flume安装配置
1 下载安装包并解压
下载地址:http://flume.apache.org/download.html
解压:tar zxvf apache-flume-1.8.0-bin.tar.gz
2 配置环境变量
vi ~/.bashrc
配置环境变量:
export FLUME_HOME=/hmaster/flume/apache-flume-1.8.0-bin
export FLUME_CONF_DIR=$FLUME_HOME/con
export PATH=$PATH:$FLUME_HOME/bin
让配置生效
source ..bashrc
配置flume-env.sh文件的JavaHome
export JAVA_HOME=/hmaster/javaenv/jdk1.8.0_181
3 Flume部署示例
1 Avro
在/hmaster/flume/apache-flume-1.8.0-bin/conf目录下新建netcat.conf配置文件
Flume可以通过Avro监听某个端口并捕获传输的数据,具体配置示例如下:
#那么我们也给这个三个组件分别取名字
a2.sources = r1
a2.channels = c1
a2.sinks = k1
#定义具体的source内容
#这里是执行命令以及下面对应的具体命令
#这个命令执行后的数据返回给这个source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
#定义具体的channel信息
#我们source定义好了,就要来定义我们的channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 10000
a2.channels.c1.transactionCapacity = 100
#定义具体的sink信息
#这个logger sink,就是将信息直接打印到控制台
#就是打印日志
a2.sinks.k1.type = logger
#最后来组装我们之前定义的channel和sink
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
运行FlumeAgent,监听本机的44444端口
-n 后面对应agent名称
-c 配置文件目录
-f 配置文件地址
flume-ng agent -n a1 -c conf -f ../conf/netcat.conf

// 打开另一终端,通过telnet登录localhost的44444,输入测试数据
$ telnet localhost 44444
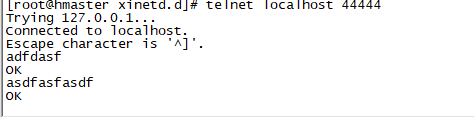
// 查看flume收集数据情况

2 Spool
1 配置spool.conf用于监控目录userlogs 的文件,将文件内容发送到本地60000端口
Spool用于监测配置的目录下新增的文件,并将文件中的数据读取出来。需要注意两点:拷贝到spool目录下的文件不可以再打开编辑、spool目录下不可包含相应的子目录。具体配置文件示例如下
#定义agent名称,source,channel,sink的名称
#a1就是我们给agent起的名字,我们知道有多个agent,那么我们就是通过这个来进行区别
#我们知道agent包含了三个重要的组件,有source,channel,sink
#那么我们也给这个三个组件分别取名字
a2.sources = r1
a2.channels = c1
a2.sinks = k1
#定义具体的source内容
#这里是执行命令以及下面对应的具体命令
#这个命令执行后的数据返回给这个source
a2.sources.r1.type = spooldir
a2.sources.r1.spoolDir = /home/hadoop/hadoop-2.9.0/userlogs
#定义具体的channel信息
#我们source定义好了,就要来定义我们的channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 10000
a2.channels.c1.transactionCapacity = 100
#定义具体的sink信息
#就是将数据转换成Avro Event 然后发送到配置的rpc端口上
a2.sinks.k1.type = avro
a2.sinks.k1.hostname= localhost
a2.sinks.k1.port= 60000
#最后来组装我们之前定义的channel和sink
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
2 配置spool2.conf用于从本地60000端口获取数据并写入HDFS
#定义agent名称,source,channel,sink的名称
a3.sources = r1
a3.channels = c1
a3.sinks = k1
#定义具体的source内容
a3.sources.r1.type= avro
a3.sources.r1.bind= localhost
a3.sources.r1.port= 60000
#定义具体的channel信息
#我们source定义好了,就要来定义我们的channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 10000
a3.channels.c1.transactionCapacity = 100
#定义具体的sink信息
a3.sinks.k1.type = hdfs
a3.sinks.k1.hdfs.path = hdfs://192.168.79.2:9000/flume/event2
a3.sinks.k1.hdfs.filePrefix = events-
a3.sinks.k1.hdfs.fileType = DataStream
#最后来组装我们之前定义的channel和sink
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1
flume安装配置的更多相关文章
- Flume篇---Flume安装配置与相关使用
一.前述 Copy过来一段介绍Apache Flume 是一个从可以收集例如日志,事件等数据资源,并将这些数量庞大的数据从各项数据资源中集中起来存储的工具/服务,或者数集中机制.flume具有高可用, ...
