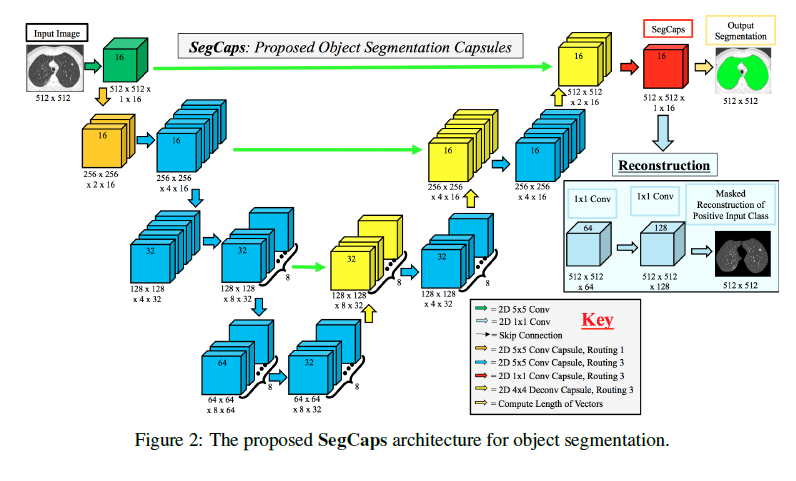
Capsules for Object Segmentation(理解)
0 - 背景
今年来卷积网络在计算机视觉任务上取得的显著成果,但仍然存在一些问题。去年Hinton等人提出了使用动态路由的新型网络结构——胶囊网络来解决卷积网络的不足,该新型结构在手写体识别以及小图像分类上取得了不错的效果。其成功的原因在于它使用了动态路由算法替代了卷积网络中的池化层从而减少了信息的丢失并且允许捕捉数据中的部分-整体关系,同时,使用胶囊作为网络的基本单位替代了神经元,从而使得网络可以学习除了特征之外的更多的信息(如空间角度、大小量级、特征提取的其它属性等)。
基于胶囊网络的初步成功,我们第一次将其应用到图像分割任务上,改进动态路由算法从而减少了参数,并且构造新的结构使得胶囊网络具备了处理大图片的能力。
1 - 贡献
- 第一次在会议上提出将胶囊网络应用在目标分割上面
- 在原先的动态路由算法上提出了两个改进
- 子胶囊只能在一个定义的本地窗口路由到父胶囊
- 网络中同一类型的胶囊的转换矩阵共享
- 可以处理大尺度图片(512×512),之前的胶囊网络结构最大处理32×32大小的图片
- 我们介绍了“deconvolutional”胶囊的概念并且提出了一个新颖的deep convolutional-deconvolutional胶囊网络架构
- SegCaps在LIDC-IDRI数据集的LUNA16子集上的肺部分割效果有所提升
2 - 整体思路
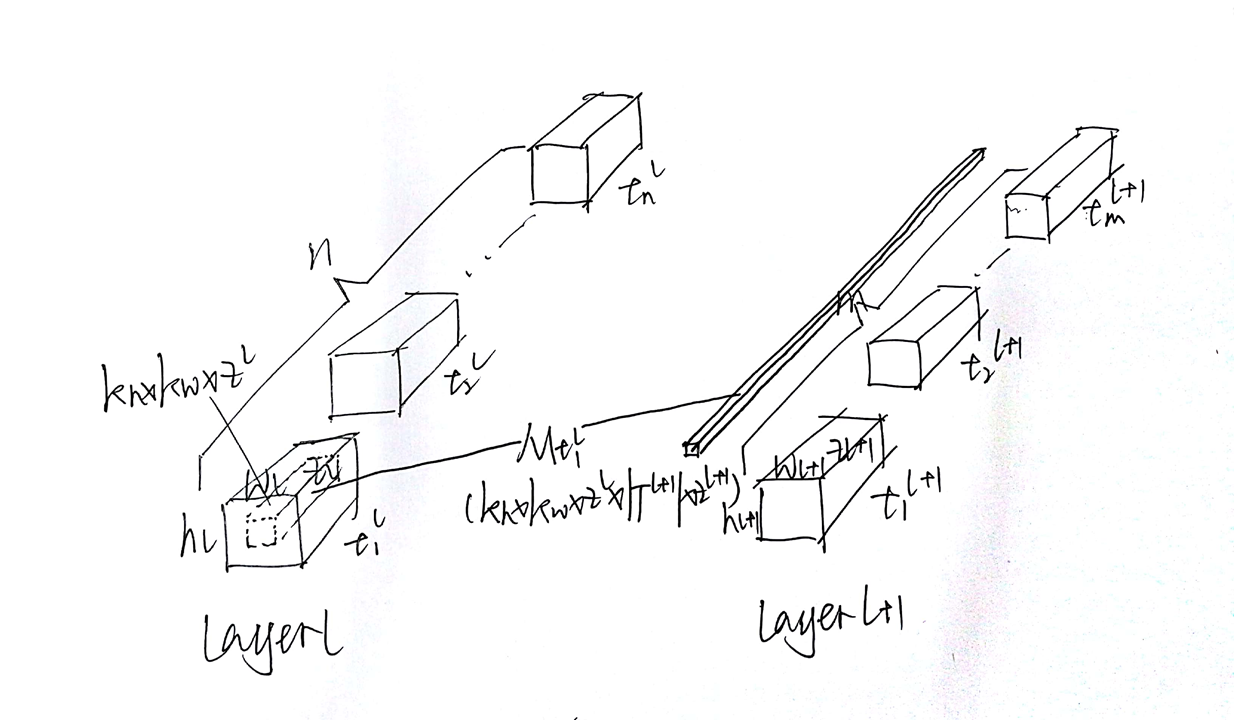
2.1 - 动态路由算法改进
Hinton提出的原始的胶囊网络中,胶囊间的路由相当于做一个全连接映射,每一条路由路径都需要上一层胶囊和下一层胶囊的所有维度的全连接映射,从而使得参数量特别大,可以用如下图解直观解释。

而这篇论文中,作者提出在映射的时候,通过窗口控制和同一胶囊(同一类型胶囊)共享权重的方法,减少参数,其实可以理解为,在底层的每一个胶囊内做卷积,每一个胶囊都卷出与高层的所有胶囊维度相同的张量,而后对于每一个底层胶囊卷出来的结果做路由选择(更新耦合系数$c_{ij}$),通过下图进行直观理解。
