python爬虫—— 抓取今日头条的街拍的妹子图
AJAX 是一种用于创建快速动态网页的技术。 通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
近期在学习获取js动态加载网页的爬虫,决定通过实例加深理解。
1、首先是url的研究(谷歌浏览器的审查功能)
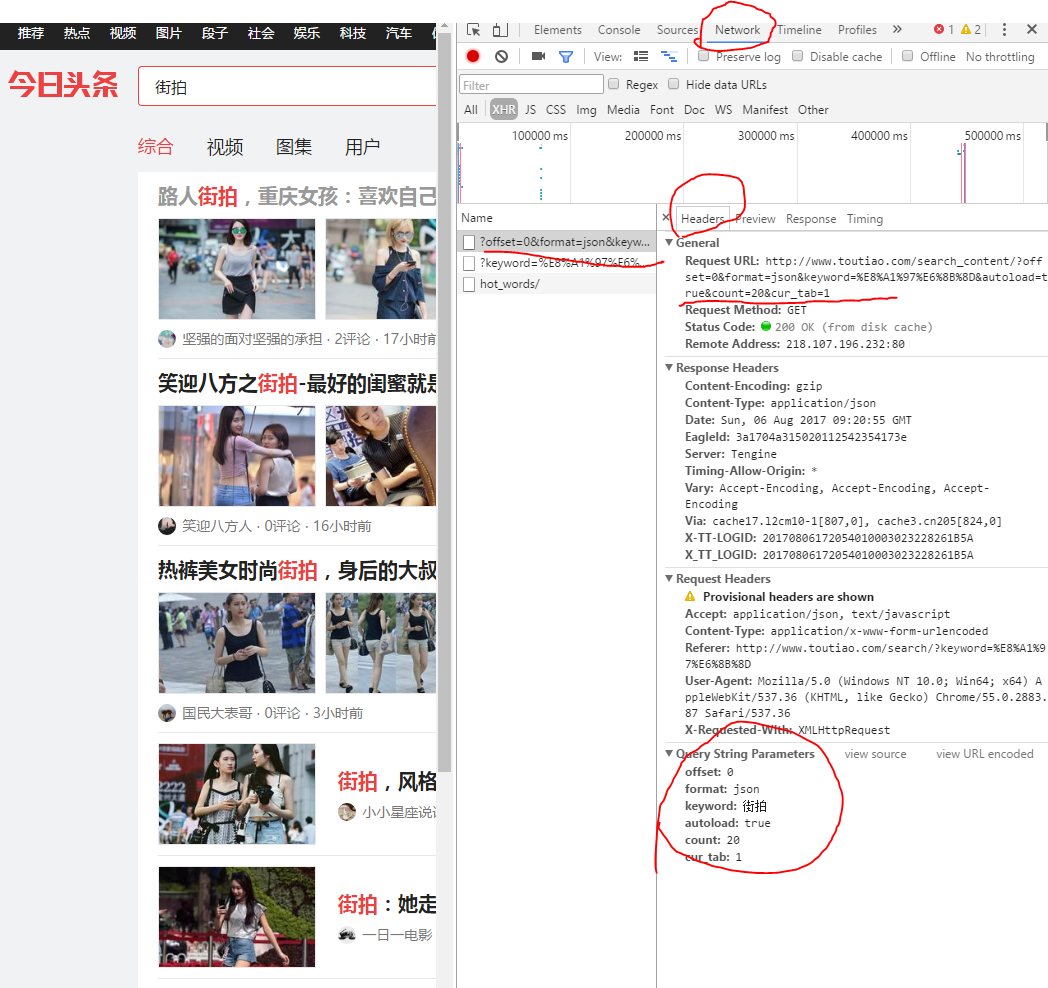
http://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&cur_tab=1
对应用get方法到url上获取信息。网页对应offset=0 、keyword=%E8%A1%97%E6%8B%8D 是会变的。如果要批量爬取,就得设置循环。
当网页下拉,offset会20、40、60的变化,其实就是每次加载20个内容。
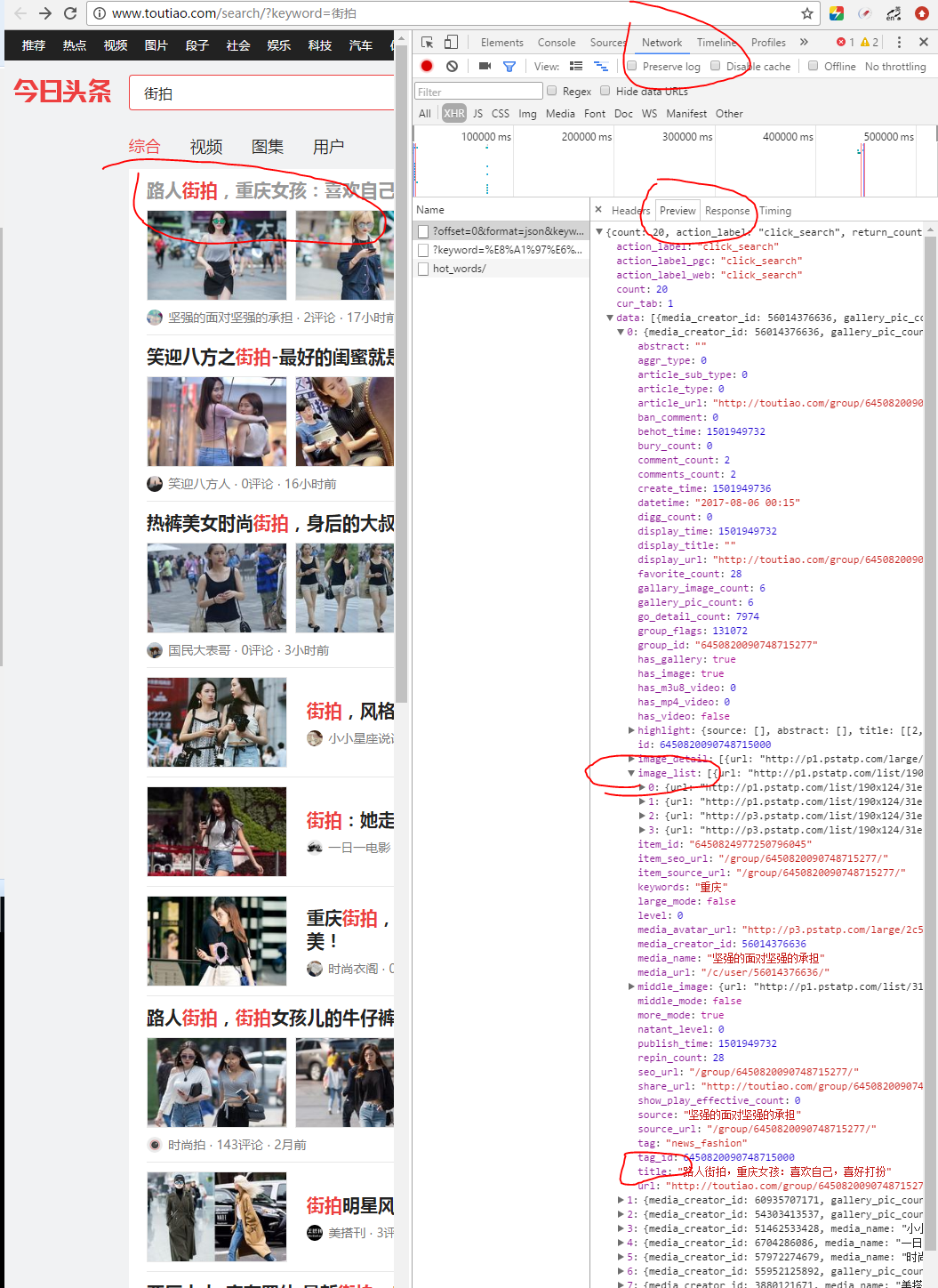
2、
通过requests获得response,进行json解析。
还是一样的网页,切换到Preview,可以看到json的数据内容。title在['date'][0]['title']下,其他类似。
import json
import requests,os
def download_pic(file,name,html):
r = requests.get(html)
filename=os.path.join(file,name+'.jpg')
with open(filename,'wb') as f:
f.write(r.content) url = 'http://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&cur_tab=1' res = requests.get(url)
