转载博客:rabbitmq
原文出处:http://www.cnblogs.com/sam-uncle/p/9202933.html
假设有这一些比较耗时的任务,按照上一次的那种方式,我们要一直等前面的耗时任务完成了之后才能接着处理后面耗时的任务,那要等多久才能处理完?别担心,我们今天的主角--工作队列就可以解决该问题。我们将围绕下面这个索引展开:
- 什么是工作队列
- 代码准备
- 循环分发
- 消息确认
- 公平分发
- 消息持久化
废话少说,直接展开。
一、什么是工作队列
工作队列--用来将耗时的任务分发给多个消费者(工作者),主要解决这样的问题:处理资源密集型任务,并且还要等他完成。有了工作队列,我们就可以将具体的工作放到后面去做,将工作封装为一个消息,发送到队列中,一个工作进程就可以取出消息并完成工作。如果启动了多个工作进程,那么工作就可以在多个进程间共享。
二、代码准备
- 生产者类:NewTask.java

public class NewTask {
//队列名称
public static final String QUEUE_NAME = "TASK_QUEUE";
//队列是否需要持久化
public static final boolean DURABLE = false; //需要发送的消息列表
public static final String[] msgs = {"task 1", "task 2", "task 3", "task 4", "task 5", "task 6"}; public static void main(String[] args) {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = null;
Channel channel = null; try {
// 1.connection & channel
connection = factory.newConnection();
channel = connection.createChannel(); // 2.queue
channel.queueDeclare(QUEUE_NAME, DURABLE, false, false, null); // 3.publish msg
for (int i = 0; i < msgs.length; i++) {
channel.basicPublish("", QUEUE_NAME, null, msgs[i].getBytes());
System.out.println("** new task ****:" + msgs[i]);
}
} catch (IOException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
} finally {
if (channel != null) {
try {
channel.close();
} catch (IOException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
} if (connection != null) {
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
} } }
} - 消费者类:Work.java
public class Work { public static void main(String[] args) {
System.out.println("*** Work ***");
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost"); try {
//1.connection & channel
final Channel channel = factory.newConnection().createChannel(); //2.queue
channel.queueDeclare(NewTask.QUEUE_NAME, NewTask.DURABLE, false, false, null); //3. consumer instance
Consumer consumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, BasicProperties properties,
byte[] body) throws IOException {
String msg = new String(body, "UTF-8");
//deal task
doWork(msg); }
}; //4.do consumer
boolean autoAck = true;
channel.basicConsume(NewTask.QUEUE_NAME, autoAck, consumer);
} catch (IOException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
} private static void doWork(String msg) {
try {
System.out.println("**** deal task begin :" + msg); //假装task比较耗时,通过sleep()来模拟需要消耗的时间
if ("sleep".equals(msg)) {
Thread.sleep(1000 * 60);
} else {
Thread.sleep(1000);
} System.out.println("**** deal task finish :" + msg);
} catch (InterruptedException e) {
e.printStackTrace();
}
} } - 再来一个消费者类:Work2.java,代码同Work.java一模一样。
三、循环分发
我们先启动Work和Work2,然后启动NewTask,运行结果如下:
NewTask运行结果:
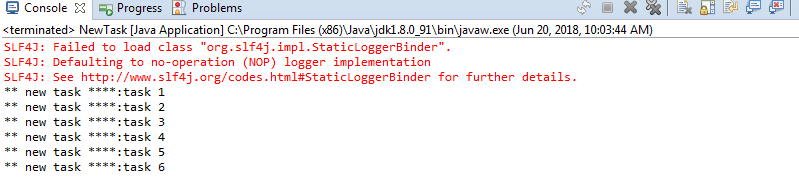
Work运行结果:
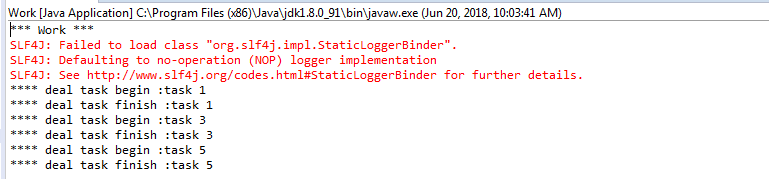
Work2运行结果:
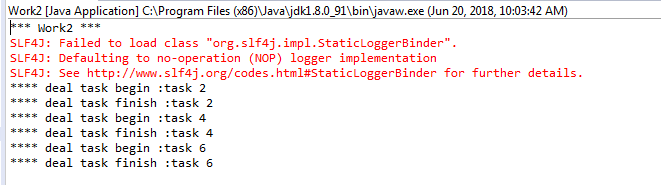
我们发现,消息生产者发送了6条消息,消费者work和work2分别分到了3个消息,而且是循环轮流分发到的,这种分发的方式就是循环分发。
四、消息确认
假如我们在发送的消息里面添加“sleep"
//需要发送的消息列表
public static final String[] msgs = {"sleep", "task 1", "task 2", "task 3", "task 4", "task 5", "task 6"};
根据代码中的实现,这个sleep要耗时1分钟,万一在这1分钟之内,工作进程崩溃了或者被kill了,会发生什么情况呢?根据上面的代码:
//4.do consumer
boolean autoAck = true;
channel.basicConsume(NewTask.QUEUE_NAME, autoAck, consumer);
自动确认为true,每次RabbitMQ向消费者发送消息之后,会自动发确认消息(我工作你放心,不会有问题),这个时候消息会立即从内存中删除。如果工作者挂了,那将会丢失它正在处理和未处理的所有工作,而且这些工作还不能再交由其他工作者处理,这种丢失属于客户端丢失。
我们来验证下,和刚才的步骤一样执行程序:
1.NewTask的控制台打印结果:
** new task ****:sleep
** new task ****:task 1
** new task ****:task 2
** new task ****:task 3
** new task ****:task 4
** new task ****:task 5
** new task ****:task 6 2.Work的控制台打印结果:
**** deal task begin :sleep 3.Work2的控制台打印结果:
**** deal task begin :task 1
**** deal task finish :task 1
**** deal task begin :task 3
**** deal task finish :task 3
**** deal task begin :task 5
**** deal task finish :task 5
根据上面的内容,消息生产者发送了7条消息, work2消费了1、3、5 三条,那剩下的sleep、2、4、6 这四条消息肯定是work来处理,只是sleep耗时一分钟 ,时间差后面的还没来得及处理,这个时候我们kill掉work,去看下RabbitMQ 管理页面,没有未处理的消息,消息随着work被kill也跟着丢失了。