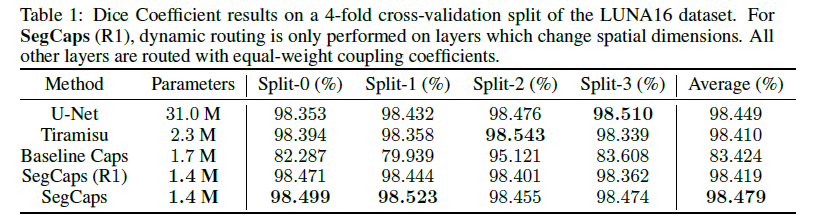
3 - 实验
参数少,效果好!
4 - 结论
- 提出了用于目标分割的新颖的深度学习模型——SegCaps,在具有挑战性的肺部CT图像分割数据集上效果很好(参数少,效果好)
- 改进了胶囊网络原本的动态路由算法使得参数量大大较少并且增大了允许接受的输入图片的尺度
- 提出胶囊反卷积层,从而构造新颖的胶囊卷积-胶囊反卷积的架构
- 扩展了目标类的掩码重构作为分割问题的正则化策略
5 - 参考资料
https://github.com/lalonderodney/SegCaps(论文源码)
Capsules for Object Segmentation(理解)的更多相关文章
- 论文笔记:Capsules for Object Segmentation
Capsules for Object Segmentation 2018-04-16 21:49:14 Introduction: ----
- java 多线程 Synchronized方法和方法块 synchronized(this)和synchronized(object)的理解
synchronized 关键字,它包括两种用法:synchronized 方法和 synchronized 块. 1. synchronized 方法:通过在方法声明中加入 synchronized ...
- PaperNotes Instance-Level Salient Object Segmentation
title: PaperNotes Instance-Level Salient Object Segmentation comments: true date: 2017-12-20 13:53:1 ...
- 64.root object的理解
一.root object的理解 就是某个type对应的mapping json,包括properties,metadata(_id,_source,_type),settings(analy ...