json_data = json.loads(res.text)
data = json_data['data']
for i in data:
print i['title']
file_path = os.getcwd()+'\image'
print file_path
for p in i['image_detail']:
print p['url']
name = p['url'].split('/')[-1]
download_pic(file_path,name,p['url'])
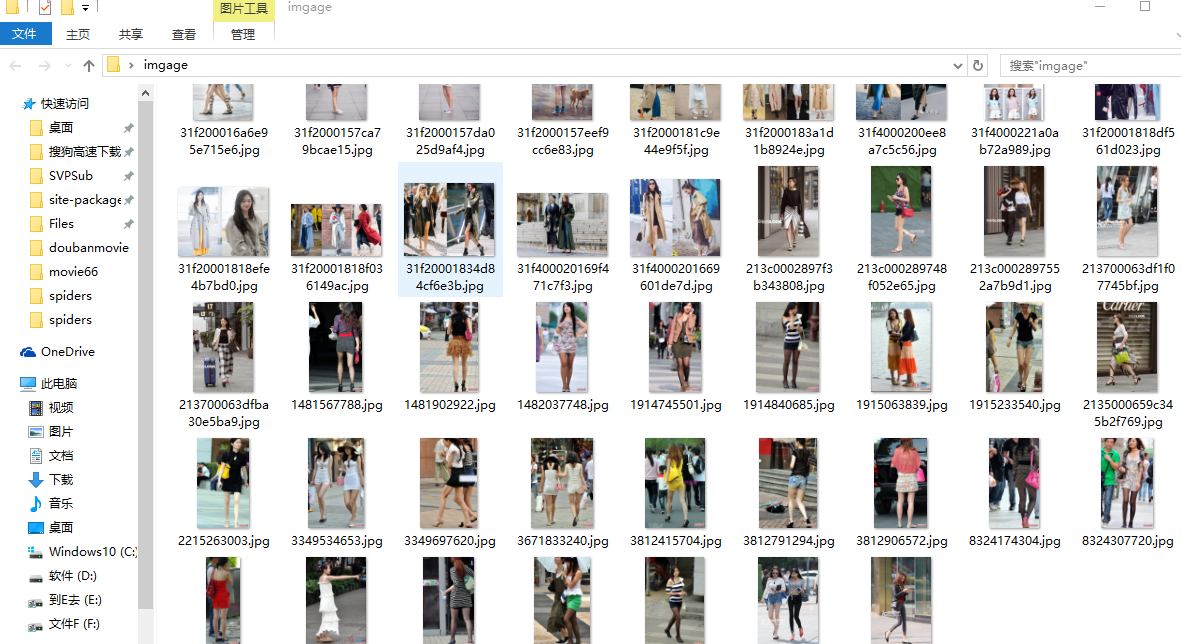
在当前目录新建image文件夹,然后爬虫下载图片。
图片名截取url链接的后面部分31e30003d4be75c719ae.jpg
例如http://p3.pstatp.com/large/31e30003d4be75c719ae
结果如下:(仅供学习交流)
循环什么的没写只爬取前20个链接的图片。
--------------------------------------------------------------------------------------------------------------
http://jandan.net/ooxx——煎蛋网
同样是妹子图,有些网页不涉及json动态加载的就比较简单了,用beautifulsoup即可
贴上代码匿了
import requests,os,time
from bs4 import BeautifulSoup
def download_pic(file,name,html):
r = requests.get(html)
filename=os.path.join(file,name+'.jpg')
with open(filename,'wb') as f:
f.write(r.content) def get_url(url):
res = requests.get(url)
soup = BeautifulSoup(res.text,'lxml')
data = soup.select(' div.text > p > img')
print data
for i in data:
s = i.attrs['src'][2:]
print s
file_path = os.getcwd()+'\imgage1'
print file_path
name = i.attrs['src'].split('/')[-1]
download_pic(file_path,name,'http://'+s) for i in reversed(range(236)):
url = 'http://jandan.net/ooxx/page-'+str(i)+'#comments'
if requests.get(url).status_code == 200:
get_url(url)
time.sleep(5)
python爬虫—— 抓取今日头条的街拍的妹子图的更多相关文章
- 分析 ajax 请求并抓取 “今日头条的街拍图”
今日头条抓取页面: 分析街拍页面的 ajax 请求: 通过在 XHR 中查看内容,获取 url 链接,params 参数信息,将两者进行拼接后取得完整 url 地址.data 中的 article_u ...
