop]# gawk 'BEGIN{srand()}{print NR,rand()}' database
0.78965
0.970641
0.284081
0.819256
[root@desktop18 Desktop]# gawk 'BEGIN{srand()}{print NR,rand()}' database
0.532605
0.737259
0.105589
0.0879184
技能掌握测试题:
题1:
[root@desktop215 Desktop]# gawk '{
> split($,DATE,"-"); 先将日期的月份拆分成一个数组
> if(DATE[] == ){
> name[$]+=$}
> }
# 如果月份是 月,就将以姓名(字符串)为数组下标,将相同名字的销售额相
> END{
> for(Name in name){
> print Name,": 05",name[Name]}
> }' sales
Tom :
Mary :
方法 :
[root@desktop215 Desktop]# gawk '
$ ~ //{name[$]+=$}
END{
for(Name in name){
print Name,": 05",name[Name]}
}' sales
Tom :
Mary :
题二:
[root@desktop215 Desktop]# gawk '{OFS="\t"; print $1,
substr($,,)"-"substr($,,)"-"substr($,,),
$,$,$}' sales2 > /root/Desktop/sales3
[root@desktop215 Desktop]# cat /root/Desktop/sales3
Tom -- car
Mary -- car
Tom -- bike
Mary -- car
导入数据库:
mysql> use bluefox;
Database changed
mysql> create table sale( name varchar(), time date, spes varchar(), num
int(), money int() );
Query OK, rows affected (0.11 sec)
mysql> select * from sale;
+------+------------+------+------+-------+
| name | time | spes | num | money |
+------+------------+------+------+-------+
| Tom | -- | car | | |
| Mary | -- | car | | |
| Tom | -- | bike | | |
| Mary | -- | car | | |
+------+------------+------+------+-------+
rows in set (0.00 sec)
awk 实用案例介绍的更多相关文章
- SQL Delta实用案例介绍,很好的东西,帮了我不少忙
SQL Delta实用案例介绍 概述 本篇文章主要介绍SQL DELTA的简单使用.为了能够更加明了的说明其功能,本文将通过实际项目中的案例加以介绍. 主要容 SQL DELTA 简介 ...
- SQL Delta实用案例介绍
概述 本篇文章主要介绍SQL DELTA的简单使用.为了能够更加明了的说明其功能,本文将通过实际项目中的案例加以介绍. 主要容 SQL DELTA 简介 创建SQL DELTA项目 ...
- SQL Delta实用案例介绍 (对应软件)
http://blog.csdn.net/hongdi/article/details/5363209
- JAVA实用案例之水印开发
写在最前面 上周零零碎碎花了一周的时间研究水印的开发,现在终于写了个入门级的Demo,做下笔记同时分享出来供大家参考. Demo是在我上次写的 JAVA实用案例之文件导入导出(POI方式) 框架基础上 ...
- JAVA实用案例之图片水印开发
写在最前面 上周零零碎碎花了一周的时间研究水印的开发,现在终于写了个入门级的Demo,做下笔记同时分享出来供大家参考. Demo是在我上次写的 JAVA实用案例之文件导入导出(POI方式) 框架基础上 ...
- JAVA实用案例之文件导出(JasperReport踩坑实录)
写在最前面 想想来新公司也快五个月了,恍惚一瞬间. 翻了翻博客,因为太忙,也有将近五个多月没认真总结过了. 正好趁着今天老婆出门团建的机会,记录下最近这段时间遇到的大坑-JasperReport. 六 ...
- InfluxDB 聚合函数实用案例
InfluxDB 聚合函数实用案例 文章大纲 InfluxDB 简介 InfluxDB是GO语言编写的分布式时间序列化数据库,非常适合对数据(跟随时间变化而变化的数据)的跟踪.监控和分析.在我们的项目 ...
- 精选19款华丽的HTML5动画和实用案例
下面是本人收集的19款超酷HTML5动画和实用案例,觉得不错,分享给大家. 1.HTML5 Canvas火焰喷射动画效果 还记得以前分享过的一款HTML5烟花动画HTML5 Canvas烟花特效,今天 ...
- 3星|《AI极简经济学》:AI的预测、决策、战略等方面的应用案例介绍
AI极简经济学 主要内容是AI的各种应用案例介绍.作者把这些案例分到五个部分介绍:预测.决策.工具.战略.社会. 看书名和介绍以为会从经济学的角度解读AI,有更多的新鲜的视角和观点,读后比较失望,基本 ...
随机推荐
- drf框架中jwt认证,以及自定义jwt认证
0909自我总结 drf框架中jwt 一.模块的安装 官方:http://getblimp.github.io/django-rest-framework-jwt/ 他是个第三方的开源项目 安装:pi ...
- 浏览器渗透框架BeEF使用笔记(一)
0x00 前言 BeEF,全称The Browser Exploitation Framework,是一款针对浏览器的渗透测试工具. 用Ruby语言开发的,Kali中默认安装的一个模块,用于实现对XS ...
- jquery 获取input的值
$("input").attr("value") -- 获取的是input的默认值 $("input").val() ...
- Dropzone.js
2015-11-25 发布 DropzoneJS 官网没有中文版的,很多东西只能跟着自己的感觉去理解,有些地方把握不了是否准确,在网上搜了一下中文版,看到一位大神简易的中文版 个人觉得和原官网对比着看 ...
- python属性的默认值
python类的构造函数中属性可以设置默认值,实例化出来的对象如果属性使用默认值,默认值的地址是相同的. class A: def __init__(self, name = []): self.__ ...
- chrome devtools tip(1)--调试伪类
开发中我们经常遇到,添加些focus,hover事件,样式,但当我们去打开 chrome devtools,浮动上去的时候,然后准备去改变样式的时候,结果由于光标移动了,样式不见了,非常不方便调试,其 ...
- ESP32 开发之旅① 走进ESP32的世界 安装开发环境
1.前言 欢迎大家来到ESP32的世界,从现在开始,笔者将带领大家慢慢揭开ESP32神秘的面纱. 在学习ESP32之前,博主希望读者能有ESP8266的学习基础(ESP32 Wifi模 ...
- epoll(2) 源码分析
epoll(2) 源码分析 文本内核代码取自 5.0.18 版本,和上一篇文章中的版本不同是因为另一个电脑出了问题,但是总体差异不大. 引子留下的问题 关键数据结构 提供的系统调用 就绪事件相关逻辑 ...
- Redux的核心概念,实现代码与应用示例
Redux是一种JavaScript的状态管理容器,是一个独立的状态管理库,可配合其它框架使用,比如React.引入Redux主要为了使JavaScript中数据管理的方便,易追踪,避免在大型的Jav ...
- python之ORM(对象关系映射)
实现了数据模型与数据库的解耦,通过简单的配置就可以轻松更换数据库,而不需要更改代码.orm操作本质上会根据对接的数据库引擎,翻译成对应的sql语句.所有使用Django开发的项目无需关心程序底层使用的 ...