- 泡泡一分钟:SceneCut: Joint Geometric and Object Segmentation for Indoor Scenes
张宁 SceneCut: Joint Geometric and Object Segmentation for Indoor Scenes "链接:https://pan.ba ...
- 关于six.with_metaclass(ABCMeta, object)的理解
在学习Python过程中,看到了生成虚基类的方式, class PeopleBase(six.with_metaclass(ABCMeta, object)): @abstractmethod def ...
- [CVPR2017]Online Video Object Segmentation via Convolutional Trident Network
基于三端卷积网络的在线视频目标分割 针对半监督视频目标分割任务,作者采取了和MaskTrace类似的思路,以optical flow为主. 本文亮点在于: 1. 使用共享backbone,三输出的自编 ...
- 论文阅读笔记二十四:Rich feature hierarchies for accurate object detection and semantic segmentation Tech report(R-CNN CVPR2014)
论文源址:http://www.cs.berkeley.edu/~rbg/#girshick2014rcnn 摘要 在PASCAL VOC数据集上,最好的方法的思路是将低级信息与较高层次的上下文信息进 ...
- Fully Convolutional Networks for semantic Segmentation(深度学习经典论文翻译)
摘要 卷积网络在特征分层领域是非常强大的视觉模型.我们证明了经过端到端.像素到像素训练的卷积网络超过语义分割中最先进的技术.我们的核心观点是建立"全卷积"网络,输入任意尺寸,经过有 ...
随机推荐
- 【技术说明】iOS10来了,AppCan已全面适配!
IPhone 7出了,你的肾还好吗?别紧张,不买肾7,同样可以体验最新的iOS10! AppCan对引擎.插件.编译系统等都进行了重要升级,让你的APP轻松适配iOS10!具体如何,请往下看! 引擎 ...
- 【续】5年后,我们为什么要从 Entity Framework 转到 Dapper 工具?
前言 上一篇文章收获了 140 多条评论,这是我们始料未及的. 向来有争议的话题都是公说公的理,婆说婆的理,Entity Framework的爱好者对此可以说是嗤之以鼻,不屑一顾,而Dapper爱好者 ...
- 特殊需求:EF 6.x如何比较TimeSpan格式的字符串?EF Core实现方式是否和EF 6.x等同?
前言 我们知道C#中的TimeSpan对应SQL Server数据库中的Time类型,但是如果因为特殊需求数据库存储的不是Time类型,而是作为字符串,那么我们如何在查询数据时对数据库所存储的字符串类 ...
- 随心测试_软测基础_005 <测试人员工作内容>
接上篇:清楚了_测试人员的工作职责范围,那每项 测试活动的具体工作内容有哪些呢? Q1:如何理解测试工程师的工作内容? A1:SX的观点:综合一体化 现如今互联网行业如何哪达,每一项IT职业的工作职责 ...
- iview 将table的selection多选变单选方法
相信很多使用iview的朋友,在用到table,都会遇到需要使用selection的场景,但是总会有那么一个产品汪,觉得iview的单选效果不好,非要用selection的来做单选,那么下面这个方法就 ...
- (light oj 1319) Monkey Tradition 中国剩余定理(CRT)
题目链接:http://lightoj.com/volume_showproblem.php?problem=1319 In 'MonkeyLand', there is a traditional ...
- MarkDownPad2基本语法
一.换行和空格 (1)换行 行尾加两个空格 (2)空格 二.标题 在#后跟个空格再写文字,一个#是一级标题,两个#是二级标题,以此类推,支持六级标题. 示例: # 一级标题 ...
- http请求方式和传递数据类型
HTTP(HyperText Transfer Protocol)是一套计算机通过网络进行通信的规则. GET,通过请求URI得到资源 POST,用于添加新的内容 PUT用于修改某个内容 DELETE ...
- Fetch API & Async Await
Fetch API & Async Await const fetchJSON = (url = ``) => { return fetch(url, { method: "G ...
- 2019春招面试高频题(Java版),持续更新(答案来自互联网)
第一模块--并发与多线程 Java多线程方法: 实现Runnable接口, 继承thread类, 使用线程池 操作系统层面的进程与线程(对JAVA多线程和高并发有了解吗?) 计算机资源=存储资源+计算 ...