- 分析AJAX抓取今日头条的街拍美图并把信息存入mongodb中
今天学习分析ajax 请求,现把学得记录, 把我们在今日头条搜索街拍美图的时候,今日头条会发起ajax请求去请求图片,所以我们在网页源码中不能找到图片的url,但是今日头条网页中有一个json 文件, ...
- python多线程爬取-今日头条的街拍数据(附源码加思路注释)
这里用的是json+re+requests+beautifulsoup+多线程 1 import json import re from multiprocessing.pool import Poo ...
- Python Spider 抓取今日头条街拍美图
""" 抓取今日头条街拍美图 """ import os import time import requests from hashlib ...
- Python 爬虫爬取今日头条街拍上的图片
# 今日头条--街拍 import requests from urllib.parse import urlencode import os from hashlib import md5 from ...
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- 15-分析Ajax请求并抓取今日头条街拍美图
流程框架: 抓取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果. 抓取详情页内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 下载图片与保存数据库:将 ...
- 分析ajax请求抓取今日头条关键字美图
# 目标:抓取今日头条关键字美图 # 思路: # 一.分析目标站点 # 二.构造ajax请求,用requests请求到索引页的内容,正则+BeautifulSoup得到索引url # 三.对索引url ...
- python 爬虫抓取心得
quanwei9958 转自 python 爬虫抓取心得分享 urllib.quote('要编码的字符串') 如果你要在url请求里面放入中文,对相应的中文进行编码的话,可以用: urllib.quo ...
随机推荐
- 2019DX#8
Solved Pro.ID Title Ratio(Accepted / Submitted) 1001 Acesrc and Cube Hypernet 7.32%(3/41) 1002 A ...
- gym/101873/GCPC2017
题目链接:https://codeforces.com/gym/101873 C. Joyride 记忆化搜索形式的dp #include <algorithm> #include < ...
- “玲珑杯”ACM比赛 Round #18 C -- 图论你先敲完模板(和题目一点关系都没有,dp)
题目链接:http://www.ifrog.cc/acm/problem/1146?contest=1020&no=2 题解:显然知道这是一道dp而且 dp[i]=min(dp[j]+2^(x ...
- Codeforces Round #391 C. Felicity is Coming!
题目链接 http://codeforces.com/contest/757/problem/C 题意:给你n组数范围在1-m,可进行变换f(x)=y,就是将所有的x全变成y,最后 要满足变化后每组数 ...
- 携程PMO--小罗说敏捷之WIP限制在制品
转自本人运营的公众号“ 携程技术中心PMO”(ID:cso_pmo) WIP是什么? WIP(work in progress)指的就是工作中心在制品区.在经过部分制程之后,还没有 ...
- 【Offer】[53-3] 【数组中数值和下标相等的元素】
题目描述 思路分析 测试用例 Java代码 代码链接 题目描述 假设一个单调递增的数组里的每个元素都是整数并且是唯一的.请编程实现一个函数,找出数组中任意一个数值等于其下标的元素.例如,在数组{-3, ...
- 【Offer】[50-1] 【第一个只出现一次的字符】
题目描述 思路分析 测试用例 Java代码 代码链接 题目描述 在字符串中找出第一个只出现一次的字符.如输入"abaccdeff",则输出'b'. 牛客网刷题地址 思路分析 可以遍 ...
- 【LeetCode】33-搜索旋转排序数组
题目描述 假设按照升序排序的数组在预先未知的某个点上进行了旋转. ( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] ). 搜索一个给定的目标值,如果数组中存在这 ...
- 解决subline安装插件被墙失败的方法
一.问题场景描述 当你完成subline和package control的安装后,准备使用install package安装各种各样的插件来丰富你的编辑器,却出现类似 “Unable to downl ...
- Spring错误
今天在学习spring的aop操作时碰到了一个问题: Caused by: org.springframework.aop.framework.AopConfigException: Cannot p ...