是不是很可怕?
为了应对这种情况,RabbitMQ支持消息确认。消费者处理完消息之后,会发送一个确认消息告诉RabbitMQ,消息处理完了,你可以删掉它了。
代码修改(Work.java和Work2.java同步修改):1.将自动确认改为false,2.消息处理之后再通过channel.basicAck进行消息确认
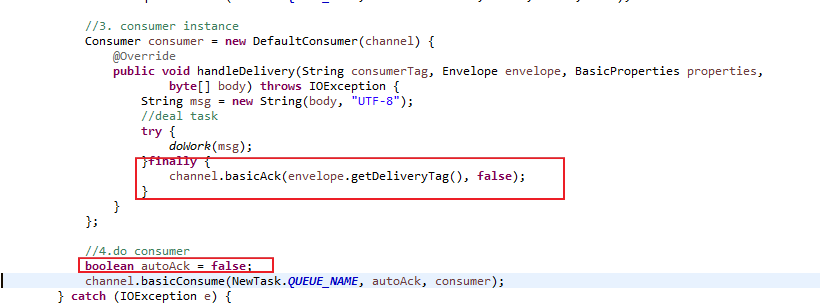
修改完后,执行程序:
1.NewTask的控制台打印结果:
** new task ****:sleep
** new task ****:task 1
** new task ****:task 2
** new task ****:task 3
** new task ****:task 4
** new task ****:task 5
** new task ****:task 6 2.Work的控制台打印结果:
**** deal task begin :sleep 3.Work2的控制台打印结果:
**** deal task begin :task 1
**** deal task finish :task 1
**** deal task begin :task 3
**** deal task finish :task 3
**** deal task begin :task 5
**** deal task finish :task 5
然后kill掉work,去看RabbitMQ管理页面,会发现有4条未确认:

再去看下work2的控制台,work2将work未处理完和未来得及处理的消息都给处理了:
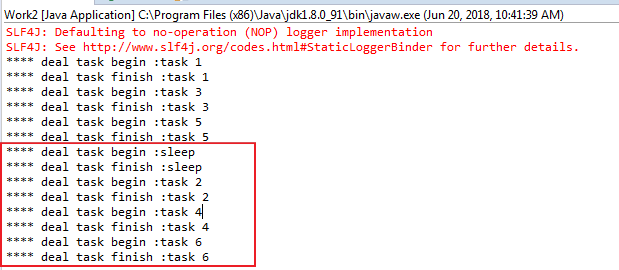
等work2处理完后,你再去看RabbitMQ管理页面,会发现页面的消息数值也都变成0 了。
五、公平分发
按照上面那种循环分发的方式,每个消费者会分到相同数量的任务,这样会有一个问题:假如有一些task非常耗时,之前的任务还没有完成,后面又来了那么多任务,来不及处理,那咋办? 有的消费者忙的不可开交,有的消费者却很快处理完事情然后无所事事浪费资源,那咋整?答案就是:公平分发。 怎么实现呢?
发生上述问题的原因就是RabbitMQ收到消息后就立即分发出去,而没有确认各个工作者未返回确认的消息数量。因此我们可以使用basicQos方法,并将参数prefetchCount设为1,告诉RabbitMQ 我每次值处理一条消息,你要等我处理完了再分给我下一个。这样RabbitMQ就不会轮流分发了,而是寻找空闲的工作者进行分发。
代码修改(work和Work2同步修改):

