在NodeJS中使用Redis缓存数据
Redis数据库采用极简的设计思想,最新版的源码包还不到2Mb。其在使用上也有别于一般的数据库。
node_redis
redis驱动程序多使用 node_redis 此模块可搭载官方的 hiredis C 语言库 - 同样是非阻塞的,比使用JavaScript内置的解释器性能稍好。可选择将hiredis 与 redis 一同安装。
- npm install hiredis redis
如果 hiredis 安装成功, node_redis 会默认使用 hiredis, 否则会使用JavaScript的解释器。
Redis的一个Key不仅可以对应一个String类型的值,还支持hashes, lists, sets, sorted sets, bitmaps等。
比如存/取一组Hash值,Redis中有两个对应的命令
HMSET key field value [field value ...]、 为一个Key一次设置多个哈希键/值, 多用于JSON对象的写入(序列化的SESSION)。
HGETALL key 读取一个Key的所有 哈希键/值,多用于JSON对象读取
这两个命令即是在NodeJS中存取JSON对象的关键,
下面是node_reids中对应的例子:
- var redis = require("redis"),
- client = redis.createClient();
- //写入JavaScript(JSON)对象
- client.hmset(‘sessionid‘, { username: ‘kris‘, password: ‘password‘ }, function(err) {
- console.log(err)
- })
- //读取JavaScript(JSON)对象
- client.hgetall(‘sessionid‘, function(err, object) {
- console.log(object)
- })
Redis没有严格意义上的表名和字段名,以 Key-Value 键值对的方式存储,因此一般采用 schema:key 形式做为键值,其中
schema: 可理解为传统数据库中的表名 key: 可理解为表中的主键
因此使用redis存放你的session时,需要一个schema前辍, 比如这个key: sessionid:i4w3axuzyj4nwwg75y6k5us2
Redis 也仅能对Key进行检索, 尚不支持对Key所存放的Hash Key的检索。 如要检索到所有session,只需匹配 sessionid:* 即可。
- client.keys(‘session:*‘, function (err, keys) {
- console.log(keys)
- })
有些第三方库会支持检索值中的Hash Key,但这不是一个原子性操作,redis本身并不提供。
因此在采用Redis缓存与检索数据时,要使用一些独特的数据类型,如集合(Sets)
- > sadd myset 1 2 3 //添加 1 2 3到集合myset
- (integer) 3
- > smembers myset //列出集合的所有成员
- 1. 3
- 2. 1
- 3. 2
- > sismember myset 30 //判断30是否存在
- (integer) 0 //不存在
Redis集合不允许添加相同成员。多次添加同一元素到集合中最终只会包含一个元素。多个集合之间可以进行连接/交集这样的操作。从而实现类似传统数据库中索引、条件和连接查询的效果。
- # 添加 3 个用户和信息
- hmset user:1 user_name lee age 21
- hmset user:2 user_name david age 25
- hmset user:3 user_name chris age 25
- # 维护age索引
- sadd age:21 1
- sadd age:25 2 3
- # 维护name索引
- sadd name:lee 1
- sadd name:david 2
- sadd name:chris 3
- # 查找 age = 25 和 name = lee 的用户
- sinter age:25 name:lee
- -> 会返回一个空集合
将Session存放到Redis中
connect-reids 是一个 Redis 版的 session 存储器,使用node_redis作为驱动。借助它即可在Express中启用Redis来持久化你的Session.
安装
- $ npm install connect-redis
在 Express 3.x 中还需要安装express-session
- $ npm install express-session
参数
client 你可以复用现有的redis客户端对象, 由 redis.createClient() 创建 host Redis服务器名 port Redis服务器端口 socket Redis服务器的unix_socket
可选参数
ttl Redis session TTL 过期时间 (秒) disableTTL 禁用设置的 TTL db 使用第几个数据库 pass Redis数据库的密码 prefix 数据表前辍即schema, 默认为 “sess:”
使用
将express-session传给connect-redis来启用
- var session = require(‘express-session‘);
- var RedisStore = require(‘connect-redis‘)(session);
- app.use(session({
- store: new RedisStore(options),
- secret: ‘keyboard cat‘
- }));
检验
- app.use(function (req, res, next) {
- if (!req.session) {
- return next(new Error(‘oh no‘)) // handle error
- }
- next() // otherwise continue
- })
这样你的Session就转移到了Redis数据库,这样做的一个额外好处是,当你的Express服务器突然重启后,用户仍然可以使用当前Cookie中的SessionID从数据库中获取到他的会话状态,做到会话不丢失,在一定程度上提高网站的键壮性。
如果你的NodeJS网站上的所有缓存数据都转移到了Redis后,就可做到完全状态无关,按需扩展网站的规模。
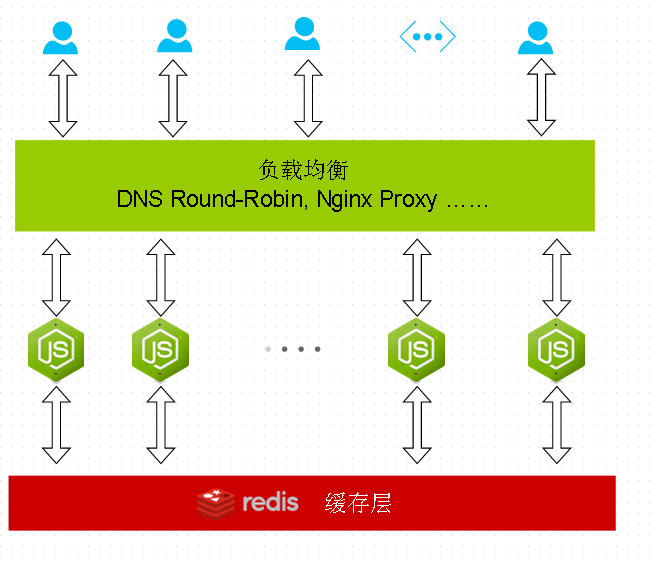
可水平扩展的NodeJS网站服务器集群(非 cluster模块
不同,它们是相互独立的,可分布在不同的物理服务器上),这样的架构,对于应对超大规模并发也是有好处的。
转自https://www.cnblogs.com/BlueKevin/p/5457788.html
在NodeJS中使用Redis缓存数据的更多相关文章
- 在springboot中使用redis缓存,将缓存序列化为json格式的数据
背景 在springboot中使用redis缓存结合spring缓存注解,当缓存成功后使用gui界面查看redis中的数据 原因 springboot缓存默认的序列化是jdk提供的 Serializa ...