- 具体图解 Flume介绍、安装配置
写在前面一: 本文总结"Hadoop生态系统"中的当中一员--Apache Flume 写在前面二: 所用软件说明: 一.什么是Apache Flume 官网:Flume is a ...
- Flume简介与使用(一)——Flume安装与配置
Flume简介与使用(一)——Flume安装与配置 Flume简介 Flume是一个分布式的.可靠的.实用的服务——从不同的数据源高效的采集.整合.移动海量数据. 分布式:可以多台机器同时运行采集数据 ...
- flume安装及配置
Flume安装 介绍 Flume本身的安装比较简单(flume的介绍请参考http://blog.csdn.net/rzhzhz/article/details/7448633),安装前先说明几个概念 ...
- 01 Flume系列(一)安装配置
01 Flume系列(一)安装配置 Flume(http://flume.apache.org/) is a distributed, reliable, and available service ...
- CentOS6安装各种大数据软件 第七章:Flume安装与配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 3.flume安装以及环境配置
1.安装jdk 我这里已经安装过了,这里就不演示了 2.安装flume 安装cdh版本的,http://archive.cloudera.com/cdh5/cdh/5/ 安装完毕之后,配置环境变量. ...
- FLUME安装&环境(一):netcat类型配置
1.下载软件 在 /opt/deploy 下新建 flume 文件夹: # mkdir / opt/deploy / flume 到Flume官网上http://flume.apache.org/do ...
- Linux安装配置Flume
概述 Apache Flume是一个分布式,可靠且可用的系统,用于高效地收集,汇总和将来自多个不同源的大量日志数据移动到集中式数据存储.Apache Flume的使用不仅限于日志数据聚合.由于数据源是 ...
随机推荐
- Java final类&所有构造方法均为private的类(类型说明符&访问控制符)
1. final是类型说明符,表示关闭继承,即final类不能有子类: 但final类可能可以在类外创建对象(即final类的构造方法可以不是private型): 在同一包中时,可以在任何另外一个类中 ...
- [Oracle][DATAGUARD] LOGICAL STANDBY环境里,有些SEQUENCE无法应用,导致Primary和Standby无法同期
今天遇到了一个客户,问题是这样的,客户构筑了一个RACtoRAC的 LOGICAL STANDBY环境.并用EM在监视同期情况,发现EM页面上55115和55116这两个SEQUENCE一直在应用. ...
- Git 转载
我每天使用 Git ,但是很多命令记不住. 一般来说,日常使用只要记住下图6个命令,就可以了.但是熟练使用,恐怕要记住60-100个命令. 下面是我整理的常用 Git 命令清单.几个专用名词的译名如下 ...
- asp类型转换函数汇总 转贴
abs(number) 返回绝对值. array(arglist) 创建一个数组. asc(string) 返回字符串第一个字符的ansi码. atn(number) 返回反正弦值. cbool (e ...
- selenium中下拉框的定位
from selenium import webdriverfrom selenium.webdriver.support.select import Selectimport timedriver ...
- 从输入URL按下回车到页面展现,中间发生了什么?
从输入URL按下回车到页面展现,总的来说发生了一下几个过程: DNS 解析:将域名解析成 IP 地址 TCP 连接:TCP 三次握手 发送 HTTP 请求 服务器处理请求并返回 HTTP 报文 浏览器 ...
- 命令行窗口中使用pip安装第三方库成功之后,在pycharm中仍不能使用
在学习廖老师的Python教程的时候,遇到命令行窗口中使用pip安装第三方库成功之后,在pycharm中仍不能使用的情况, 这种情况可能是由于在本地安装了多个Python版本的缘故(只是可能的情况之一 ...
- Some notes in Stanford CS106A(2)
1.Local variable(local) ex. int i = 0; factorial(i); the "i" outside the method factorial( ...
- C#字符串的CompareTo比较,让我疑惑的地方
在学习选择排序算法的时候,用到CopareTo方法.由于比较的数字,是自己随意输入的. 当我输入字符串“8”,它和字符串“16”比较时候. string str1 = "8"; s ...
- Microsoft宣布为Power BI提供AI模型构建器,关键驱动程序分析和Azure机器学习集成
微软的Power BI现在是一种正在大量结合人工智能(AI)的商业分析服务,它使用户无需编码经验或深厚的技术专长就能够创建报告,仪表板等.近日西雅图公司宣布推出几款新的AI功能,包括图像识别和文本分析 ...