执行代码:
1.NewTask的控制台打印结果:
** new task ****:sleep
** new task ****:task 1
** new task ****:task 2
** new task ****:task 3
** new task ****:task 4
** new task ****:task 5
** new task ****:task 6 2.Work的控制台打印结果:
**** deal task begin :sleep
**** deal task finish :sleep 3.Work2的控制台打印结果:
**** deal task begin :task 1
**** deal task finish :task 1
**** deal task begin :task 2
**** deal task finish :task 2
**** deal task begin :task 3
**** deal task finish :task 3
**** deal task begin :task 4
**** deal task finish :task 4
**** deal task begin :task 5
**** deal task finish :task 5
**** deal task begin :task 6
**** deal task finish :task 6
Work只处理了sleep,Work2处理了1、2、3、4、5、6 这个六条消息。
六、消息持久化
上面说到消息确认的时候,提到了工作者被kill的情况。那如果RabbitMQ被stop掉了呢?我们来看下:
这次只启动Work和NewTask,不启动Work2,所有消息都交给Work来处理,控制台打印信息:
1.NewTask的控制台打印结果:
** new task ****:sleep
** new task ****:task 1
** new task ****:task 2
** new task ****:task 3
** new task ****:task 4
** new task ****:task 5
** new task ****:task 6 2.Work的控制台打印结果:
**** deal task begin :sleep
在work处理sleep的过程中,我们停掉RabbitMQ服务
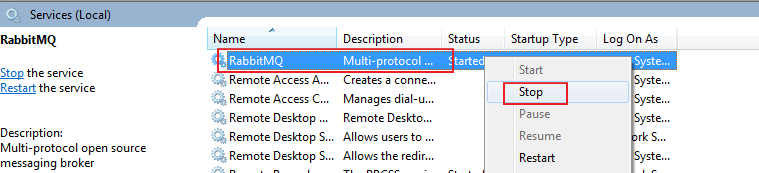
然后重新start服务并执行rabbitmq-plugins enable rabbitmq_management命令,然后查看管理页面:

你会发现,所有消息都将被清空了。这种丢失属于服务端丢失。
因此需要将消息进行持久化来应对这种情况。
持久化需要做两件事情:
- 队列持久化,在声明队列的时候,将第二个参数设为true


另外,由于RabbitMQ不允许重新定义已经存在的队列,否则就会报错(上一篇博客中已经提到过了),因此我们将这次的队列名改下:

- 消息持久化,在发送消息的时候,将第三个参数设为2

然后运行代码,在work处理sleep的时候将服务停掉,并重新启动且执行rabbitmq-plugins enable rabbitmq_management命令,然后查看管理页面:

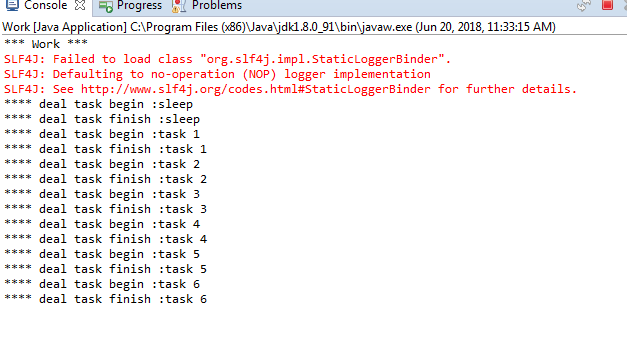
一共7条消息,未确认的1条(sleep)和ready的6条(1、2、3、4、5、6)。消息被保存了下来。
重新启动Work,所有消息被消费:

转载博客:rabbitmq的更多相关文章
- 转载博客(Django2.0集成xadmin管理后台遇到的错误)
转载博客地址:https://blog.csdn.net/yuezhuo_752/article/details/87916995 django默认是有一个admin的后台管理模块,但是丑,功能也不齐 ...
- Swift中可选类型(Optional)的用法 以及? 和 ! 的区别 (转载博客,知识分享)
本文转载自:代码手工艺人的博客,原文名称:Swift之 ? 和 ! Swift语言使用var定义变量,但和别的语言不同,Swift里不会自动给变量赋初始值,也就是说变量不会有默认值,所以要求使用变量之 ...
- python处理转载博客html
前景 在转载别人博客的时候通常我们会通过复制html然后放到编辑器里面, 但是通常html里有很多杂七杂八的东西, 比如script, svg这些标签导致排版出现问题 例如由lu标签引起的 由svg标 ...
- logging模块转载博客
转载自:http://blog.csdn.net/zyz511919766/article/details/25136485 简单将日志打印到屏幕: [python] view plain copy ...
- 转载CSDN博客步骤
在参考“如何快速转载CSDN中的博客”后,由于自己不懂html以及markdown相关知识,所以花了一些时间来弄明白怎么转载博客,以下为转载CSDN博客步骤和一些知识小笔记. 参考博客原址:http: ...
- CSDN怎么转载别人的博客
在参考"如何快速转载CSDN中的博客"后,由于自己不懂html以及markdown相关知识,所以花了一些时间来弄明白怎么转载博客,以下为转载CSDN博客步骤和一些知识小笔记. 参考 ...
- CSDN怎么一键转载别人的博客
在参考"如何快速转载CSDN中的博客"后,由于自己不懂html以及markdown相关知识,所以花了一些时间来弄明白怎么转载博客,以下为转载CSDN博客步骤和一些知识小笔记. 参考 ...
- 如何快速转载CSDN中的博客
看到一篇<如何快速转载CSDN中的博客>,介绍通过检查元素→复制html来实现快速转载博客的方法.不过,不知道是我没有领会其精神还是其他原因,测试结果为失败.
- paper 61:计算机视觉领域的一些牛人博客,超有实力的研究机构等的网站链接
转载出处:blog.csdn.net/carson2005 以下链接是本人整理的关于计算机视觉(ComputerVision, CV)相关领域的网站链接,其中有CV牛人的主页,CV研究小组的主页,CV ...
随机推荐
- 《Linux内核精髓:精通Linux内核必会的75个绝技》一HACK #20 使用fio进行I/O的基准测试
HACK #20 使用fio进行I/O的基准测试 本节介绍使用fio进行模拟各种情况的I/O基准测试的操作方法.I/O的基准测试中有无数需要考虑的因素.是I/O依次访问还是随机访问?是通过read/w ...
- web本质
知识内容: 1.网络协议复习 2.模拟web 3.web本质总结 参考: http://www.cnblogs.com/wupeiqi/articles/5237672.html http://www ...
- Redis 在 LINUX 系统下 安装, 启动
01, 下载 http://www.redis.cn/ , 这里下再下来的是 redis-4.0.1.tar.gz 这个压缩包 02, 将压缩包放到 linux 系统中, 一般放在 usr/lo ...
- springMVC之Interceptor拦截器
转自:https://blog.csdn.net/qq_25673113/article/details/79153547 Interceptor拦截器用于拦截Controller层接口,表现形式有点 ...
- CategoryPanelGroup动态生成节点
afw TCategoryPanel *cp; ; i < TreeView1->Items->Count; i++) { ) { cp = new TCategoryPanel(C ...
- DNS配置注意事项 正在连接网络
故障现象 公司规模不是很大,大概有50多台计算机,购买了两台IBM服务器.由于内部使用的某个应用软件需要Windows域的支持,所以在这两台IBM服务器上启用了windows 2000 Server的 ...
- 反射(hasattr , getattr, setattr) 输入的字符串用来运行程序
当用户输入字符串时,不能够用来运行程序 1.使用 hasattr 找出输入的字符串是否在程序内 2.使用 getattr 返回找出字符串对应的函数的内存地址或者变量 3. 使用setattr 添加新的 ...
- centos sendmail 启动慢
from:http://www.cnblogs.com/kerrycode/p/4717498.html 在 CentOS release 6.6 上启动sendmail服务时发现服务启动过程非常慢, ...
- git创建仓库,并提交代码(第一次创建并提交)(转)
一直想学GIT,一直不曾学会.主要是GUI界面的很少,命令行大多记不住.今天尝试提交代码,按GIT上给的方法,没料到既然提交成功了. 于是把它记下来,方便以后学习. 代码是学习用的,没多大意义: 下图 ...
- tnsping 命令解析
C:\Users\nowhill>tnsping jljcz Oracle Net 工具(命令)tnsping,是一个OSI会话层的工具,它用来: 1)验证名字解析(name resolutio ...