- linux中的redis缓存服务器
Linux中的Redis缓存服务器 一.Redis基础部分: 1.redis介绍与安装比mysql快10倍以上 *****************redis适用场合**************** 1 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - 使用Redis缓存数据
上一篇文章(https://www.cnblogs.com/meowv/p/12943699.html)完成了项目的全局异常处理和日志记录. 在日志记录中使用的静态方法有人指出写法不是很优雅,遂优化一 ...
- NodeJS中的LRU缓存(CLOCK-2-hand)实现
转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 原文参考:https://www.codeproject.com/Articles/5299328/LRU- ...
- 4-11 CS后台项目-4 及 Redis缓存数据
使用Redis缓存数据 使用Redis可以提高查询效率,一定程度上可以减轻数据库服务器的压力,从而保护了数据库. 通常,应用Redis的场景有: 高频查询,例如:热搜列表.秒杀 改变频率低的数据,例如 ...
- Spring Boot 中集成 Redis 作为数据缓存
只添加注解:@Cacheable,不配置key时,redis 中默认存的 key 是:users::SimpleKey [](1.redis-cli 中,通过命令:keys * 查看:2.key:缓存 ...
- 使用redis缓存数据需要注意的问题以及个人的一些思考和理解
之前我有博客也尝试过使用redis,在实际的项目中确实作用挺大的.至少对于数据的频繁读取来说都起着至关重要的作用. 但是随着技术的学习,慢慢的业务要复杂起来,以后也许会用到redis集群,所以在这边查 ...
- Java项目中使用Redis缓存案例
缓存的目的是为了提高系统的性能,缓存中的数据主要有两种: 1.热点数据.我们将经常访问到的数据放在缓存中,降低数据库I/O,同时因为缓存的数据的高速查询,加快整个系统的响应速度,也在一定程度上提高并发 ...
- 微信小程序大型系统架构中应用Redis缓存要点
在大型分布式系统架构中,必须选择适合的缓存技术以应对高并发,实现系统相应的高性能,酷客多小程序经过慎重选型,选择了采用基于腾讯云服务的Redis弹性缓存技术,结合Redis官方推荐的.NET驱动类库S ...
随机推荐
- Usaco2008 Jan
[Usaco2008 Jan] https://www.luogu.org/problemnew/show/P2419 题目描述 N (1 ≤ N ≤ 100) cows, conveniently ...
- centos下Zabbix Agent端部署和安装
首先重复一下前面的规划 server端: 192.168.136.144 centos6.5 (虚拟机) agent端: 192.168.136.155 centos6.5( 虚拟 ...
- start_kernel之前的汇编代码分析
start_kernel之前的汇编代码分析 Boot中执行下面两句话之后,进入uclinux内核. theKernel = (void (*)(int, int, unsigned int))((ui ...
- Ember.NativeArray-原生数组
ember 2.18版本API翻译之Ember.NativeArray NativeArray mixin(混合类)包含使原生Array支持Ember.MutableArray 和其所有依赖API的属 ...
- C++ 容器类型成员
类型别名 iterator 此容器类型的迭代类型 const_iterator 可以读取元素,但不能修改元素的迭代器类型 size_type 无符号整数类型,足够保存此种容器类型最大可能容器的大小 ...
- 自学tensorflow——2.使用tensorflow计算线性回归模型
废话不多说,直接开始 1.首先,导入所需的模块: import numpy as np import os import tensorflow as tf 关闭tensorflow输出的一大堆硬件信息 ...
- 数据结构与算法之链表(LinkedList)——简单实现
这一定要mark一下.虽然链表的实现很简单,且本次只实现了一个方法.但关键的是例子:单向链表的反转.这是当年我去H公司面试时,面试官出的的题目,而当时竟然卡壳了.现在回想起来,还是自己的基本功不扎实, ...
- 简单的贝叶斯分类器的python实现
# -*- coding: utf-8 -*- ''' >>> c = Classy() >>> c.train(['cpu', 'RAM', 'ALU', 'io ...
- 爬虫-设置代理ip
1.为什么要设置代理ip 在学习Python爬虫的时候,经常会遇见所要爬取的网站采取了反爬取技术导致爬取失败.高强度.高效率地爬取网页信息常常会给网站服务器带来巨大压力,所以同一个IP反复爬取同一个网 ...
- 最具有性价比的语言javascript之介绍篇
虽然最近几年javascript很火.但很多程序员对javascript重视程度不够,所以对javascript的高级应用不甚了解.认为javascript仅仅只是一门脚本语言,作用就是表单验证,网页 ...